 本文作者来自于上海人工智能实验室与新加坡南洋理工大学,分别是张凡、田淑琳、黄子琪,指导老师是乔宇老师与刘子纬老师。
本文作者来自于上海人工智能实验室与新加坡南洋理工大学,分别是张凡、田淑琳、黄子琪,指导老师是乔宇老师与刘子纬老师。怎么快速判断一个生成模型好不好?
最直接的办法当然是 —— 去问一位做图像生成、视频生成、或者专门做评测的朋友。他们懂技术、有经验、眼光毒辣,能告诉你模型到底强在哪、弱在哪,适不适合你的需求。
但问题是:
朋友太忙,没法一条条帮你看;
你问题太多,不只是想知道「好不好」,还想知道「哪里不好」「为啥好」「适不适合我」。
你需要一位专业、耐心、随叫随到的评估顾问。
于是,来自上海人工智能实验室 & 南洋理工大学 S-Lab 的研究者合作研发了一个 AI 版本的「懂行朋友」——Evaluation Agent。
它不仅评测,还能听你提问、为你定制测试、写出人类专家一样的分析报告。
你问「它拍古风视频怎么样?」,它就给你规划方案;
你问「懂光圈焦距吗?」,它就设计针对测试;
你想知道适不适合你,它还真能给出解释。
这就是视觉生成模型评估的新范式:
Evaluation Agent 入选 ACL 2025 主会 Oral 论文。

论文:https://arxiv.org/abs/2412.09645
代码:https://github.com/Vchitect/Evaluation-Agent
网页:https://vchitect.github.io/Evaluation-Agent-project/
论文标题:Evaluation Agent: Efficient and Promptable Evaluation Framework for Visual Generative Models
为什么选择 Evaluation Agent?
1. 可定制:你说关注点,它来定方案。
不同人对生成模型有不同期待 —— 风格?多样性?一致性?
只需用自然语言说出你的关注点,Evaluation Agent 就能:
自动规划合适的评估流程
根据中间结果灵活调整评估方向
针对性地深入分析你关心的能力维度
真正实现「按需评估」,服务你的具体任务。
2. 高效率:更少样本,评得更快
传统评估动辄需要几千张样本,Evaluation Agent 通过多轮交互式评估与智能采样策略,大幅减少样本数量。整体评估过程的耗时可以压缩到传统方法的 10% 左右,尤其适合在迭代开发中快速反馈。
3. 可解释:让评估结果说人话
结果不仅是表格和数字,Evaluation Agent 会以自然语言生成分析报告,不仅涵盖模型能力的全面总结,还能指出模型的局限性和改进方向。
4. 可扩展:支持不同任务、工具、指标的集成
Evaluation Agent 是一个开放框架,支持集成新评估工具和指标,适用于不同的视觉生成任务(如图片生成和视频生成)。
框架工作原理
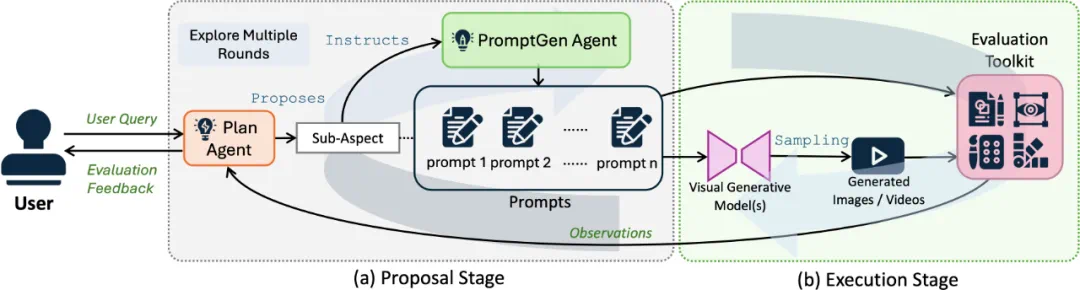
Evaluation Agent 框架主要由两个阶段组成:
1. 提案阶段(Proposal Stage)
Plan Agent:分析用户需求,动态规划评估路径。
PromptGen Agent:为每个子任务生成专属的评估提示(prompt)。
这一阶段的目标是:根据你的关注点,量身定制评估方案。
2. 执行阶段(Execution Stage)
框架利用视觉生成模型生成内容,并通过相应评估工具进行质量分析。
视觉生成模型:根据上阶段设计的 prompt 生成样本
评估工具包:根据提案阶段的规划选用合适的工具对采样内容进行评估
3. 动态多轮交互
评估不是一次性完成的。Execution 阶段的每一轮评估结果,都会反馈给 Proposal 阶段,用于优化后续 prompt 和任务设置。通过这种多轮协同,Evaluation Agent 实现了对模型能力的动态、深入评估。
结果展示
1. 对比传统评测框架

视频生成模型评测效率上与 VBench 评测框架的对比

图片生成模型评测效率上与 T2I-CompBench 评测框架的对比
研究团队在图片生成任务(T2I)和视频生成任务(T2V)上对 Evaluation Agent 进行了全面验证。结果表明,其评估效率显著高于现有基准框架(如 VBench、T2I-CompBench),相较于传统的评测框架节省了 90% 以上的时间,且评估结果具有较高一致性。
2. 用户开放式评估场景

对用户开放问题评估的部分样例
Evaluation Agent 不仅能够高效评估模型的表现,还能灵活处理用户提出的个性化评估需求,例如:
模型能否生成特定历史场景的高质量视频?
模型是否理解并能应用焦距、光圈、ISO 等摄影概念?
在处理用户的开放式查询时,Evaluation Agent 展现了卓越的灵活性和深度。它能够根据用户的定制需求,系统地探索模型在特定领域的能力,从基本问题开始,逐步动态深入,最终通过自然语言详细分析和总结评估结果。
例如,对于问题「模型是否能够在保持原始风格的同时生成现有艺术作品的变体?」,下面展示了完整的评估过程。
在 Evaluation Agent 工作中,开放式用户评估问题数据集 (Open-Ended User Query Dataset) 是检验框架开放式评估能力的重要组成部分。该数据集为系统提供了多样化的评估场景,特别是在面临复杂的、用户特定的评估需求时,能够展现出系统的灵活性和动态评估能力。
开放式用户评估问题数据集首先通过用户调研收集了来自用户的一系列针对模型能力的开放问题。随后,经过数据清洗、过滤、扩展以及标签打标等处理,最终完成了数据集的构建。该数据集涵盖了广泛的评估维度,能够全面评估模型的各项能力。下图展示了该数据集在不同类别下的统计分布。
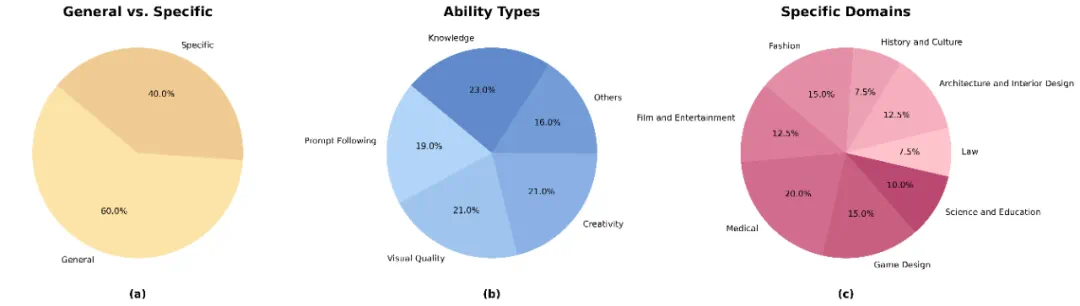
开放式用户评估问题数据集统计分布
前景与进一步计划
Evaluation Agent 的初步研究已经证明其在视觉生成模型评估中的高效性和灵活性。未来,该方向可能在以下领域进一步拓展和深入研究:
1. 扩展评估能力,涵盖更多视觉任务
目前 Evaluation Agent 已适用于图像和视频生成模型,未来将扩展到 3D 内容生成、AIGC 视频编辑等更复杂的生成任务。
增加对多模态 AI(如结合文本、音频、视频的生成模型)的评估能力,探索不同 AI 模型在跨模态任务中的表现。
2. 优化开放式评估机制
进一步完善开放式用户评估问题数据集,提升 Evaluation Agent 对复杂、抽象概念(如风格迁移、艺术融合、情感表达等)的理解和评估能力。
引入强化学习机制,使 Evaluation Agent 能够利用基于用户反馈的数据实现自我优化,提高评估的精准性和适应性。
3. 从自动评测迈向智能推荐
未来,该框架可拓展用于视觉生成模型的个性化推荐,依据用户的具体需求自动匹配最合适的生成模型,并生成详尽的评估报告。
研究如何利用众包数据,收集不同领域的专业人士(如设计师、摄影师、影视制片人)对 AI 生成内容的反馈,以提升评估框架在多领域场景下的适应性和泛化能力。
总结
Evaluation Agent 提出了一种高效、灵活、可解释的视觉生成模型评估新范式。它突破了传统评估方式的限制,能够根据用户需求动态分析模型表现,为生成式 AI 的理解与优化提供支持。无论关注的是准确性、多样性,还是风格与创意,这一框架都能给出清晰、有针对性的评估结果。
研究团队希望这一方法能为视觉生成模型的评估带来新的思路,推动更智能、更灵活的评估体系发展。


