
大家好,我是肆〇柒。在 AI 领域,大型语言模型(LLM)基础智能体正逐渐成为解决复杂交互任务的关键力量。然而,一个不容忽视的问题是:尽管它们在训练中见过的任务上表现出色,但面对未见过的新任务时,泛化能力却往往不尽人意。这就好比一个学生在题海战术中刷过的题目上能拿高分,但面对新题目时却无从下手。所以,为了提升智能体的泛化能力,研究者们提出了众多方法,其中 AgentRM 以其独特视角和创新机制,让我看到了通用奖励模型的一种可能。这是出自清华大学今年 2 月发表的一篇研究论文《AgentRM: Enhancing Agent Generalization with Reward Modeling》。3 月的时候我已看过一遍,因刚结束不久的智源大会提及,所以,我又过了一遍这篇论文,今天和大家一起再重温一下。
刚才,在文章开头,我们就提到基础智能体泛化能力不足的问题。现有智能体大都经过多任务微调,通过接触多样化任务来提升泛化性。然而,这种方式并非一劳永逸。多任务微调虽能在一定程度上扩展智能体的能力边界,却也存在明显局限性。一方面,随着任务数量的增加,微调过程变得愈发复杂,模型容易陷入过拟合困境,对训练中见过的任务愈发熟练,对未见过的任务却依然无能为力。另一方面,不同任务间的数据分布和特征差异,可能导致智能体在学习新任务时遗忘之前掌握的任务模式,陷入 “负迁移” 的尴尬境地。而微调奖励模型可能会带来另外一种收益。
下图清晰地展示了微调奖励模型,相较于微调策略模型在智能体任务中的更鲁棒性能。其中,(a)显示了微调策略模型会导致未见任务性能严重下降;b)和(c)分别展示了使用奖励模型进行 Best-of-5 采样时,在微调策略模型和微调奖励模型后的性能表现,对比鲜明地揭示了微调奖励模型的优势。
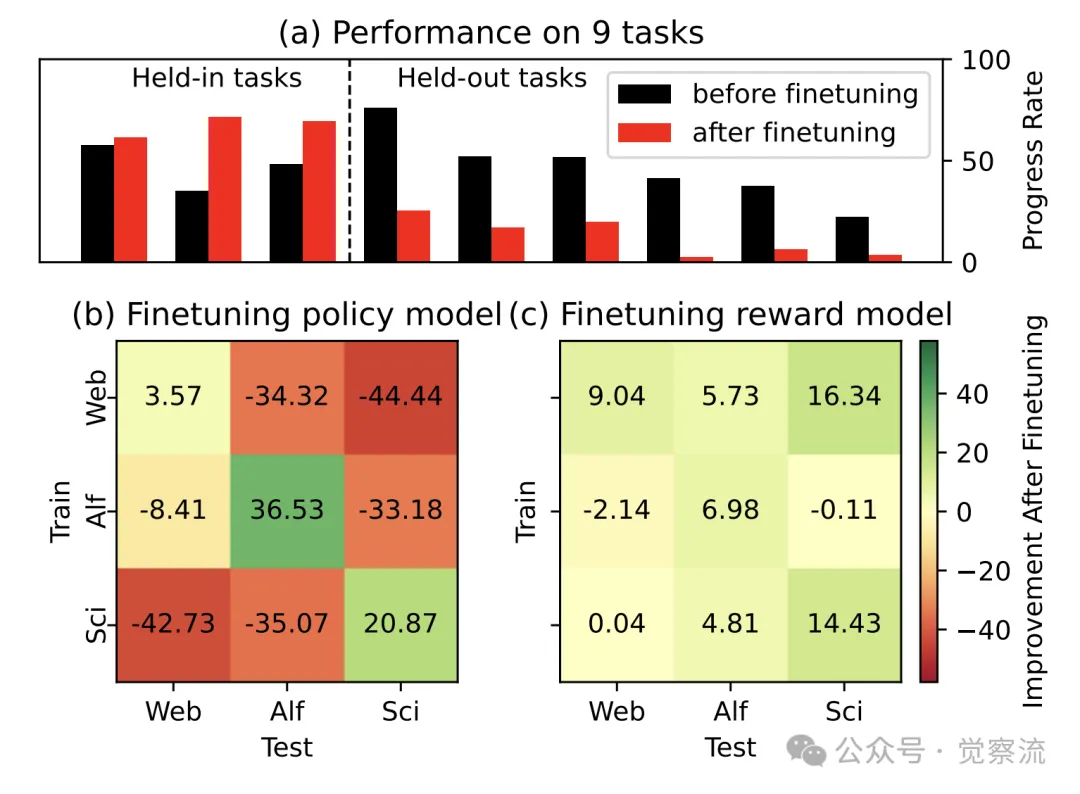
在智能体任务中,对奖励模型进行微调比对策略模型进行微调会更加稳健
AgentRM 方法论
行为克隆:搭建智能体的 “起跑线”
在 AgentRM 的方法体系中,行为克隆是构建初始策略模型的关键步骤,为后续的奖励建模和智能体优化奠定了坚实基础。研究者们从海量的训练集中精心筛选出一部分具有代表性的任务指令,这些指令覆盖了智能体需要掌握的核心技能和典型场景。随后,借助专家智能体的精准标注,对这些任务指令进行高质量的示范演绎,生成一系列专家轨迹。这些轨迹犹如经验丰富的导师亲手书写的 “标准答案”,为智能体的学习提供了明确的方向和参照。
基于这些专家轨迹,研究者们采用监督微调(SFT)技术,对初始策略模型进行针对性训练。在训练过程中,模型通过反复观摩专家轨迹中的决策逻辑和行动模式,逐渐学会了在不同场景下如何做出合理的选择。这一过程就像是智能体在进行一场场高强度的 “模拟考试”,在不断的练习和纠正中,逐步掌握了基础的任务解决能力。最终,经过监督微调的初始策略模型 πinit 脱颖而出,它具备了扎实的基本功,能够应对训练集中常见的任务类型,并为后续的探索和优化积累了宝贵的经验,为智能体在复杂多变的任务环境中脱颖而出做好了准备。
奖励建模:解锁智能体泛化的 “秘钥”
下图向我们展示了 AgentRM 方法的总体框架。包括通过行为克隆(SFT)在专家轨迹上导出初始策略模型;利用初始策略模型探索环境构建搜索树;从搜索树中提取状态 - 奖励对训练通用奖励模型;以及在推理阶段,使用奖励模型指导策略模型的决策过程,无论策略模型的初始强度如何,都能增强其决策能力。
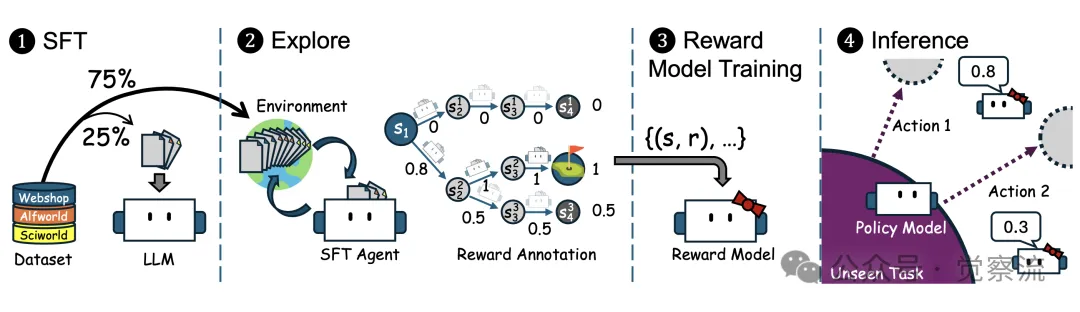
概述:❶ 基于专家轨迹训练一个监督式微调(SFT)智能体;❷ 使用SFT智能体探索环境,构建搜索树;❸ 在从搜索树中提取的状态-奖励对上训练一个可泛化的奖励模型;❹ 无论初始策略模型的强度如何,通过奖励模型引导的测试时搜索来增强策略模型,以应对未见过的任务,例如具身规划、文字游戏、工具使用等
显式奖励建模 —— 精准的 “导航仪”
显式奖励建模是 AgentRM 的核心创新之一,它借助树搜索技术,为智能体的每一步行动都赋予了清晰明确的奖励信号,就像为智能体配备了一个高精度的导航仪,使其在复杂任务的 “迷宫” 中也能精准定位方向。
在这一方法中,研究者们将智能体的搜索轨迹构建为树状结构,每个节点代表智能体在特定状态下的决策点,每条边则表示智能体采取的具体行动。从初始状态开始,智能体依据当前策略模型,在策略模型的引导下逐步扩展搜索树。在每一次扩展过程中,智能体都会从当前节点出发,基于策略模型随机采样多个可能的行动,并预估这些行动可能导致的后续状态。为了避免重复探索,节省计算资源,算法采用了蒙特卡洛树搜索(MCTS)的策略,通过计算 Upper Confidence Bound(UCB)值来选择最具潜力的节点进行扩展。
当搜索树逐步构建完成后,研究者们从树中提取每个状态对应的价值估计 V(st),并以此为基础构建奖励模型的训练数据集。在模型训练阶段,一个带有价值预测头的语言模型被用来拟合这些状态 - 价值对。通过最小化预测值与真实值之间的均方误差(MSE),模型逐渐学会了如何准确评估智能体在不同状态下所采取行动的好坏优劣。这种基于显式奖励建模的方法,能够将稀疏的结果奖励合理分配到任务的每一步,还能让智能体在执行任务的过程中实时获得反馈,从而及时调整策略,优化决策路径。
显式奖励建模 的核心在于通过树搜索构建一个全面且精细的状态价值估计体系。这一过程要求模型能够准确预测每个状态的潜在价值,还要求模型能够在不同状态之间建立有效的关联,从而形成一个连贯的价值网络。例如,在处理复杂的网页导航任务时,智能体需要理解不同网页元素之间的关系以及用户可能的交互意图。通过对这些元素和意图的综合评估,显式奖励建模能够为智能体提供明确的行动指引,使其能够高效地完成任务目标。
此外,显式奖励建模在处理具有长期依赖关系的任务时展现出独特的优势。例如,在科学实验模拟任务中,智能体需要根据一系列连续的实验步骤和观察结果来调整后续的实验操作。显式奖励建模通过构建一个动态的价值估计网络,能够捕捉到这些长期依赖关系,并为智能体提供及时且准确的反馈,从而帮助智能体在复杂的实验环境中做出最优决策。
隐式奖励建模 —— 深藏不露的 “智慧源泉”
相较于显式奖励建模的直观与透明,隐式奖励建模则更像是一位深藏不露的智者,它不依赖于外部的标注信息,而是通过挖掘策略模型自身的优势函数,巧妙地推导出过程奖励。
在隐式奖励建模中,过程奖励被定义为优势(Advantage),即智能体在某个状态下采取特定行动相较于其他行动所能带来的额外收益。具体一点,结果奖励被参数化为策略模型和参考模型的对数似然比,通过数学归纳法,研究者们证明了 Q 值(即从当前状态开始,采取特定行动后所能获得的期望累积奖励)可以在策略模型的训练过程中被隐式地学习到。基于此,过程奖励可以通过相邻时间步的 Q 值之差来计算得出。
在实际操作中,对于每个任务指令,研究者们会通过策略模型采样多条完整轨迹,并利用这些轨迹构建训练数据集。随后,一个语言模型被训练用来预测这些轨迹中每个状态的优势值。与显式奖励建模不同的是,这里采用的是均方误差(MSE)损失函数来衡量预测值与真实值之间的差距,而非像某些传统方法那样使用交叉熵损失。这种隐式奖励建模方法的优势在于,它无需额外的标注成本,能够充分利用策略模型自身的特性,挖掘出隐藏在数据背后的奖励信号,为智能体的优化提供了一种高效且经济的途径。
隐式奖励建模 的独特之处在于其对策略模型内部信息的深度挖掘。通过分析策略模型的优势函数,隐式奖励建模能够揭示出智能体在不同状态下的潜在行动价值,而无需依赖外部的标注信息。这种方法在处理具有高度不确定性和多样性的任务时表现出色。例如,在处理用户生成内容的审核任务时,智能体需要对各种复杂的文本内容进行快速且准确的评估。隐式奖励建模通过分析策略模型在不同文本片段上的表现,能够为智能体提供一个内在的评估标准,帮助其在面对新内容时做出合理的决策。
另外,隐式奖励建模在多任务学习场景中具有显著的优势。由于它不依赖于任务特定的标注信息,因此能够更灵活地适应不同类型的任务需求。例如,在同时处理网页导航和文本游戏任务时,智能体可以利用隐式奖励建模从一个任务中学习到的知识迁移到另一个任务中,从而提高其在多个任务上的整体性能。
LLM-as-a-judge —— 随时随地的 “裁判”
除了上述两种基于模型训练的奖励建模方法外,AgentRM 还创造性地引入了 LLM-as-a-judge 这一独特的训练免费奖励模型。这种方法跳出了传统奖励建模依赖复杂训练过程的框架,直接借助大型语言模型的强大语言理解和推理能力,对智能体的行动轨迹进行即时评估,就像一位随时随地可用的智能裁判。
在实际应用中,研究者们精心设计了一系列提示指令,将 LLM 打造成一个轨迹奖励模型。当需要对智能体的行动轨迹进行评估时,首先向 LLM 提供详细的任务描述和目标,使其对任务要求有清晰的认识。接着,将多个候选轨迹呈现给 LLM,让 LLM 对这些轨迹进行对比分析。最后,通过强制 LLM 调用特定的函数,从多个候选答案中挑选出最符合任务要求的那一个。如下就是 LLM-as-a-judge prompt 示例:
You are trajectory reward model, an expert in defining which trajectory is better and closer to solving the task. Here is the task description:
*******************************
task description: {task_description}
task goal: {task_goal}
*******************************
Here are several candidates. They are all trying to solve the task. Their trajectories are as follows.
*******************************
CANDIDATE1:
{candidate_1}
*******************************
CANDIDATE2:
{candidate_2}
*******************************
CANIDATE3:
{candidate_3}
*******************************
CANIDATE4:
{candidate_4}
*******************************
CANIDATE5:
{candidate_5}
*******************************这样可以强制让 LLM 调用以下函数来给出答案:
[{
"type": "function",
"function": {
"name": "choose_preferred_answer",
"description": "Choose the preferred answer for the task within all given answers.",
"parameters": {
"type": "object",
"properties": {
"preference": {
"type": "number",
"enum": [1, 2, 3, 4, 5],
"description": "The index of the preferred answer in all given answers (ranging from 1 to 5)."
},
},
}
}
}]这种方法的优势在于其灵活性和高效性,无需复杂的训练过程,能够快速适应各种不同类型的任务,为智能体的实时评估和优化提供了一种简便易行的解决方案。
LLM-as-a-judge 方法的核心 在于利用大型语言模型的通用性和适应性。通过精心设计的提示指令,LLM 能够在不同的任务场景中快速切换角色,从一个任务的裁判转变为另一个任务的裁判。例如,在处理多语言文本生成任务时,LLM 可以根据不同的语言和文化背景,对智能体生成的文本进行准确评估,确保其符合特定语言的语法和语义要求。
LLM-as-a-judge 方法在处理具有高度复杂性和多样性的任务时表现出色。例如,在处理跨领域的问题解决任务时,智能体需要在不同的知识领域之间进行快速切换和整合。LLM-as-a-judge 能够凭借其强大的语言理解和推理能力,为智能体提供即时的反馈,帮助其在复杂多变的任务环境中保持高效的决策能力。
奖励引导搜索:智能体决策的 “加速器”
Best-of-N 采样 —— 精挑细选的 “决策助手”
在测试阶段,为了充分利用奖励模型的评估能力,提升智能体的决策质量,AgentRM 采用了 Best-of-N 采样方法。简单来说,这种方法就像是为智能体配备了一个精挑细选的决策助手,在面对复杂任务时,能够帮助智能体从众多可能的行动方案中选出最优的那个。
具体操作过程中,智能体会依据当前策略模型,一次性生成 N 条完整的行动轨迹。这些轨迹就像是智能体在脑海中快速模拟出的多种未来情景,涵盖了各种可能的行动路径和决策选择。随后,这些轨迹被逐一输入到奖励模型中进行评估。奖励模型基于其对任务目标和奖励机制的理解,为每条轨迹打分,就像一位严格的评委对每个参赛作品进行打分一样。最终,智能体依据这些分数,选择得分最高的那条轨迹作为最终的行动方案。这个过程可以有效提升智能体在面对复杂任务时的决策质量,还能够充分利用策略模型的生成能力和奖励模型的评估能力,实现两者的完美结合。
Best-of-N 采样方法 的核心在于通过多样化的轨迹生成和精准的评估选择,为智能体提供最优的决策路径。这种方法在处理具有高度不确定性和复杂性的任务时表现出色。例如,在处理多目标优化任务时,智能体需要在多个相互冲突的目标之间找到最优的平衡点。通过 Best-of-N 采样,智能体可以生成多种可能的解决方案,并通过奖励模型对这些方案进行全面评估,从而选出最符合任务要求的最优解。
Best-of-N 采样方法在多智能体协作任务中也具有显著优势。在多智能体环境中,每个智能体都需要根据其他智能体的行为和环境状态做出合理的决策。通过 Best-of-N 采样,每个智能体可以生成多种可能的行动方案,并通过奖励模型评估这些方案在协作环境中的效果,从而选择出最优的行动路径,提高整个多智能体系统的协作效率。
步级 beam search —— 稳扎稳打的 “探索先锋”
如果说 Best-of-N 采样是智能体在多个完整方案中进行选择,那么步级 beam search 则更像是智能体在每一步决策中都进行稳扎稳打的探索,逐步构建出最优的行动路径。在步级 beam search 过程中,智能体的行动被分解为多个步骤,每一步都依据奖励模型的评估进行优化。
初始阶段,智能体为第一步采样 W1×W2 个初始动作,这些动作涵盖了多种可能的决策方向。接下来,对这些动作进行评分,利用奖励模型评估每个动作可能导致的后续状态的价值。根据评分结果,智能体仅保留得分最高的 W1 个状态,淘汰掉那些不太可能带来好结果的选项。在动作扩展阶段,智能体为每个保留下来的状态进一步采样 W2 个动作,从而生成 W1×W2 个新的状态。然后,智能体再次对这些新状态进行评分、过滤和扩展,不断重复这一过程,直到所有保留状态都完成了任务或达到了最大步数限制。这种方法能够在保证探索多样性的同时,逐步聚焦于最有潜力的决策路径,使智能体在复杂任务环境中更加稳健地前行。
步级 beam search 方法 的核心在于通过逐步优化和筛选,为智能体提供一条稳健的行动路径。这种方法在处理具有长期依赖关系和复杂决策序列的任务时表现出色。例如,在处理复杂的机器人路径规划任务时,智能体需要根据环境中的障碍物和目标位置,逐步调整其行动路径。通过步级 beam search ,智能体可以在每一步都对可能的行动方向进行评估和选择,从而逐步构建出一条最优的路径,避免在复杂的环境中迷失方向。
此外,步级 beam search 方法在多任务学习场景中也具有显著优势。由于其能够逐步优化决策路径,因此可以更好地适应不同类型任务的需求。例如,在同时处理网页导航和文本游戏任务时,智能体可以通过步级 beam search 在每一步都对任务目标和环境状态进行评估,从而选择出最优的行动方案,提高其在多个任务上的整体性能。
小结 AgentRM 方法论
AgentRM 方法通过行为克隆、奖励建模和奖励引导搜索等关键技术,为智能体的泛化能力提升提供了一套完整的解决方案。显式奖励建模和隐式奖励建模分别从不同角度为智能体提供了精准的奖励信号,而 LLM-as-a-judge 方法则为智能体提供了灵活的实时评估能力。Best-of-N 采样和步级 beam search 方法则在测试阶段为智能体的决策提供了优化支持。这些方法的结合可以显著提升智能体在复杂任务中的表现,为智能体的泛化能力提升提供了新的思路和方向。
实验设计与结果分析
实验基线对比:与强大对手的 “巅峰对决”
为了全面评估 AgentRM 的性能,研究者们精心设计了一系列实验,将其与多种现有的智能体方法进行了对比。对比方法包括原始贪婪搜索、任务特定智能体(如 SPIN、NAT、ETO 等)以及通用智能体(如 Agent - FLAN、AgentGym、AgentGen 等)。这些对比方法各具特色,代表了当前智能体领域的不同发展方向。
原始贪婪搜索作为一种基础的决策方法,智能体在每一步都选择当前看起来最优的行动,不考虑未来的不确定性和可能的更好结果。任务特定智能体则专注于某一特定类型的任务,经过专门的优化和训练,在特定领域内展现出了卓越的性能。例如,SPIN 通过增强专家轨迹数据集,提升了智能体在特定任务上的表现;NAT 和 ETO 则通过引入失败轨迹,让智能体从错误中学习,进一步增强了其应对复杂情况的能力。
通用智能体的目标则更为宏大,它们可以通过多任务学习,掌握多种不同类型任务的解决方法,实现更广泛的泛化能力。Agent - FLAN 专注于优化 LLM 的 “思考” 过程,通过精心设计的提示和训练方法,让智能体在多种任务中展现出灵活的思维能力;AgentGym 则通过持续学习和动态调整,使智能体能够不断适应新任务和新环境;AgentGen 借助 LLM 合成多样化数据,为智能体的训练提供了丰富的素材,拓宽了其能力边界。
在与这些强大对手的对比中,AgentRM 以其独特的奖励建模方法脱颖而出,它在已见任务上保持了竞争力,更在未见任务上展现出了卓越的泛化能力,为智能体领域的发展提供了一种新思路。
实验设置:精细入微的 “标尺”
数据集:智能体能力的 “练兵场”
实验的数据集选取了多个具有代表性的智能体任务,它们犹如智能体能力的 “练兵场”,全面覆盖了智能体在实际应用中可能遇到的各种场景和挑战。其中,已见任务包括 ETO 中的 Webshop(网页导航)、Alfworld(实体家庭操作)和 Sciworld(实体科学实验)三个任务。这些任务具有明确的指令和目标,并且还涉及到复杂的环境交互和长期决策,能够充分考验智能体的基本能力和泛化潜力。
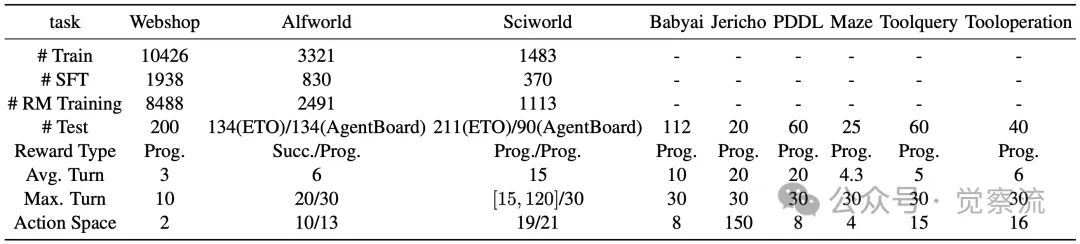
已保留任务和未保留任务的统计数据。“Prog./Succ.”表示进展/成功率
为了更全面地评估智能体的泛化性能,研究者们还从 AgentBoard 和 AgentGym 中选取了一系列未见任务。这些任务在环境动态性、任务目标和操作要求等方面与已见任务存在显著差异,能够有效检验智能体在陌生环境中的适应能力和迁移学习效果。在处理 Alfworld 和 Sciworld 任务时,研究者们特别注意了不同来源数据的一致性问题,确保实验结果的可靠性和可比性。
评估指标:衡量智能体表现的 “标尺”
在评估指标方面,研究者们根据不同任务的特点,采用了成功率和进度率两种指标来衡量智能体的表现。Maze 和 Alfworld(ETO)任务提供了成功率指标,它清晰地反映了智能体是否能够成功完成任务目标,是一个简单直接的评价标准。对于其他任务,则采用了进度率指标,该指标以标量形式衡量智能体对任务完成进度的推进程度,能够更细腻地反映智能体在复杂任务中的表现。最终,研究者们以每个任务的平均奖励作为综合评估指标,将成功率和进度率有机结合起来,全面衡量智能体在不同任务中的整体表现。
实现细节:实验落地的 “基础设施”
在实现细节上,研究者们选择了 LLaMA3-8B-Instruct 系列模型作为策略模型,这一选择基于其在自然语言处理领域的卓越性能和广泛的适用性。为了获得高质量的初始策略模型和奖励模型训练数据,研究者们对专家轨迹数据进行了合理划分。1/4 的专家轨迹用于监督微调(SFT),通过模仿专家的决策路径,让初始策略模型掌握基本任务技能;剩余 3/4 的专家轨迹则用于构建奖励模型训练数据,为智能体的优化提供了丰富的反馈信息。这些精心设计的实现细节,为实验的成功落地提供了坚实的基础设施保障。
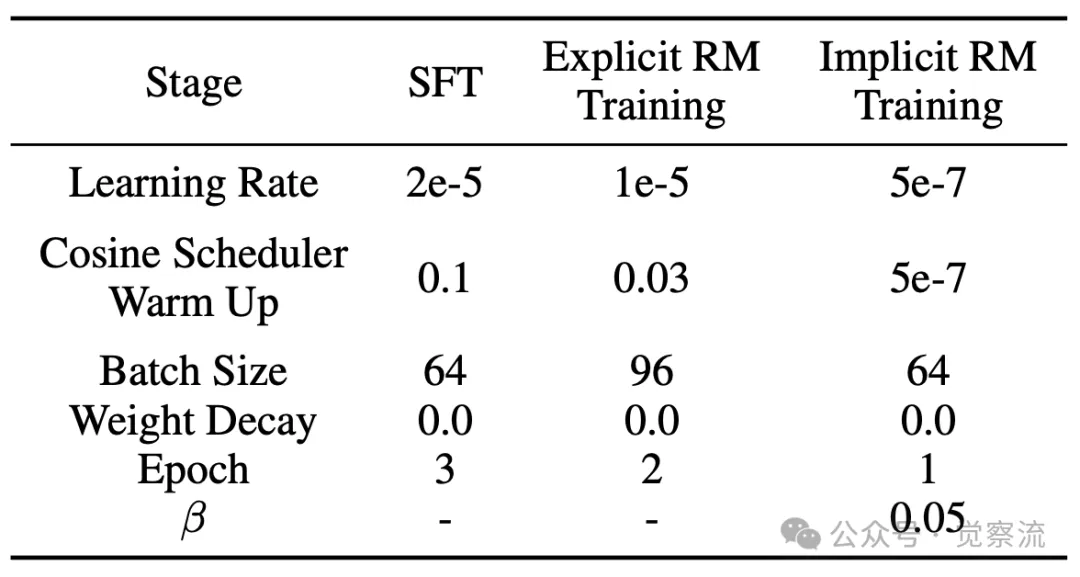
不同阶段的训练超参数
结果呈现与解读:数据背后的 “真相” 与 “惊喜”
与通用智能体对比:泛化能力的 “分水岭”
在与通用智能体的对比中,下表的数据揭示了一个令人深思的现象。现有通用智能体在已见任务上普遍存在严重过拟合的问题,其整体性能甚至未能超越原始贪婪搜索这一简单基线。这一结果表明,尽管这些通用智能体在多任务学习方面做出了诸多努力,但它们在平衡已见任务和未见任务性能方面仍存在较大缺陷。
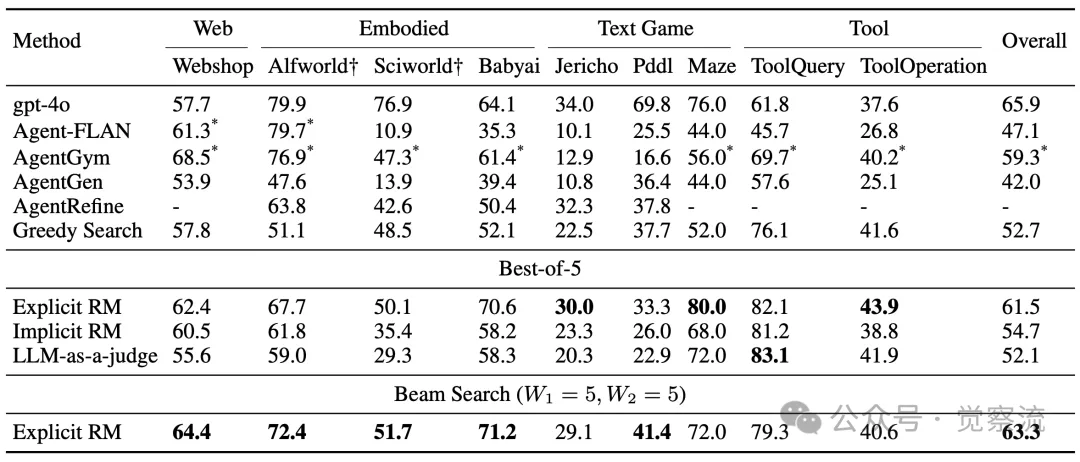
性能与通用智能体的对比分析。带有*号的任务表示在策略训练期间已经见过,并作为保留任务进行评估
然而,AgentRM 的三种奖励建模方法却展现出了截然不同的局面。显式 RM 表现最为出色,平均性能提升了 8.8 个点,远超其他方法。这一显著提升,证明了显式奖励建模在捕捉任务关键特征和引导智能体优化方面的优势,也为智能体的泛化能力提升提供了一条切实可行的路径。此外,在与已见任务具有一定相似性的 Babyai 任务上,显式 RM 展现出了明显的正迁移效应,进一步验证了其在知识迁移方面的潜力。而部分策略模型在未训练任务上出现的负迁移现象,则从反面凸显了 AgentRM 方法的稳健性和优势。
值得注意的是,LLM-as-a-judge 方法在整体性能上较贪婪搜索略有下降,但在一些相对简单的任务上,如工具相关任务,却表现出了相对较好的性能。这表明,LLM-as-a-judge 在面对简单任务时,能够凭借其强大的语言理解和推理能力,快速准确地做出评估,为智能体提供有效的指导。
与任务特定智能体对比:多任务精通的 “新星”
在与任务特定智能体的对比中,下表的数据令人兴奋。使用显式 RM 的 Best-of-5 方法在三个已见任务上分别提升了策略模型 9.6、23.2 和 9.5 个点,下表这一卓越表现成功超越了多个顶级任务特定智能体。这一结果犹如一颗新星崛起,证明了 AgentRM 方法在多任务精通方面的巨大潜力。
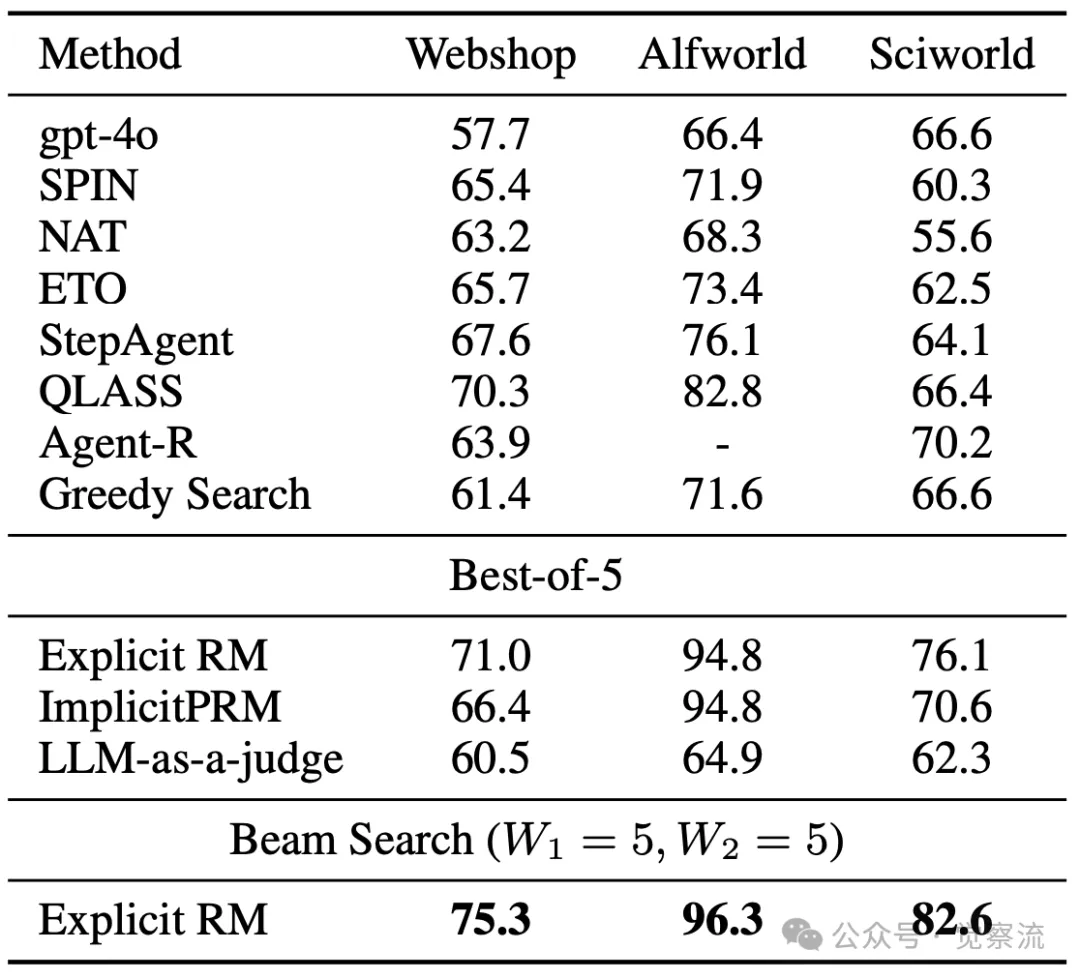
与特定任务型 Agent 的比较
与传统任务特定智能体不同,AgentRM 无需为每个任务单独训练策略模型,而是通过一个通用的奖励模型,在多个任务上实现了性能的全面提升。这种方法不仅降低了训练和维护成本,还为智能体在实际应用场景中应对多种不同类型任务提供了可能。例如,在一个要求智能体既能进行网页导航,又能完成家庭操作和科学实验的复杂场景中,AgentRM 能够凭借其通用奖励模型,快速适应不同任务要求,高效地完成各项任务。
更为令人兴奋的是,当结合步级 beam search 时,AgentRM 的性能还能进一步提升。这表明,AgentRM 与搜索策略之间存在良好的协同效应,通过优化搜索过程,能够充分挖掘奖励模型的潜力,使智能体在复杂任务中表现得更加出色。
深入分析:挖掘 AgentRM 的 “潜力宝藏”
对扰动的鲁棒性:智能体的 “定海神针”
为了测试 AgentRM 在面对输入扰动时的表现,研究者们在 Alfworld 任务指令中精心设计了 5 种不同类型的扰动实验。这些扰动包括修改动作描述中的关键词、调整语句结构、删除空格等,这可以模拟智能体在实际应用中可能遇到的各种输入变化。
实验结果显示,AgentGym 和 Agent-FLAN 在面对这些扰动时性能出现了显著下降。以 Alfworld 任务为例,AgentGym 的成功率下降了 25.6 个点,Agent - FLAN 的成功率更是下降了 30.3 个点。而 AgentRM 方法却展现出了强大的鲁棒性,其平均分最高且标准差最低。这一结果表明,AgentRM 并非简单地记忆训练数据中的模式,而是真正具备了从语义层面理解和应对任务指令的能力,能够在复杂多变的输入环境中保持稳定的性能。这种对扰动的鲁棒性犹如智能体的 “定海神针”,使其在实际应用中更具可靠性。

在不同扰动规则下Alfworld的性能表现。其中,“Succ./Prog.”分别表示成功率和进度率。带有“∗”的任务表示在训练过程中见过,并被视为内部保留评估任务
上表展示了 Alfworld 任务在不同扰动规则下的性能表现,清楚地呈现了 AgentRM 在面对输入扰动时的优异鲁棒性。
训练数据规模的扩展趋势:数据驱动的 “成长之路”
下图清晰地展示了奖励模型训练数据量与整体性能之间的关系,为数据驱动的智能体训练提供了有力证据。实验结果表明,即使只有 4k 状态的小规模数据集,也能有效提升奖励模型在智能体任务中的性能,其表现甚至超过了基于提示的、无需训练的 LLM-as-a-judge 方法。这一发现令人振奋,因为它证明了 AgentRM 方法在数据受限场景下的有效性,为在资源有限的情况下提升智能体性能提供了可能。
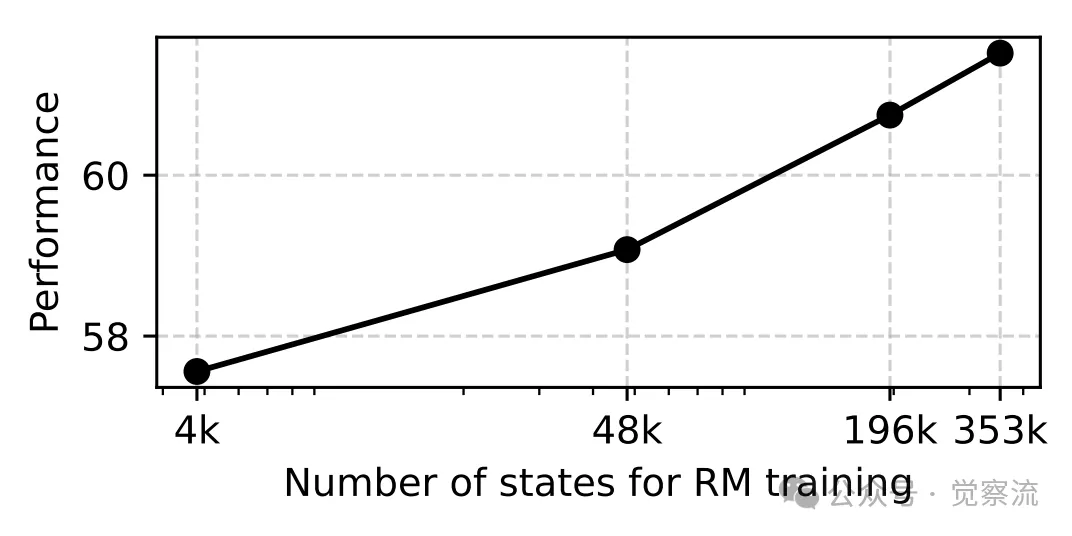
训练数据的规模增长趋势
随着训练数据量的不断增加,奖励模型的性能呈现出持续增长的趋势,并且没有出现饱和迹象。这种对数线性增长的趋势表明,AgentRM 方法具有很强的扩展性,随着更多数据的积累和利用,其性能有望进一步提升。这为智能体领域的未来发展指明了一条数据驱动的 “成长之路”,即通过不断收集和利用高质量的训练数据,逐步优化奖励模型,从而不断提升智能体的性能。
任务特定 RM 的泛化性:多样性铸就的 “泛化长城”
通过分析下图中各任务特定 RM 在不同任务上的表现,研究者们发现,通用 RM 在多数任务上优于任务特定 RM。这一结果有力地验证了任务多样性对于提升奖励模型泛化能力的重要性。当奖励模型接触到多种不同类型的任务时,它能够学习到更广泛、更通用的奖励模式,从而在面对新任务时具备更强的适应能力。
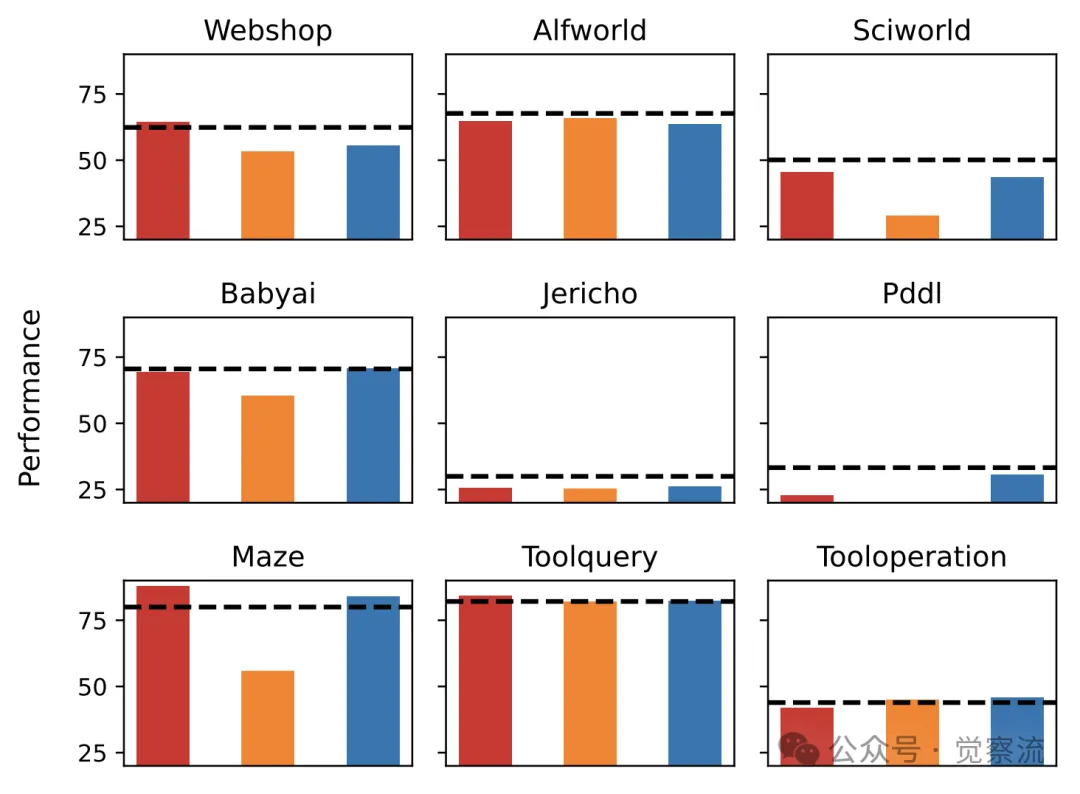
针对9项任务的特定任务型RM(任务特定模型)性能表现。红色/橙色/蓝色条形分别表示在 Webshop/Alfworld/Sciworld上训练的RM。虚线表示通用RM的性能表现
然而,Alfworld 任务特定 RM 的性能相对较弱,研究者们推测这可能与该任务在构建奖励模型训练数据时采用成功率而非更密集的进度率作为结果监督信号有关。成功率作为一种稀疏的奖励信号,无法提供足够的反馈信息来引导奖励模型的学习过程,从而限制了其性能表现。这一发现提醒我们在设计奖励模型时,应充分考虑奖励信号的密度和质量,以确保模型能够获得充分有效的学习指导。
对其他策略模型的泛化性:弱智能体经验的 “逆袭舞台”
实验结果表明,仅在 LLaMA-3-8B 策略模型采样状态下训练的 RM,能够有效应用于其他 LLM 智能体。如下表所示,该 RM 对 LLaMA-3-70B 提升了 12.6 个点,对 AgentGen 提升了 5.9 个点。这一现象揭示了弱智能体的试错经验对于强智能体性能提升的巨大价值,为智能体领域的知识传承和能力迁移提供了一个全新的视角。
在这个过程中,弱智能体通过大量的试错积累的经验,犹如一座蕴藏丰富的矿山,为强智能体的优化提供了宝贵的资源。强智能体在吸收这些经验后,能够在更复杂的任务环境中展现出更出色的性能。这种弱到强的泛化能力,可以拓宽智能体能力提升的路径,并且为构建高效、经济的智能体训练体系提供了新的思路。
奖励建模的状态表示:信息融合的 “艺术之美”

显式奖励模型的状态表示的消融实验
上表的消融实验结果深入揭示了奖励建模中状态表示的奥秘。实验发现,奖励建模主要依赖动作标记,仅使用动作标记建模对整体有效性影响不大,反而能加速训练和推理过程,提升方法的可扩展性。这一发现令人惊讶,因为它颠覆了我们对状态表示的传统认知,让我们意识到在某些情况下,简化状态表示反而能够提高模型的效率和性能。

判断相对步长奖励的准确性
然而,思考和观察标记并非可有可无。实验结果显示,当同时移除思考和观察标记时,性能下降了 3.2 个百分点。这表明思考和观察标记虽然单独影响较小,但它们在状态表示中提供了互补的信息,共同作用时能够提升模型的性能。这种信息融合的艺术之美,体现了智能体在决策过程中对多维度信息的综合考量,也为我们设计更优的状态表示方法提供了启示。
测试时搜索的扩展趋势:计算资源的 “效益最大化”
以 Pddl 任务为例,研究者们深入探讨了增加 Best-of-N 采样候选数量时,不同奖励建模方法的性能变化趋势。显式 RM 随着计算资源的增加持续提升性能,展现出强大的扩展能力。这表明在显式奖励建模的引导下,智能体能够充分利用额外的计算资源,生成更多高质量的候选轨迹,从而提高决策质量。下图就展示了随着 Best-of-N 采样候选数量的增加,不同奖励建模方法的性能变化趋势,揭示了不同奖励建模方法在测试时扩展(Test-time Scaling)方面的差异和挑战。
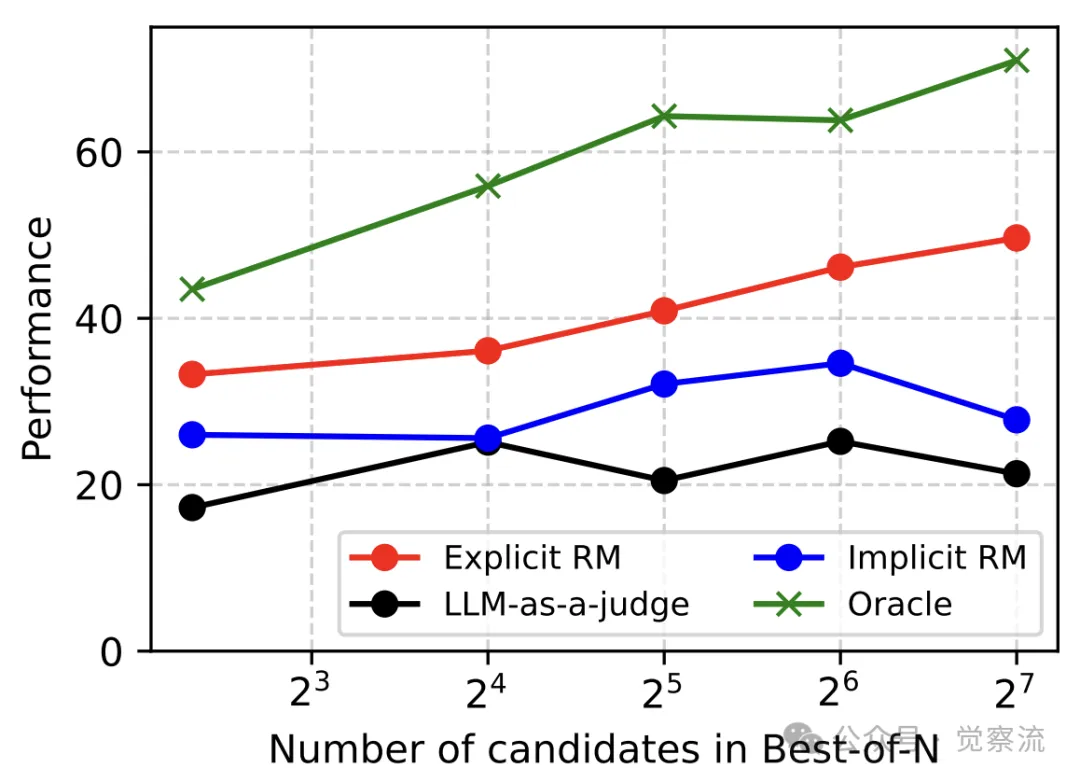
Best-of-N 的扩展趋势
相比之下,隐式 RM 在候选数量过多时可能会因混淆而出现性能下降。这可能是由于隐式 RM 在处理大量候选轨迹时,难以区分细微的奖励差异,导致选择出错。而 LLM-as-a-judge 方法由于模型输入长度的限制,在候选数量增加时,超出长度限制的部分会被截断,从而影响了其扩展性。这一发现提示我们,在设计测试时搜索策略时,需要充分考虑不同奖励建模方法的特点和限制,以实现计算资源的效益最大化。
对通用推理任务的泛化性:通用推理的 “隐藏天赋”
当研究者们将仅在智能体任务上训练的 RM 应用于通用推理基准测试(如 GSM8k、MATH 和 codecontests)时,下表的结果显示 RM 对通用推理任务的影响微乎其微。这一现象表明,AgentRM 在智能体任务上的训练并未使其局限于特定任务模式,而是获得了一种更通用的推理能力。这种能力就像智能体的 “隐藏天赋”,使其在面对不同类型的推理任务时,能够灵活调用已有的知识和经验,展现出一定的适应性。
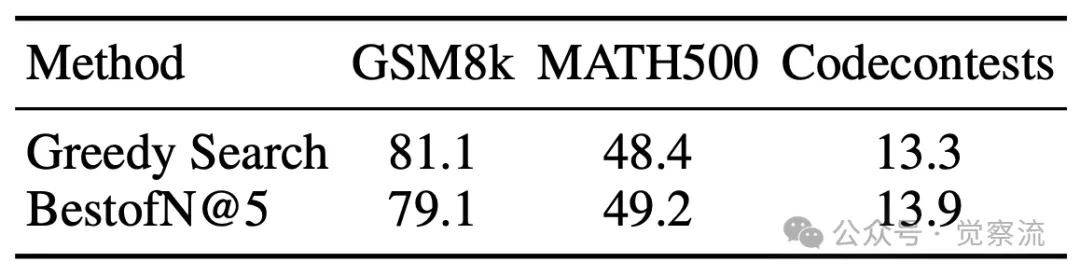
在通用推理任务中的表现
尽管这种影响较为微弱,但它揭示了 AgentRM 作为一种通用奖励模型的潜力。
总结:智能体发展的 “新航标”
AgentRM 这篇研究论文主要讲了如何让基于大型语言模型(LLM)的智能体在各种复杂任务中表现得更好,尤其是在之前没见过的新任务中。论文的核心就是提出了一个叫 AgentRM 的通用奖励模型,这个模型能有效地引导智能体在执行任务时做出更好的决策。
这就像我们用GPS导航软件找路线一样,现有的导航软件(好比策略模型)在熟悉的路上表现很好,但一旦遇到没走过的新路,可能就会迷路。这篇论文的研究发现,与其直接优化这个导航软件本身(策略模型),不如先训练一个专门的“路线评估员”(奖励模型)来帮助它。这个“评估员”会告诉导航软件每一步的决策是好还是坏,从而引导它找到更好的路线。
AgentRM 作为一种创新的通用奖励模型,通过测试时搜索显著提升了LLM智能体在多种智能体任务中的性能,在专一性和泛化性方面都交出了令人满意的答卷。它不仅在实验中展现出了卓越的性能提升,还通过深入分析验证了其在测试时扩展、对其他策略模型的直接迁移性等方面的巨大潜力。
文中提出了:
三种奖励模型方法:文中详细研究了三种不同的方法来构建这个奖励模型:显式奖励建模、隐式奖励建模和LLM作为裁判。显式奖励建模就是直接给出每一步的奖励,隐式奖励建模则是让模型自己通过最终结果推断出每一步的奖励,而LLM作为裁判则是利用大型语言模型来直接判断哪条路线更好。
实验验证:在九个不同的任务上进行了实验,包括网页导航、实体规划、文本游戏和工具使用等,发现AgentRM能显著提升策略模型的性能,并且在多项指标上超越了现有的通用智能体和专用智能体。
泛化能力:AgentRM不仅在训练过的任务上表现良好,还能很好地推广到未见过的任务,这种能力在智能体领域是非常重要的。
当然,AgentRM 也具有局限性。目前的研究仅包含了三个已见任务,这限制了我们对其在更广泛任务场景中的全面评估。同时,MCTS 参数设置有限,可能影响了过程奖励估计的精度。
最后,我想期待一下,在学界和业界能够看到更多关于奖励建模的研究与实践。毕竟,智能体能够高效地获得奖励建模,对于智能的进化起着至关重要的作用。


