本文共同一作是张翔和曹峻泰。张翔是英属哥伦比亚大学研究生,主要研究兴趣集中在大模型推理和 AI for Science;曹峻泰是英属哥伦比亚大学研究生,主要研究兴趣集中在大模型推理和可解释性研究;本文通讯作者是来自纽约大学石溪分校的助理教授尤晨羽,以及来自 Meta Gen AI 的研究员丁渡鉴。
近年来,大型语言模型(LLM)在自然语言处理领域取得了革命性进展。然而,其底层的 Transformer 架构在处理复杂推理任务时仍有不足。尽管「思维链」(CoT)提示技术提供了一条实用路径,但多数方法依赖通用指令,导致提示工程高度依赖反复试验,缺乏理论指导。
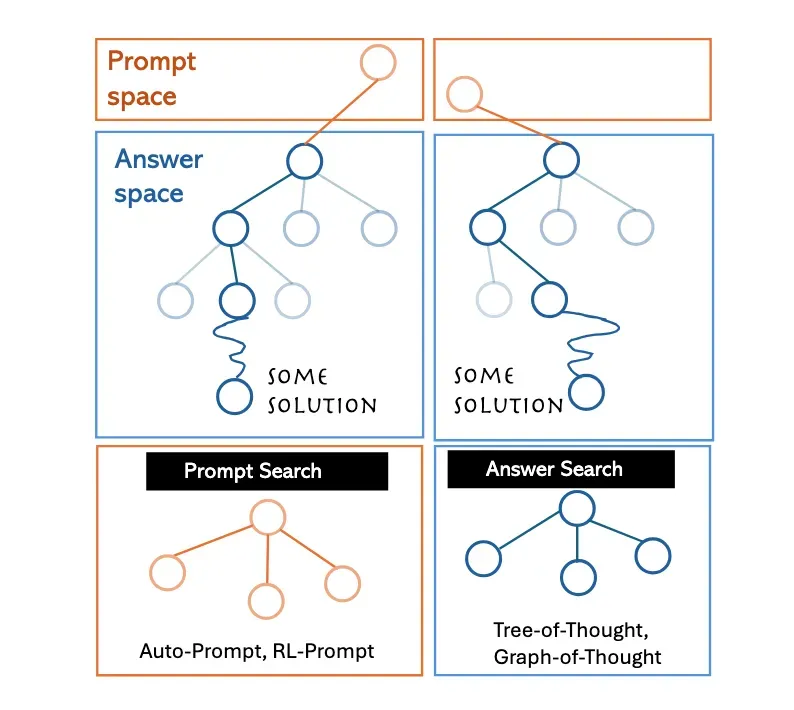
图 1:Prompt 模板深刻影响着答案空间的配置和导航方式。左侧展示了不同的 Prompt(如 Auto-Prompt、RL-Prompt)如何在「Prompt 空间」中进行搜索,而右侧则展示了在特定 Prompt 指导下,如何在「答案空间」中进行搜索以得到解决方案(如 Tree-of-Thought、Graph-of-Thought)。
来自英属哥伦比亚大学、纽约大学石溪分校和浙江大学的研究团队深入剖析了 Prompt 如何在 LLM 的 CoT 推理过程中调控模型内部信息流。这项研究首次构建了一个量化 Prompt 搜索空间复杂度的理论框架,为 LLM 提示工程从经验性的「炼丹」走向科学奠定了基础。

- 论文标题:Why Prompt Design Matters and Works: A Complexity Analysis of Prompt Search Space in LLMs
- 论文链接:https://arxiv.org/abs/2503.10084
- 论文发表:ACL 2025 main(主会)已接收 论文得分 Meta score:4(满分为 5 分)
- 作者信息:Xiang Zhang、Juntai Cao、Jiaqi Wei、Chenyu You、Dujian Ding

图 2:(a) 在没有精心设计 Prompt 的朴素 CoT 中,模型可能生成错误或次优的思考步骤,导致任务失败。(b) 通过最优的 Prompt 设计,可以有效引导模型,使其成功执行任务。(c) 当不采用 CoT 时,模型仅能依赖其 Transformer 架构进行内部推理。(d) Transformer 架构本身只能执行固定且深度有限的计算,难以应对复杂的多步推理。
突破「炼丹」:Prompt 设计走向科学
长期以来,提示工程的有效性似乎带有一丝「玄学」色彩——为何某些提示组合能奇迹般地提升模型性能,而另一些则收效甚微?本研究从理论层面解释了为何某些提示组合能有效提升模型性能。研究团队指出,Prompt 在 CoT 推理过程中扮演着至关重要的「信息选择器」(selectors)角色。
大型语言模型在处理任务时,其内部的隐藏状态(hidden state, h)实际蕴含了极为丰富的信息,包括对任务的理解、中间计算结果、甚至模型自身的「置信度」等。然而,并非所有这些信息都对当前推理步骤同等重要。
正如论文图 3 所示(见下方),CoT 的核心机制,便是将这种复杂的、高维度的内部隐状态 h 中的信息,通过生成自然语言文本的方式,进行「离散化」和「外化」。这些生成的文本步骤随后又被模型重新编码,用于指导下一步的计算,从而近似一种递归计算过程。
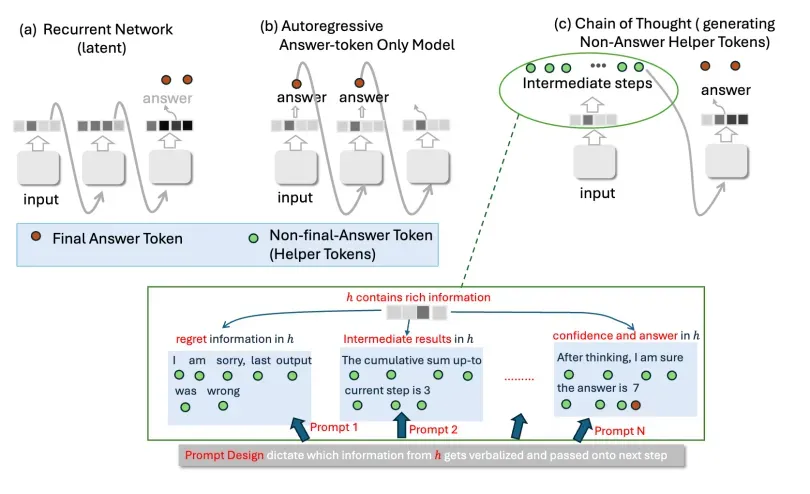
图 3:CoT 通过生成非答案的辅助 Token(中间步骤),近似了循环网络的计算方式。模型内部隐藏状态 h 中蕴含的丰富信息(如先前的错误、中间结果、置信度等)可以通过不同的 Prompt 设计被选择性地提取并言语化。
关键在于,由于每个 CoT 步骤的文本长度有限,模型每一步只能提取并表达 h 中的部分信息,而哪些信息被提取,则是由 Prompt 模板决定的。如图 4 所示,Prompt 模板指导模型提取关键的计算信息,而非关键信息可能被丢弃。
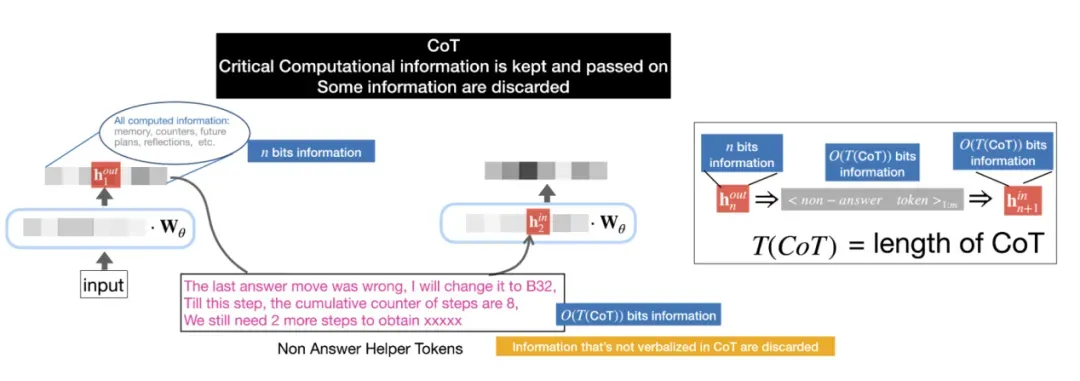
图 4:在 CoT 过程中,并非所有隐藏状态 h 中的信息都会被传递。Prompt 模板指导模型提取关键的计算信息,而其他非关键信息则可能被丢弃。
一个精心设计的提示模板,就如同一个精确的导航仪,它明确地指示模型在 CoT 的每一步中,应该从其完整的隐藏状态 h 中「选择」并「提取」哪些与任务最相关的信息进行「言语化」(verbalization)输出。这一选择过程的复杂性,即「Prompt 空间复杂度」,如论文图 5 所示,取决于隐藏状态 h 中总信息量 n 以及每个 CoT 步骤能提取的信息量 s。
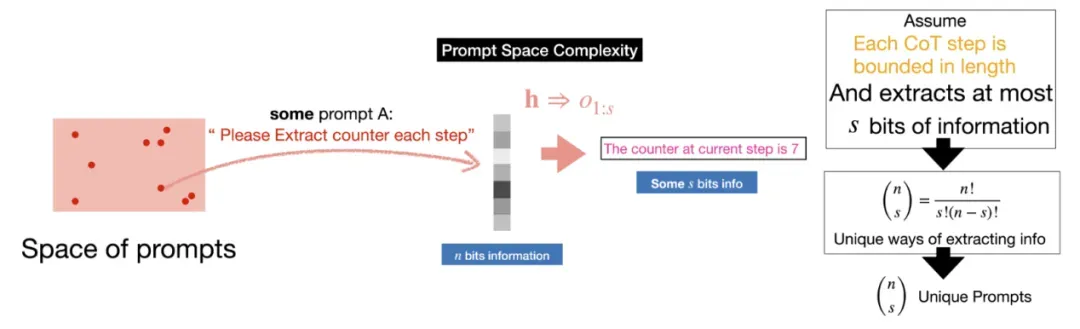
图 5:每个 Prompt 模板都规定了一种从隐藏状态 h 到非答案 Token 的信息言语化方式。Prompt 空间的复杂度可以基于这种信息提取方式的数量来估算。
因此,不同的提示设计定义了不同的信息提取策略,从而在潜在的「答案空间」中塑造出独一无二的推理「轨迹」(trajectory)。论文图 6 直观地描绘了这一过程。
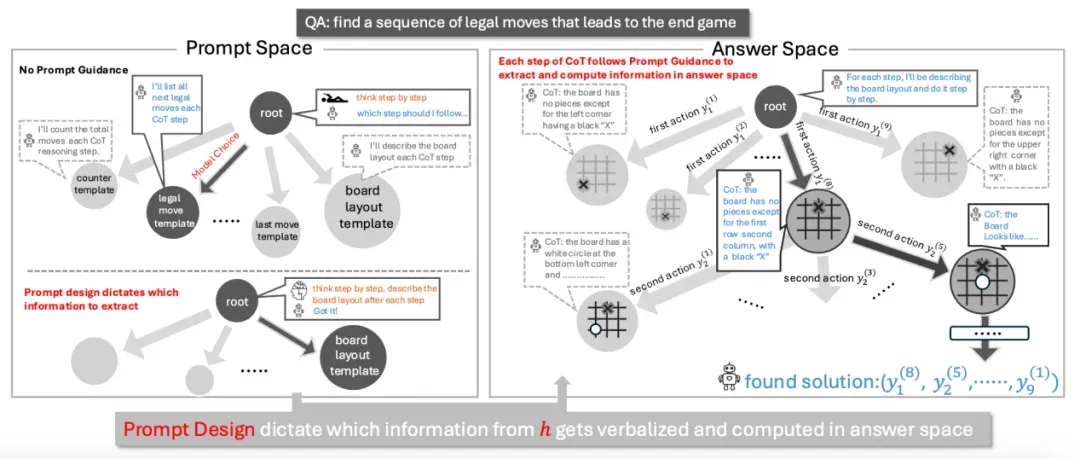
图 6:CoT 的整体空间可以分解为「Prompt 空间」和「答案空间」。在 Prompt 空间中选择不同的 Prompt 设计(例如,决定在象棋推演的每一步是提取「棋盘布局」还是「剩余棋子数」),会直接影响在答案空间中导航并找到解决方案的路径和效率。
简而言之,提示之所以有效,是因为它能够科学地指导模型在复杂的推理链条中,每一步都「抓重点」。
探寻最佳路径:如何科学设计高效提示词?
既然提示设计如此关键,那么我们应如何告别「炼丹式」的反复试验,转而系统性地找到针对特定任务的「最优提示设计」呢?该研究为此提供了一套理论框架和分析思路。
研究者们创新性地将整个 CoT 的推理过程分解为两个相互关联但又有所区别的搜索空间(图 6):「提示空间」(Prompt Space)的搜索和「答案空间」(Answer Space)的搜索。前者关乎如何找到最佳的「思考模板」或「解题策略」(即提示本身),后者则是在选定模板后,如何执行具体的思考步骤以找到最终答案。
寻找最优提示设计的核心,正是在「提示空间」中进行有效导航。那么,一个「最优提示模板」究竟是什么样的呢?根据这项研究,一个优化的提示模板必须能够:
- 明确指引每步输出:精确规定 CoT 推理的每一个中间步骤应该输出什么内容,确保这些内容是后续计算所必需的。
- 聚焦核心信息:在模型隐藏状态 h 所包含的众多信息中(假设总信息量为 n 比特),最优提示应引导模型在每个 CoT 步骤中,识别并提取出对当前推理任务最为关键的、最顶部的 s 比特信息,并将其转化为文本输出,同时舍弃其余的无关或冗余信号。
- 充当「算法蓝图」:一个好的提示模板,实际上是在为特定任务「编码」一套高效的「算法」,它决定了在推理的每一步需要哪些「变量」(信息),以及如何利用这些「变量」来计算下一个状态。
因此,这项工作将寻找最优提示的过程,从一种依赖直觉和运气的尝试,转变为一个可以在理论指导下进行的、对信息提取和利用方式的系统性探索。它为我们指明了方向:要设计出最佳提示,就需要深入理解任务的计算需求,并确保提示能够引导 LLM 在每一步都准确地「抓住」并「用好」解决问题所需的核心信息。
实验证据:精心设计的提示词如何驱动 LLM 推理性能飞跃
为了验证上述理论框架的有效性,研究团队进行了一系列精心设计的实验。他们选取了涵盖不同计算复杂度等级(包括常规 Regular、上下文无关 Context-Free 及上下文敏感 Context-Sensitive 等)的基础推理任务,这些任务本身对计算深度有较高要求,通常超出标准 Transformer 架构的直接处理能力,因而非常依赖 CoT 机制来辅助完成。实验中使用了 gpt-4o-classic 网页版及 gpt-4o mini API,并特别注意通过统一输入格式(如将字符串任务转换为列表格式)等方式,来最小化 Tokenization 等外部因素对实验结果的干扰。
核心实验结果清晰地揭示了以下几点:
「递归计算」的基石作用
实验首先证实了「递归计算」对于复杂推理任务的不可或缺性。如表 1 所示,当 LLM 不使用思维链(CoT)机制时,其在需要多步推理的任务上表现不佳。然而,一旦引入 CoT,赋予模型文本空间「递归计算」的能力,准确率便显著提高。这凸显了 CoT 为 LLM 带来的「类递归」能力的重要性。
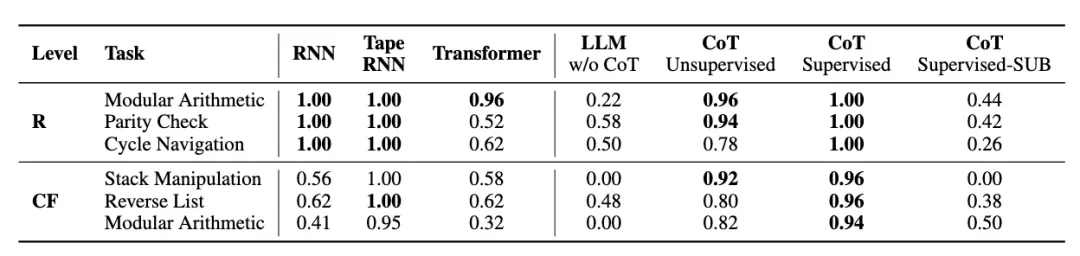
表 1
提示设计的决定性影响——「最优监督」的力量
最为关键的发现是,提示模板(即「思考步骤」的具体设计)的选择,对 LLM 的推理性能起着决定性作用。研究对比了三种情况(见表 1 和表 3):
- 无监督 CoT (Unsupervised CoT):模型自行推导思考步骤。
- 最优监督 CoT (CoT Supervised / S-CoT):研究者提供精心设计的最优步骤模板。
- 次优监督 CoT (CoT Supervised-SUB / S-CoT-SUB):模型使用次优或存在冗余/误导信息的步骤模板。
结果显示,通过 S-CoT 提供理想的步骤模板时,LLM 性能最佳,显著优于无监督 CoT。相反,使用次优监督会导致性能急剧下降。这证实了论文核心观点:答案空间和搜索复杂度受提示空间中模板选择的影响。正确的人类监督(最优提示设计)能引导模型达到最高效的推理状态,可将推理任务性能提升超过 50%。
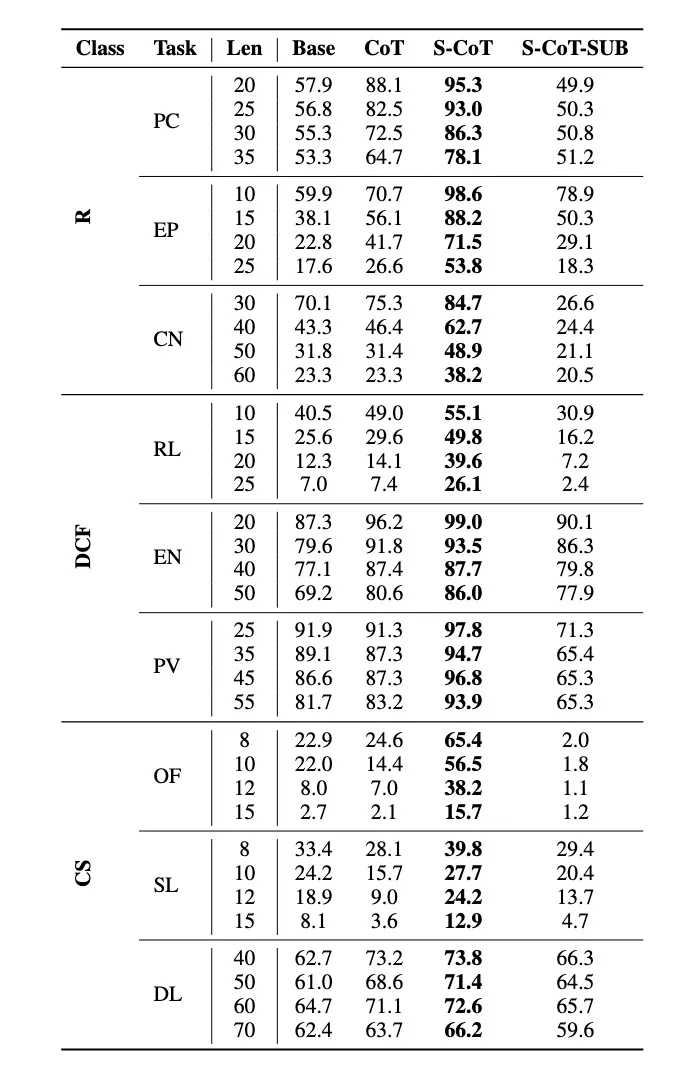
表 3
CoT 变体:辅助「答案空间」导航,但非「提示空间」的解决方案
研究还考察了不同的 CoT 变体,如思维树(ToT)和思维图(GoT)等(见表 2)。结果显示,这些方法能在一定程度上提升朴素 CoT 的性能,例如 GoT 因其自我修正机制表现出较好的准确率增益。
然而,它们的改进主要在于通过更复杂的搜索策略(如多路径探索、自我校验)来纠正计算过程中的「小错误」或探索更多解题路径,而非优化提示模板本身的选择。这意味着,即便 ToT 或 GoT 等高级方法,如果其依赖的底层提示模板本身是次优的,其性能上限依然会受到制约。它们主要解决的是「答案空间」的导航问题,而非「提示空间」的模板选择问题。
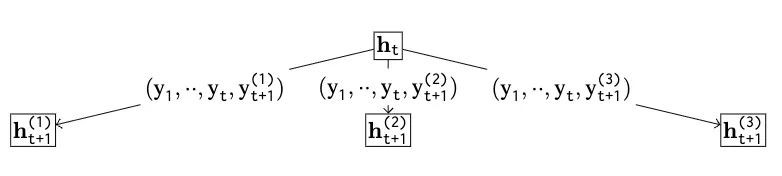
图 8:ToT(思维树)机制通过探索答案空间中的多个分支路径来提升问题解决能力。然而,状态如何转换仍然受到 CoT 步骤模板的制约,这超出了 ToT 本身提供的范畴。
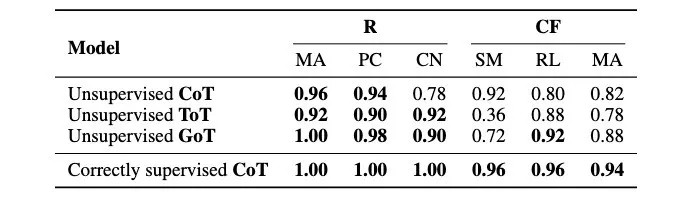
表 2
结论:为高效提示词设计铺路
这项研究首次系统性地探索了提示空间的复杂性,为理解和设计 LLM 的高效提示策略奠定了坚实的理论基础。其核心洞见在于:
- Prompt 作为信息选择器:提示通过从模型的隐藏状态中精确提取与任务相关的特定信息,从而主导并塑造 CoT 的推理过程。
- Prompt 设计至关重要,而非附属:提示的设计并非一项辅助性或锦上添花的工作,而是决定 CoT 推理有效性的核心环节。提示结构的微小调整可能带来模型性能的巨大飞跃或骤降。
- 通用 Prompt 的固有局限:简单依赖模型自我引导的朴素 CoT 策略(例如,万能的「think step by step」)可能会严重限制模型在复杂任务上的表现潜力。
- 最优 Prompt 探索的巨大价值:实验清晰证明,通过系统性的最优提示搜索与设计,LLM 在推理任务上的性能可以获得超过 50% 的显著提升。
这项工作为我们理解和提升 LLM 基于 Prompt 的推理能力提供了宝贵的理论框架和实践指引,并深刻预示着在未来的 LLM 应用浪潮中,科学化的提示工程与人类的智慧监督将扮演不可或缺的关键角色。


