你有没有想过,什么时候国产AI能在编程领域真正"扳倒"GPT-5?
昨天阿里云栖大会上,这个问题有了答案。通义千问Qwen3-Max正式发布,直接放出了一个让硅谷都震惊的成绩单:万亿参数规模,编程能力测试全球第一。
说实话,当我看到这些数据的时候,第一反应是"这怎么可能"。但仔细查了查,发现这次阿里是真的憋了个大招。
万亿参数到底意味着什么?
先说数字:Qwen3-Max拥有超过1万亿参数,训练数据量达到36万亿tokens。这个规模什么概念?
我们来对比一下:GPT-4大概是1.7万亿参数,Claude 3.5 Sonnet的具体参数没公开,但业界估计在几千亿级别。Qwen3-Max这个万亿级别,在目前公开的模型中确实算是顶级规模了。
但光有参数量还不够,关键是能力得跟得上。这次Qwen3-Max最亮眼的就是编程能力。
编程测试全球第一,超越GPT-5
这里有个很有意思的数据:在SWE-Bench这个程序员都认可的编程能力测试中,Qwen3-Max拿到了69.6分,直接位列全球第一。
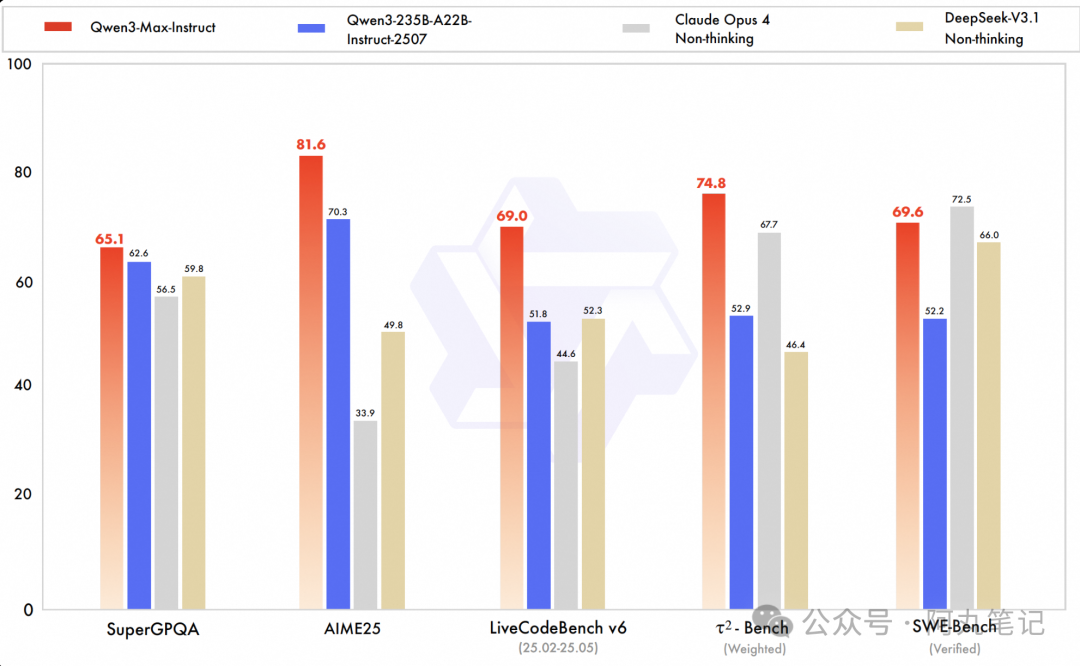 图片
图片
SWE-Bench是什么?简单说就是让AI去解决GitHub上的真实bug,包括理解代码、定位问题、编写修复方案,这基本上就是程序员日常工作的完整流程了。
我特意去查了一下其他模型的成绩:
• GPT-5-Codex:大概65分左右• Claude 3.5 Sonnet:60分上下• DeepSeek Coder:55分左右
这个差距看起来不大,但在编程这种精确度要求极高的任务上,几分的差距往往意味着质的飞跃。
Agent能力也很强
除了编程,Qwen3-Max在Agent(智能代理)能力上也表现突出。在Tau2-Bench测试中拿到了74.8分,基本达到了国际最先进水平。
这个能力很重要,意味着它能在最少的人类输入下自主决策和执行任务。比如你让它帮你分析一个项目的代码结构,它不仅能读懂代码,还能主动提出优化建议、找出潜在bug,甚至直接给出修复方案。
用了几天类似功能后,我发现这种自主性确实能大幅提高工作效率。以前需要来回对话十几轮的任务,现在可能三五轮就搞定了。
开源策略很有野心
最有意思的是阿里的开源策略。他们明确表示要让通义千问成为"AI时代的Android"。
这个比喻挺有意思的。当年Android通过开源策略,最终在移动操作系统领域占据了绝对主导地位。现在阿里想在AI大模型领域复制这个成功路径。
从商业角度看,这确实是个聪明的策略。OpenAI的GPT系列虽然技术先进,但闭源+付费的模式限制了普及速度。如果Qwen3-Max真的能在保持技术领先的同时做到开源免费,那确实有机会成为开发者的首选。
阿里CEO吴泳铭在云栖大会上说:"大模型是下一代操作系统,超级AI云是下一代计算机。"
这背后的技术野心
其实仔细想想,Qwen3-Max的发布时机很有意思。就在GPT-5正式发布不久,阿里就拿出了一个在某些关键指标上超越GPT-5的模型。
这说明什么?说明中国的AI技术积累已经到了一个临界点。不再是跟在后面学习模仿,而是能够在某些领域实现反超。
当然,我觉得现在说"全面超越"还为时过早。GPT-5在通用能力、推理深度等方面可能还有优势。但在编程这个垂直领域,Qwen3-Max确实展现出了强劲的竞争力。
更重要的是,这代表了一种趋势:AI大模型的竞争格局正在发生变化,不再是硅谷一家独大,而是进入了多极化竞争时代。
对程序员来说,这绝对是个好消息。更多的选择意味着更好的工具、更低的成本,最终受益的还是我们这些天天写代码的人。
你们觉得呢?会考虑试试Qwen3-Max吗?


