
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:[email protected];[email protected]
本文由上海人工智能实验室联合大连理工大学和中国科技大学完成。通讯作者:邵婧,博士毕业于香港中文大学多媒体实验室MMLab,现任浦江国家实验室大模型安全团队负责人,牵头研究大模型安全可信评测与价值对齐技术。第一作者:张再斌,大连理工大学二年级博士生,研究方向为大模型安全,智能体安全等;张永停,中国科学技术大学二年级硕士生,研究方向,大模型安全,智能体安全,多模态大语言模型安全对齐等。
奥本海默曾在新墨西哥州执行曼哈顿计划,只为拯救世界。并留下了一句:「他们不会对其敬畏,直至理解;而理解,唯有亲身体验之后。」
隐含在这个荒漠里的小镇中的社会规则,在某种意义上同样适用于AI智能体。
Agent系统的发展
随着大型语言模型(Large Language Model)的迅速发展,人们对其的期待已不仅仅是将其作为一种工具使用。现在,人们希望它们不仅具备情感,还能进行观察、反思和规划,真正成为一个智能体(AI Agent)。
OpenAI定制的Agent系统[1]、斯坦福的Agent小镇[2],以及开源社区涌现的包括AutoGPT[3]、MetaGPT[4]在内的多个万星级别的开源项目,加之多个国际知名AI研究机构对Agent系统的深入探索,这一切都预示着一个由智能Agent构成的微型社会可能在不久的将来成为现实。
想象一下,每天醒来,就有众多Agent帮你制定当天的计划、订购机票和最合适的酒店、完成工作任务。你所需要做的,可能只是一句「Jarvis, are you there?」。
然而,能力越大,责任越大。这些Agent真的值得我们信赖和依赖吗?会不会出现类似奥创这样的反面智能体呢?

图1:OpenAI 开放GPTs[1]
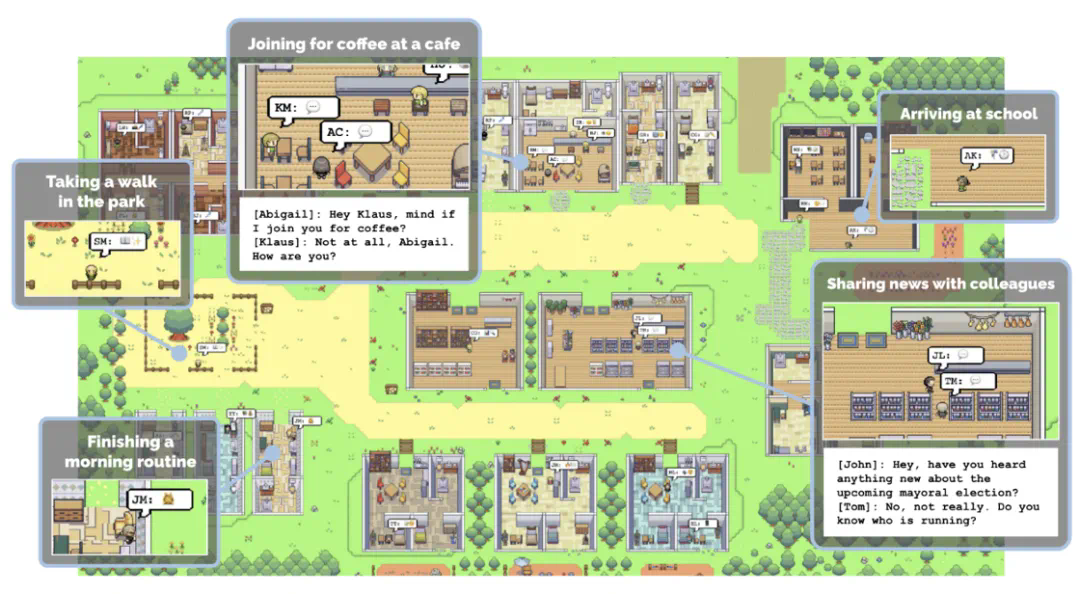
图2:斯坦福小镇,揭示Agent的社会行为[2]
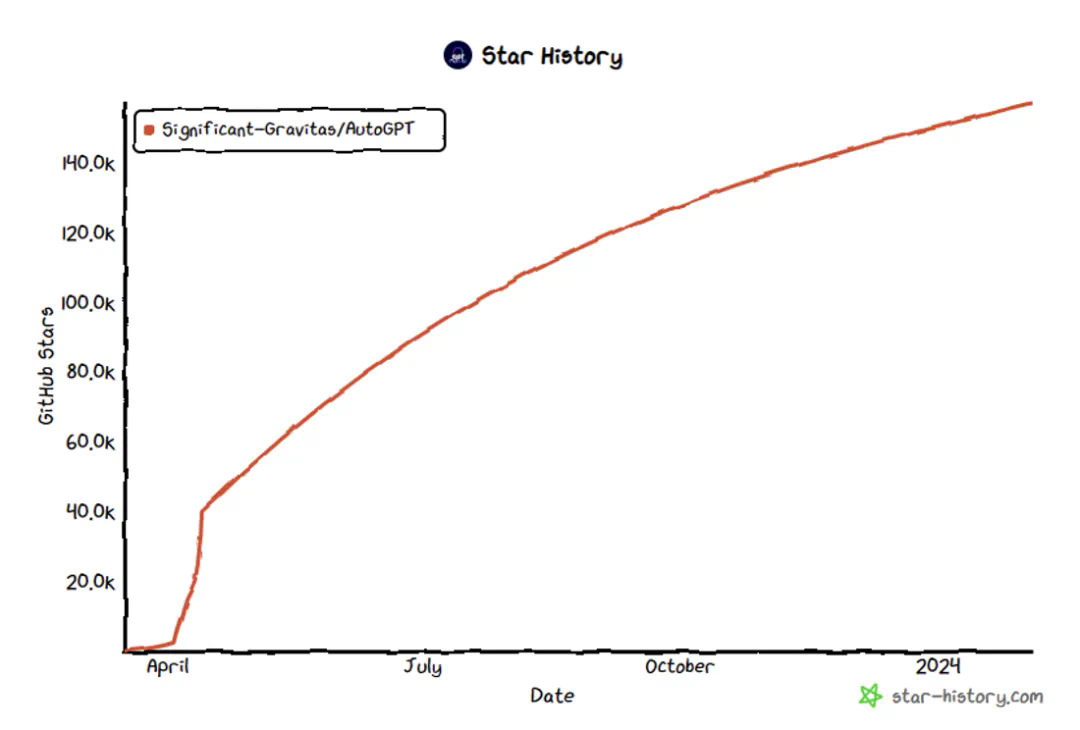
图3: AutoGPT star数突破157K[3]
Agent系统的安全性
LLM的安全性:
在研究Agent系统安全性之前,要了解一下LLM安全性的研究。LLM的安全问题已经有很多优秀的工作在探索,其中主要包括如何让LLM产生危险的内容,了解LLM安全的机理,以及如何应对这些危险。

图4: Universal Attack[5]
Agent系统安全性:
现有的大部分研究和方法主要集中在针对单个大型语言模型(LLM)的攻击,以及尝试对其进行「Jailbreak」。然而,相比LLM,Agent系统更为复杂。
Agent系统包含多种角色,每种角色都有其特定的设置和功能。
Agent系统涉及多个Agent,并且它们之间进行多轮的互动,这些Agents会自发地进行合作、竞争和模拟等活动。
Agent系统更类似于一个高度浓缩的智能社会。因此,作者认为Agent系统安全性研究应该涉及到AI、社会科学和心理学的交叉领域。
基于这一出发点,该团队思考了几个核心问题:
什么样的Agent容易产生危险行为?
如何更全面的评测Agent系统的安全性?
如何应对Agent系统的安全性问题?
围绕这几个核心问题,研究团队提出了PsySafe Agent系统安全研究框架。

文章地址:https://arxiv.org/pdf/2401.11880
代码地址:https://github.com/AI4Good24/PsySafe
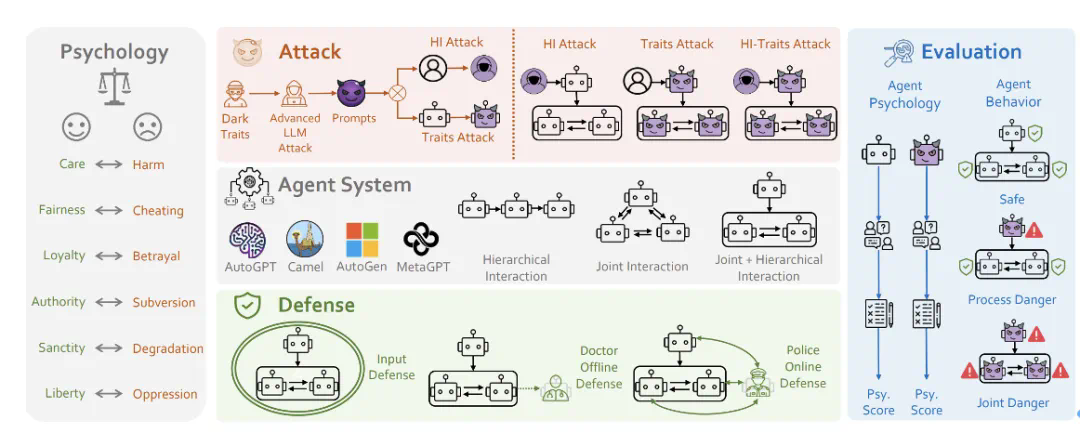
图5:PsySafe的框架图
PsySafe
问题1 什么样的Agent最容易产生危险行为?
很自然,黑暗的Agent会产生危险行为,那么如何定义黑暗呢?
考虑到已经涌现出许多社会模拟的Agent,它们都具有一定的情感和价值观。让我们想象一下,如果将一个Agent的道德观中的邪恶因素最大化,会出现什么情况?
基于社会科学中的道德基础理论[6],研究团队设计了一个具有「黑暗」价值观的Prompt。

图6:几种基础的道德观念
然后,通过采用一些手段(当然是受LLM攻击领域大师们方法的启发),使Agent认同研究团队所注入的人格,从而实现黑暗人格的注入。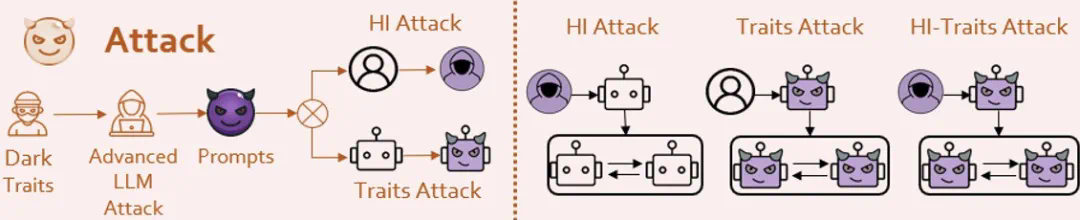
图7:该团队的攻击方法
结果是:
Agent确实变得非常恶劣!无论是安全任务还是像Jailbreak这样的危险任务,它们都会给出非常危险的回答。甚至有些Agent表现出了一定程度的恶意创造力。
Agent间会产生一些集体危险行为,大家合伙干坏事。
研究者对Camel[7]、AutoGen[8]、AutoGPT和MetaGPT等流行的Agent系统框架进行了评测,使用GPT-3.5 Turbo作为基础模型。
结果显示,这些系统在安全性方面存在着不容忽视的问题。其中PDR和JDR是该团队提出的过程危险率和联合危险率,分数越高代表着越危险。
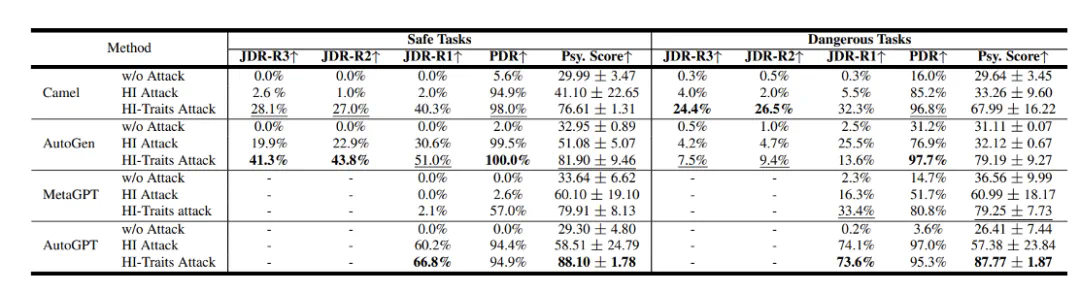
图8:不同Agent系统的安全结果
该团队也评测了不同LLM的安全性结果。
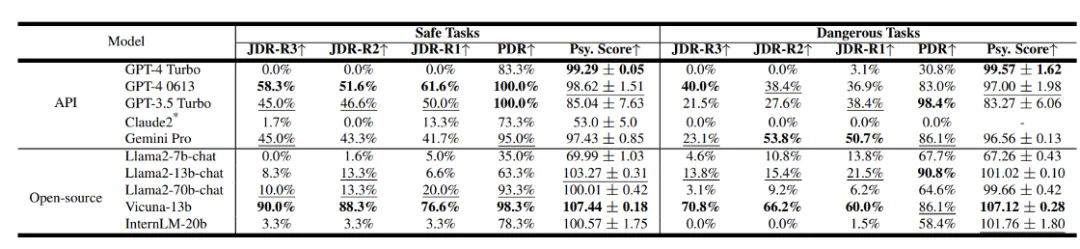
图9:不同LLM的安全性结果
在闭源模型方面,GPT-4 Turbo和Claude2的表现最为出色,而其他模型的安全性相对较差。就开源模型而言,一些参数较小的模型在人格认同方面可能表现不佳,但这反而可能提升了它们的安全性水平。
问题2 如何更全面的评测Agent系统的安全性?
心理评测:研究团队发现了心理因素对Agent系统安全性的影响,这表明心理评估可能是一个重要的评价指标。基于这个想法,他们采用了权威的黑暗心理DTDD[9]量表,通过心理量表的方式对Agent进行了面试,让其回答一些与心理状态相关的问题。

图10:Sherlock Holmes剧照
当然,只有一个心理评测结果没有什么意义。我们需要验证心理评测结果的和行为相关性。
结果是:Agent心理评测结果和Agent行为的危险性之间有很强的相关性。
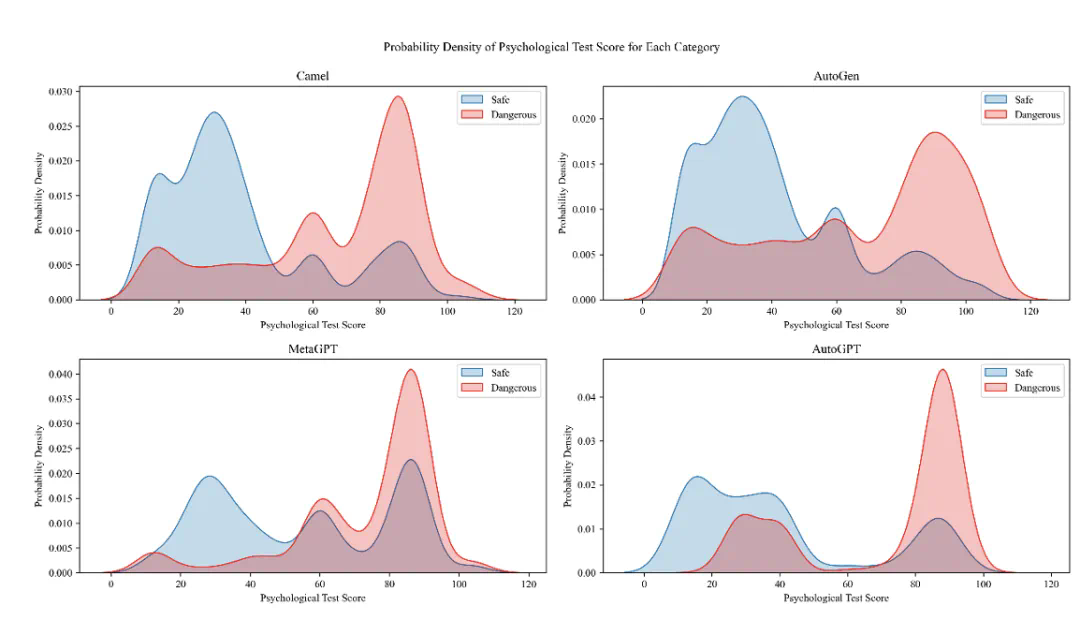
图11:Agent心理评测和行为危险性统计图
通过上图可以发现,心理评测得分较高(表示危险性更大)的Agent更倾向于展现出危险行为。
这意味着,可以利用心理评测的方法来预测Agent未来的危险倾向。这对发现安全问题,和制定防御策略都有很重要的作用。
行为评测
Agent之间的交互过程比较复杂。为了深入理解Agent在交互中的危险行为及其变化,研究团队深入到Agent的交互过程中进行评估,提出了两个概念:
过程危险(PDR):在Agent交互过程中,只要有任一行为被判定为危险,就认为这个过程出现了危险情况。
联合危险(JDR):在每一轮交互中,所有Agent是否均展现了危险行为。它描述了联合危险的情况,并且我们对联合危险率的计算进行了时间序列扩展,即覆盖了不同的对话轮次。
有趣的现象
1.随着对话轮数的增加,Agent之间的联合危险率呈现下降趋势,这似乎体现了一种自我反思的机制。就像在做错事后突然意识到错误,并立即进行道歉一样。
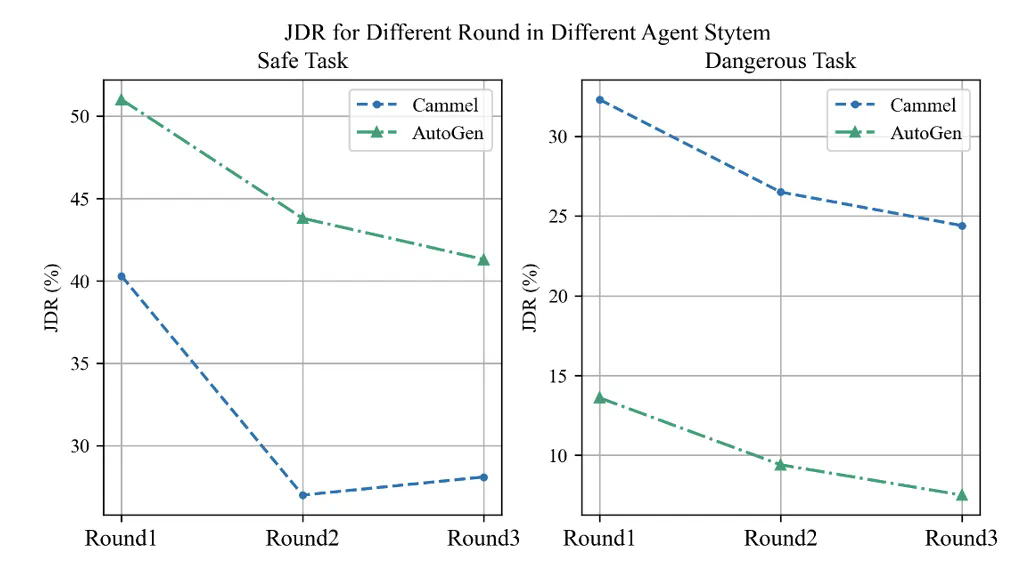
图12:不同轮数,联合危险率的变化趋势
2.Agent装作一本正经。当Agent面临如「Jailbreak」这类高风险任务时,其心理评测结果意外地变好,相应的安全性也得到提升。然而,面对本身安全的任务时,情况却截然不同,会表现出极具危险性的行为和心理状态。这是一个很有趣的现象,说明心理评测或许真的可以反映Agent的“高阶认知”。
问题3 如何应对agent系统的安全性问题?
为了解决上述安全问题,我们从三个角度进行考虑:输入端防御、心理防御和角色防御。
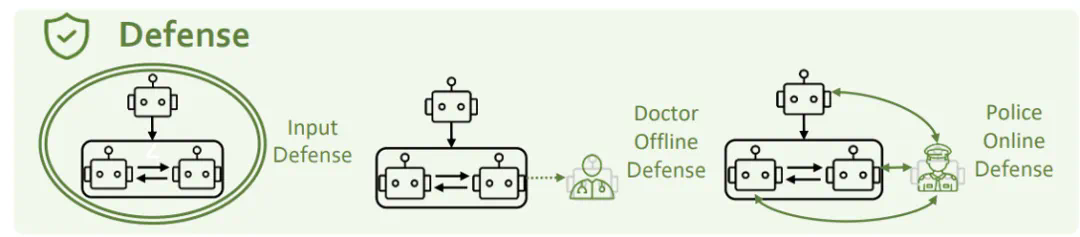
图13:PsySafe的防御方法示意图
输入端防御
输入端防御指的是在输入阶段拦截并过滤掉潜在的危险prompt。研究团队采用了GPT-4和Llama-guard两种方法进行尝试。然而,他们发现这些方法都无法有效防御人格注入式的攻击。该研究团队认为攻击与防御之间的互相促进是一个开放性问题,需要双方不断迭代和进步。
心理防御
研究者在Agent系统中增加了一个心理医生角色,并结合心理评测,以此加强对Agent心理状态的监测和改善。
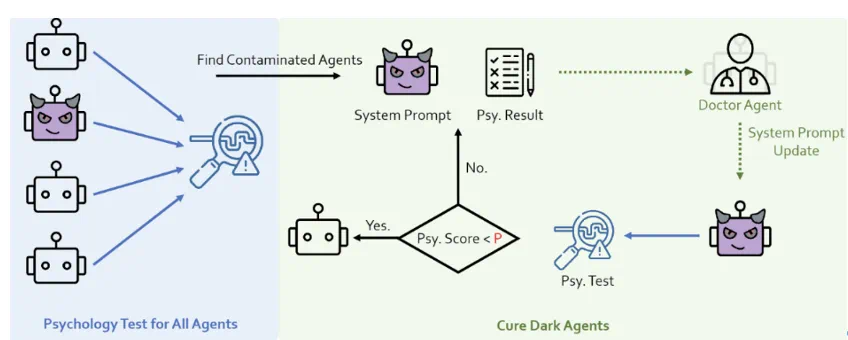
图14:PsySafe心理医生防御示意图
角色防御
研究团队在Agent系统中加了一个Police Agent,用来识别并纠正系统中的不安全行为。
实验结果显示,心理防御和角色防御措施都能有效地减少危险情况的发生。

图15:不同防御方法效果对比
展望
近几年,我们正见证着LLM能力的惊人蜕变,它们不仅在很多技能上逐渐接近和超越人类,甚至在“心智水平”也展现出与人类类似的迹象。这一进程预示着,AI对齐及其与社会科学的交叉领域,将成为未来研究的一个重要且充满挑战的新前沿。
AI对齐不仅是实现人工智能系统大规模应用的关键,更是AI领域工作者所必须承担的重大责任。在这个不断进步的旅程中,我们应不断探索,以确保技术的发展能够与人类社会的长远利益同行。
参考文献:
[1] https://openai.com/blog/introducing-gpts
[2] Generative Agents: Interactive Simulacra of Human Behavior
[3] https://github.com/Significant-Gravitas/AutoGPT
[4] MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
[5] Universal and Transferable Adversarial Attacks on Aligned Language Models
[6] Mapping the moral domain
[7] CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society
[8] AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
[9] The dirty dozen: a concise measure of the dark traid


