
本文作者包括新加坡国立大学的王天一 (第一作者)、程轩昂、Mohan Kankanhalli (通讯作者),和山东大学的刘明慧。
工作动机
近些年来,针对深度伪造 (Deepfake) 的主动防御研究角度逐渐受到广泛关注。在现有工作中,鲁棒水印和半脆弱水印分别在 Deepfake 检测任务取得一定进展,但仍普遍存在如下问题:
面对常规图像处理 (如高斯噪声) 时的鲁棒性不稳定。
暂不具备同时进行鉴伪和伪造区域定位的功能。
通过比对水印来判断真伪而存储 ground-truth 的操作大量消耗了计算资源。
工作介绍
为解决上述问题,该论文提出 FractalForensics,一种基于分形水印的主动深度伪造检测与定位方法。不同于以往的水印向量,为达成伪造定位的功能,论文提出的水印以矩阵形式出现。

论文地址:https://arxiv.org/abs/2504.09451
首先,该论文设计了一个水印生成和加密流程 (图 1),旨在使整个流程参数化。依赖于基于参数的分形几何形状及其具备的可迭代特性,先将其选择作为水印的基础 (本文以标准希尔伯特曲线为例)。
其后,分别定义旋转 (r), 镜像 (m), 次序改变 (o) 三个变体参数,为分形水印的形状变化提供多样性 (在该论文实验中,所有参数组合共可得 144 种分形变体)。
进一步地,针对以迭代顺序标记的分形矩阵,构建一个混沌加密系统,基于参数 x_0 和 a 来决定混沌序列的迭代,并基于参数 k 和 d 来分别选择开始选取用于加密的值和位数,按照矩阵中的数字顺序对其进行加密。
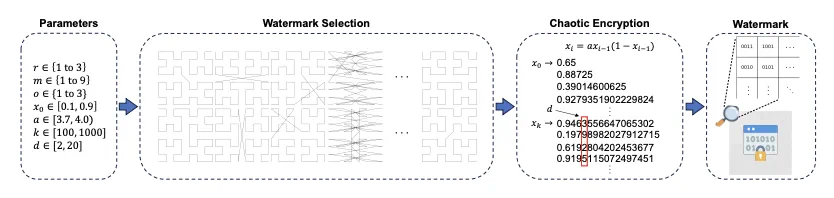
图 1: 基于参数的水印生成和加密流程。
如图 1 所示,假设搭建一个用户服务平台,嵌入并封装该水印生成和加密流程,相比于预先保存所有的水印 ground-truths,用户可自选每个参数的值来构建和加密水印,且只需保存所选参数即可。加密后的矩阵中的值是 0 到 9 之间的一位十进制数字,而为了获得更大的水印嵌入和提取容错率,本方法将所有十进制值转化成四位二进制值。
该论文中的水印嵌入与提取模型主要基于卷积神经网络 (图 2)。在水印嵌入阶段,考虑到图片对于水印嵌入的合理容量,论文提出 entry-to-patch 策略,将图片划分为相同大小的相同 patch (本文中 patch 的大小为 32 x 32),并将水印矩阵以位置对应的方式向图片中嵌入。
详细来说,在加密后的水印中,每个四位二进制水印值被调整维度至通道数为 4 的相同空间位置的值,从而不破坏水印和图片对应的位置关系。
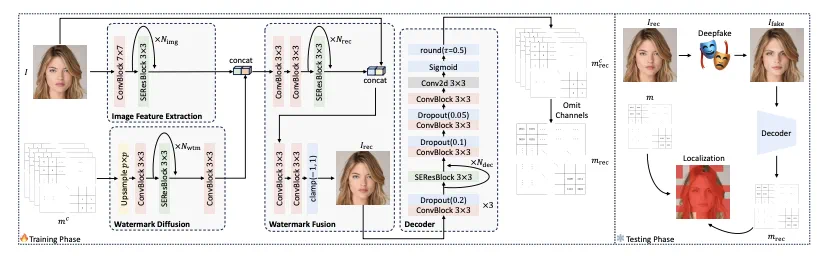
图 2: 水印嵌入与提取流程。
同时,为保证 patch 之间对应的水印尽可能互不影响,在图像特征映射、水印扩散、水印嵌入等过程中,卷积核的大小被设为远小于 patch 大小的值。当针对被 Deepfake 篡改后的图片提取水印时,得益于 entry-to-patch 的嵌入策略,被篡改的区域会丢失水印,而反之则保留水印,由此可在进行 Deepfake 检测的同时完成伪造定位 (如图 2 右下人脸图片中标红所示丢失水印的区域)。
实验结果
由于 Deepfake 对人脸图片中对应区域内容特征的修改,该水印嵌入流程对其具有天然的脆弱性。因此,经过针对 Jpeg 压缩的对抗训练以确保水印鲁棒性之后,便可获得期待的鲁棒性和脆弱性。如表 1 所示,该文章所提出的水印在面对常见图像处理方法时维持了最优的鲁棒性,并如表 2 所示,在面对 Deepfake 伪造方法时展现了合理的脆弱性。
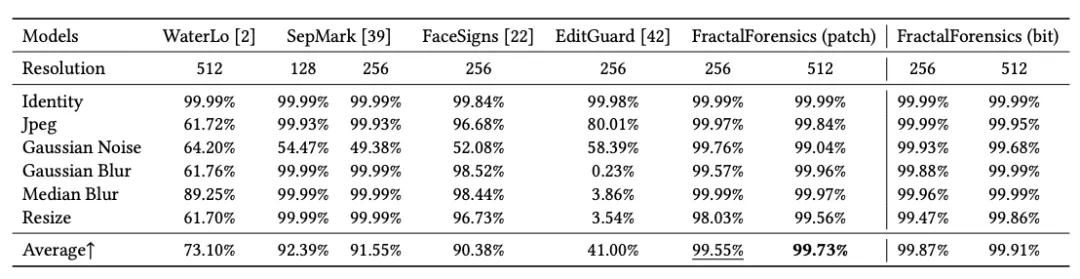
表 1: 在 CelebA-HQ 数据集上面对常见图像处理方法的水印鲁棒性评估。
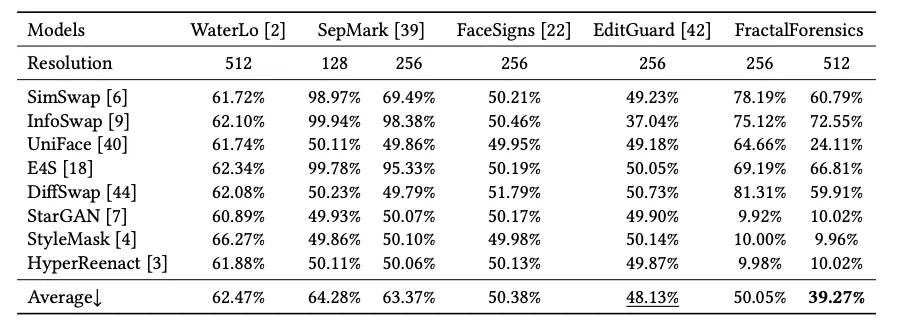
表 2: 在 CelebA-HQ 数据集上面对 Deepfake 伪造方法的水印脆弱性评估。
进一步地,该文章根据水印恢复率的鲁棒性和脆弱性之间的显著差异,计算了 Deepfake 检测的 AUC 效果,并与被动检测的 SOTA 工作进行对比取得了最优检测效果,具体实验结果如表 3 所示。
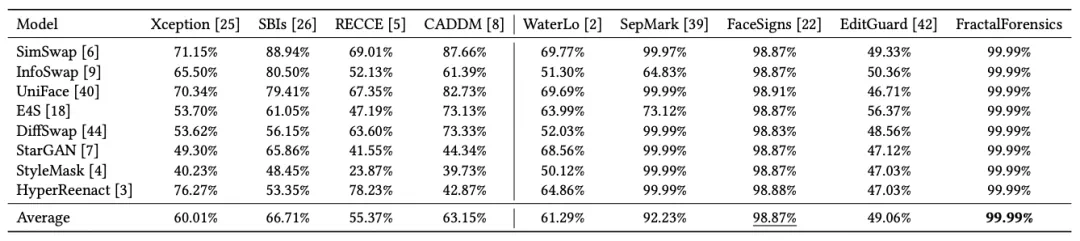
表 3: 在 CelebA-HQ 上进行的 Deepfake 检测效果比较与评估。
伪造定位的效果如图 3 和图 4 所示。基于水印鲁棒性,在面对良性图像处理时不会定位伪造区域;基于水印脆弱性,由于 face swapping 方法主要篡改人脸内部区域,因此定位的伪造区域也主要聚焦在人脸位置,而 face reenactment 因篡改区域更广则导致定位的区域分布更离散。

图 3: 针对常见良性图像处理方法的伪造定位。

图 4: 针对恶意 Deepfake 伪造方法的伪造定位。
第一作者信息
王天一,本科毕业于美国华盛顿大学西雅图分校,取得计算机科学和应用数学双专业学位;博士毕业于香港大学,取得计算机科学博士学位;现为新加坡国立大学在职博士后研究员,在 ICCV、ICML、NeurIPS、AAAI、TIFS、TKDE、ACM Computing Surveys 等高水平会议和期刊发表论文 30 余篇,研究方向包括多媒体取证、虚假信息检测等。


