在 LLM Agent 领域,有一个常见的问题:Agent 明明 "看到了" 错误信息,却总是重蹈覆辙。
在 LLM Agent 领域,有一个常见的问题:Agent 明明 "看到了" 错误信息,却总是重蹈覆辙。
当 Agent 遇到工具调用错误时,错误日志里往往已经包含了解决方案 —— 正确的参数格式、有效的 API 用法、甚至是直接可用的替代方案。然而,静态的 Prompt 无法让 Agent 从这些反馈中 “学到教训”,导致它们陷入 “错误循环”:承认失败,却重复同样的动作。
华为诺亚方舟实验室与香港中文大学联合发布的 SCOPE 框架,旨在解决这一问题。

论文:《SCOPE: Prompt Evolution for Enhancing Agent Effectiveness》
论文地址:https://arxiv.org/abs/2512.15374
开源地址:https://github.com/JarvisPei/SCOPE
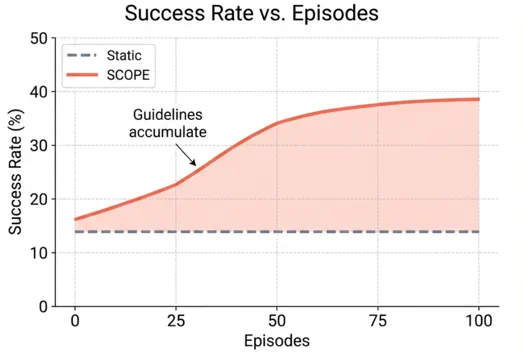
SCOPE 的核心思想是:既然 Agent 会被反复调用,那么它的 Prompt 就可以在执行过程中不断进化。通过从执行轨迹中自动提炼指导规则,SCOPE 让 Agent 能够 "从错误中学习",并将经验固化到 Prompt 中,实现自我进化。
Agent 的两大失败模式
研究团队分析了 GAIA 和 DeepSearch 基准上的 Agent 执行日志,发现了两类典型的失败模式:
第一类是「纠正型失败」(Corrective Failure):当错误发生时,执行轨迹中包含明确的信号(错误消息、堆栈跟踪、有效参数列表),本应指导 Agent 进行修正。然而,静态的 Agent 把这些信息当作泛泛的 “警报”,而不是可操作的反馈。研究者观察到大量案例,Agent 在错误消息明确列出正确用法的情况下仍然误用工具,形成 “错误循环”。更严重的情况下,Agent 甚至会为了继续执行而 “编造数据”。
第二类是「增强型失败」(Enhancement Failure):即使没有明显错误,Agent 也会错过优化机会。比如当搜索结果不理想时,上下文往往暗示可以尝试同义词(如 “base on balls” 与 “walks”),但 Agent 却固守单一关键词策略。这种失败更加隐蔽,但同样影响任务成功率。
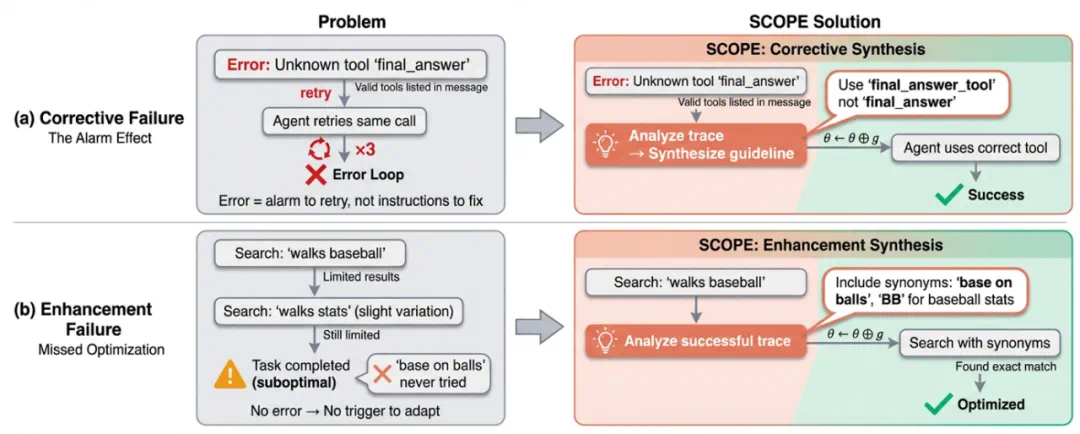
这两类失败的根本原因是相同的:静态 Prompt 缺乏从执行反馈中学习的机制。
SCOPE 框架:从执行轨迹中学习
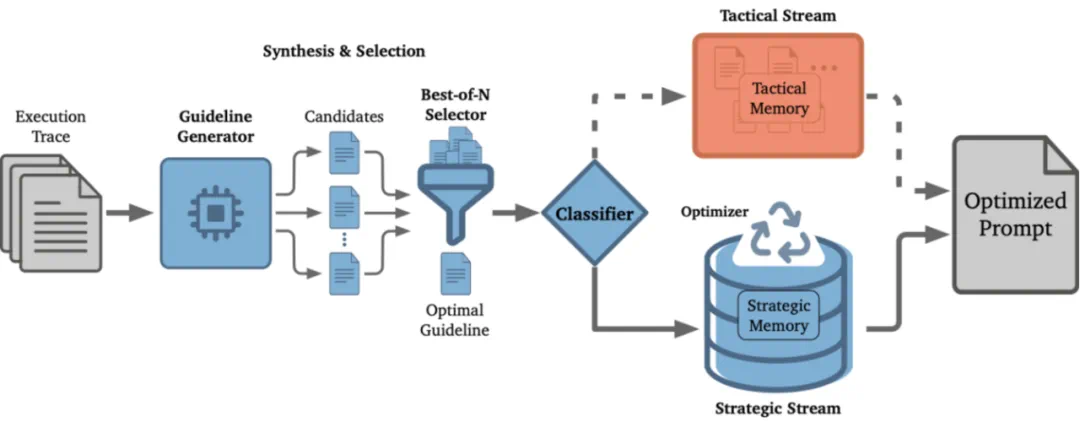
针对上述问题,SCOPE 将上下文管理从手动工程任务转变为自动优化过程。其核心洞察是:Agent 自身的执行轨迹就是最好的学习信号。
SCOPE 框架由四个核心组件构成:
1. 指导规则合成(Guideline Synthesis)
当 Agent 遇到错误或完成子任务时,SCOPE 的生成器(Generator)会分析执行轨迹,合成候选指导规则。这里采用 Best-of-N 策略:生成多个候选规则,然后由选择器(Selector)挑选最佳的一条。
针对不同场景,SCOPE 使用两种合成模式:纠正型合成从错误中提取教训,增强型合成从成功模式中挖掘优化机会。实验表明,增强型规则占所有合成规则的 61%,说明 SCOPE 不仅仅是 “错误修复器”,更是一个主动的优化器。
2. 双流路由机制(Dual-Stream Routing)
合成的规则并非同等对待。SCOPE 引入分类器(Classifier)将规则路由到两个记忆流:
战术记忆(Tactical Memory):存储任务特定的规则,如 “当前数据集的‘Amount’列包含货币符号,计算前需进行清洗”。这些规则仅在当前任务的数据上下文中有效。
战略记忆(Strategic Memory):存储跨任务通用的规则,如 “当 Web 搜索返回结果为空时,尝试泛化搜索关键词而不是重复搜索”。这些规则会持久化保存,应用于未来所有任务。
只有高置信度(阈值设为 0.85)的通用规则才会被提升到战略记忆,避免过拟合到特定任务。
3. 记忆优化(Memory Optimization)
随着规则积累,战略记忆可能包含冗余或冲突的内容。SCOPE 的优化器(Optimizer)会执行三步清理:冲突解决(合并矛盾规则)、冗余剪枝(移除被更通用规则覆盖的具体规则)、整合归并(将相似规则合并为综合性规则)。
4. 视角驱动探索(Perspective-Driven Exploration)
单一进化路径可能收敛到某种策略,在部分任务上表现较好但在其他任务上失效。为了提高策略覆盖,SCOPE 初始化多个并行流,每个流由不同的 "视角" 引导(如效率优先 vs. 周全优先),各自进化出不同的 Prompt。测试时选择最佳结果。
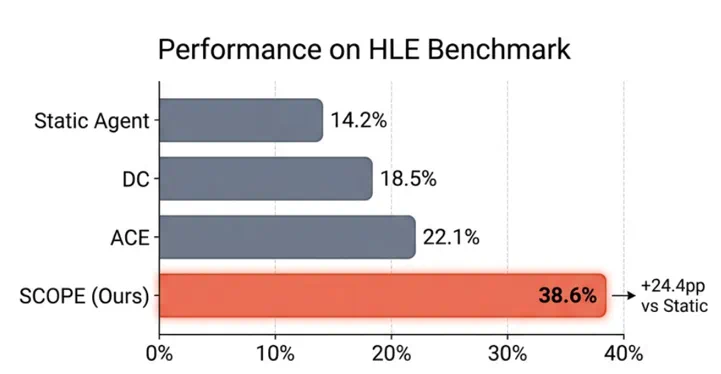
实验结果:HLE 成功率从 14% 提升到 39%
研究团队在三个基准上进行了评估:HLE(2500 道专家级问题)、GAIA 和 DeepSearch。
实验结果表明,SCOPE 在所有基准上都取得了提升:
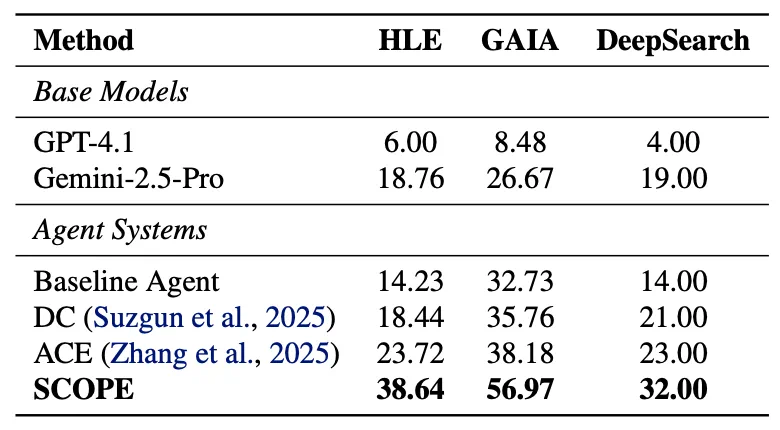
在 HLE 基准上,SCOPE 将任务成功率从 14.23% 提升到 38.64%。在 GAIA 基准上,成功率从 32.73% 提升到 56.97%。
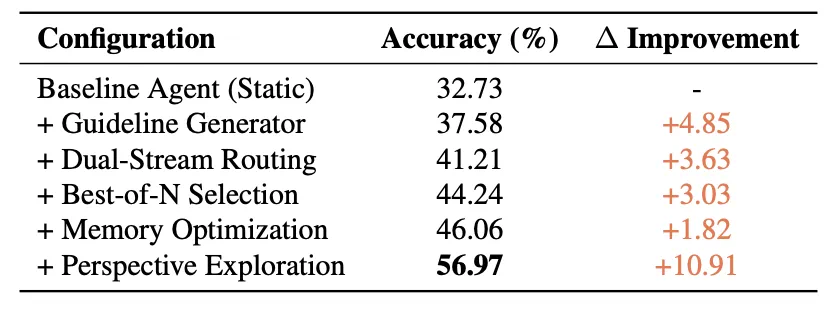
为了更准确地表达不同组件的贡献,论文中给出了消融实验。如下图所示,指导规则生成器提供 + 4.85% 的初始提升,双流路由贡献 + 3.63%,Best-of-N 选择贡献 + 3.03%,记忆优化贡献 + 1.82%,而视角驱动探索带来 + 10.91% 的提升。
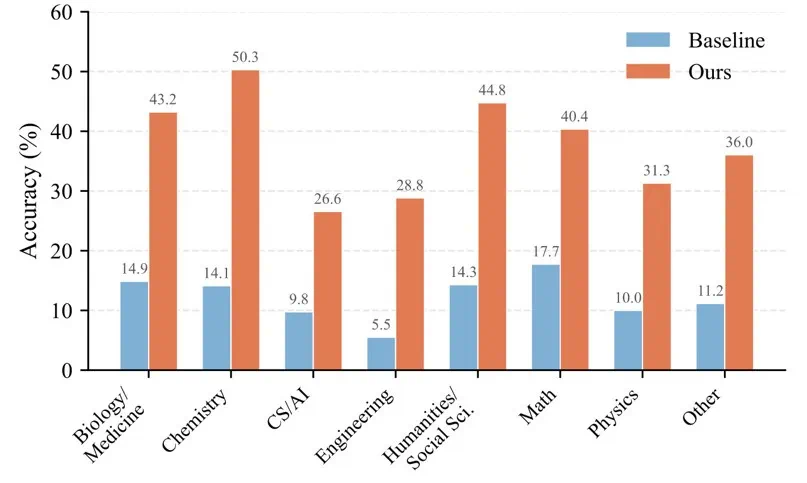
值得注意的是,在知识密集型领域(如生物 / 医学、化学),SCOPE 的提升较为明显:生物 / 医学从 14.9% 提升到 43.2%,化学从 14.1% 提升到 50.3%。这些领域的问题往往涉及复杂的专业概念和严格的推理流程,SCOPE 合成的领域特定规则能够帮助 Agent 更好地理解和遵循这些要求。
Agent 真的在 "听话" 吗?
一个关键问题是:合成的规则是否真正影响了 Agent 的行为?
如下图所示,研究团队观察到了 "语言采纳" 现象:当 SCOPE 合成了 "始终列出所有可能的标签同义词和短语变体" 这一规则后,Agent 后续输出中直接引用了相同的措辞。这表明规则被整合到了 Agent 的决策过程中。此外,行为变化通常在规则合成后几秒内就会发生,展示了单个任务内的实时适应能力。

视角驱动策略多样性
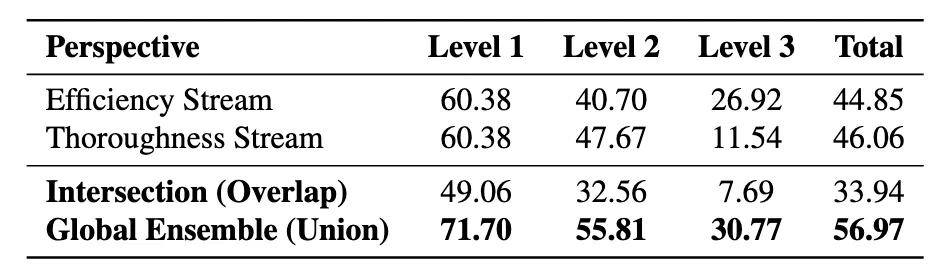
视角驱动探索的设计得到了实验验证。如下图所示,效率流(Efficiency Stream)和周全流(Thoroughness Stream)的总体准确率相近(44.85% vs 46.06%),但两者解决的问题重合度仅为 33.94%,这意味着约 23% 的问题只能被其中一个视角解决。
效率流在 GAIA 的 Level 3 任务上表现更好(26.92% vs 11.54%),说明精简的上下文管理对复杂长程任务更有效;而周全流在 Level 2 任务上更强。全局集成捕获了两种策略的优势。
定性分析显示,面对同一个 HTTP 403 访问拒绝错误,效率流学会 “快速失败”—— 立即升级到搜索 Agent,不再重试;而周全流则学会 “寻找替代来源”—— 尝试 Archive.org 或转录工具。这种二元性让 SCOPE 能够同时处理时间紧迫型和深度检索型任务。

SCOPE 的意义
华为诺亚方舟实验室与香港中文大学联合提出的 SCOPE 框架,通过将执行轨迹作为学习信号、将 Prompt 视为可进化的参数,实现了 Agent 的在线自我优化。
与现有方法相比,SCOPE 具有三个主要特点:
步级别适应(Step-level adaptation):在执行过程中更新 Prompt,允许从任务中途的失败中恢复,而非等到任务结束才学习。
单 Agent 优化(Per-agent optimization):每个 Agent 角色基于自身特定的模式进化 Prompt,而非使用 "一刀切" 的策略库。
主动优化:61% 的规则来自成功模式的增强型合成,而非仅仅修复错误。

SCOPE 的代码已在 GitHub 开源。正如论文所总结的:“与其工程化静态 Prompt,不如让 Agent 在线进化自己的 Prompt。” 这一思路可能为下一代 Agent 系统的设计提供新的方向。
值得一提的是,SCOPE 的开源实现具有较好的实用性:
即插即用:只需在 Agent 执行循环中调用 `on_step_complete ()` 接口,即可为现有 Agent 系统添加自我进化能力,无需修改原有架构。
模型无关:通过统一的适配器接口支持 OpenAI、Anthropic 以及 100 + 其他模型提供商(via LiteLLM),方便开发者使用自己偏好的模型。
轻量部署:核心依赖精简,可通过 `pip install scope-optimizer` 一键安装。
SCOPE 提供了一套完整的实现框架,其核心洞察是:Agent 的执行轨迹本身就是最好的学习素材 —— 关键在于如何将这些经验有效地编码到 Prompt 中。对于希望增强 Agent 系统效能的开发者而言,SCOPE 提供了一个可直接使用的解决方案。