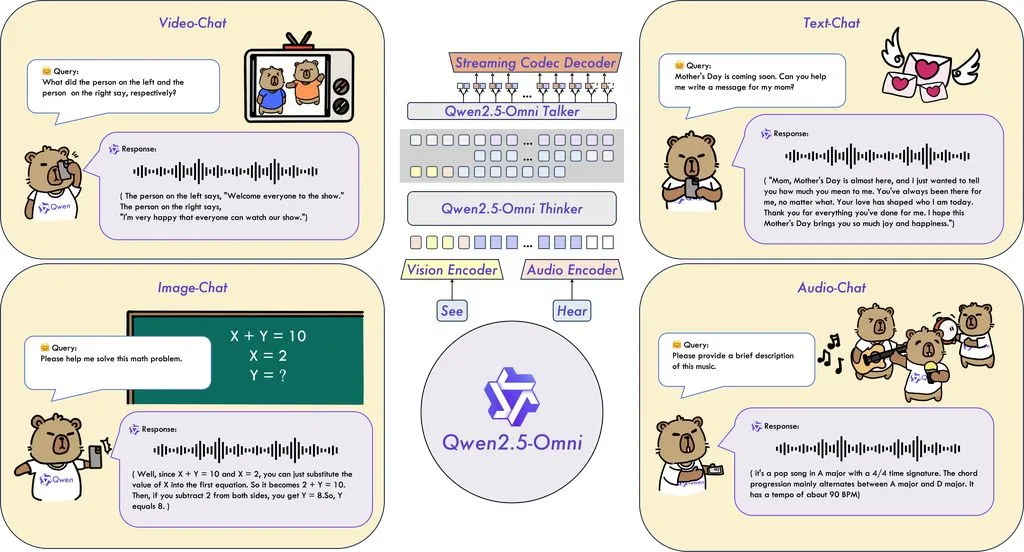
阿里巴巴持续发力 AI 领域,其 Qwen 团队于 3 月发布 Qwen2.5-Omni-7B 模型后,昨日(4 月 30 日)再次发布 Qwen2.5-Omni-3B,目前可以在 Hugging Face 上开放下载。
AI在线注:这款 3B 参数模型是其 7B 旗舰多模态模型的轻量版本,专为消费级硬件设计,覆盖文本、音频、图像和视频等多种输入功能。
团队表示,尽管参数规模缩小,3B 版本在多模态性能上仍保持了 7B 模型的 90% 以上,尤其在实时文本生成和自然语音输出方面表现亮眼。
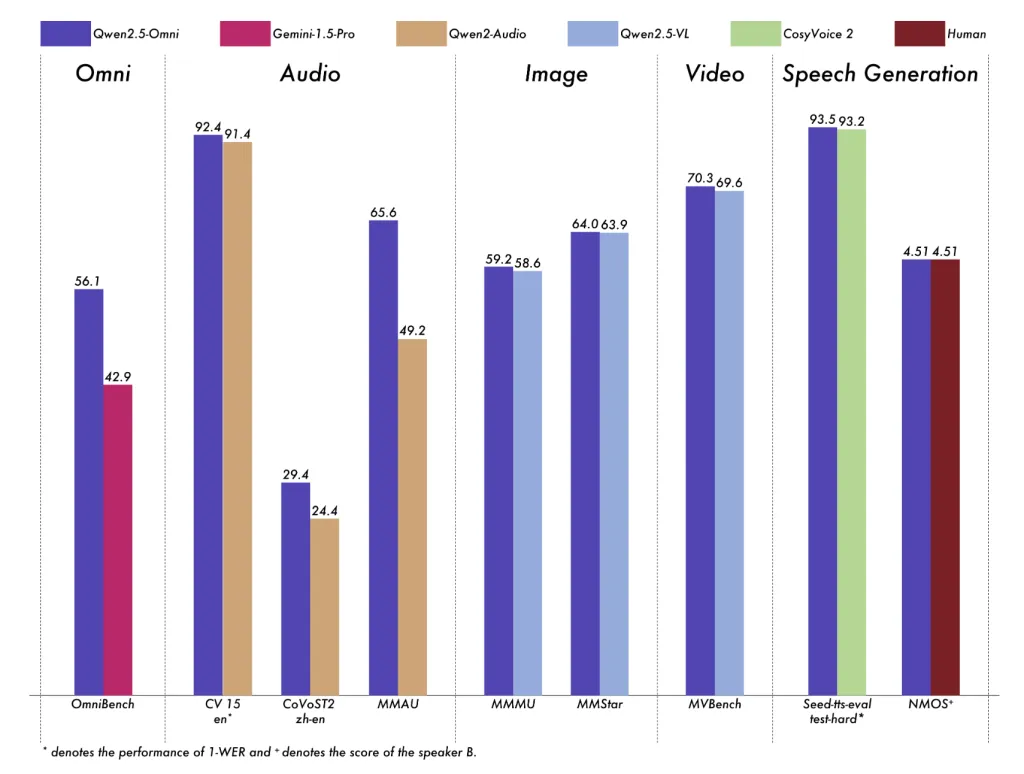
基准测试显示,其在视频理解(VideoBench: 68.8)和语音生成(Seed-tts-eval test-hard: 92.1)等任务中接近 7B 模型水平。

Qwen2.5-Omni-3B 在内存使用上的改进尤为突出。团队报告称,处理 25,000 token 的长上下文输入时,该模型 VRAM 占用减少 53%,从 7B 模型的 60.2 GB 降至 28.2 GB。
这意味着该模型可在 24GB GPU 上运行,无需企业级 GPU 集群支持,可以在高端台式机和笔记本电脑上运行。
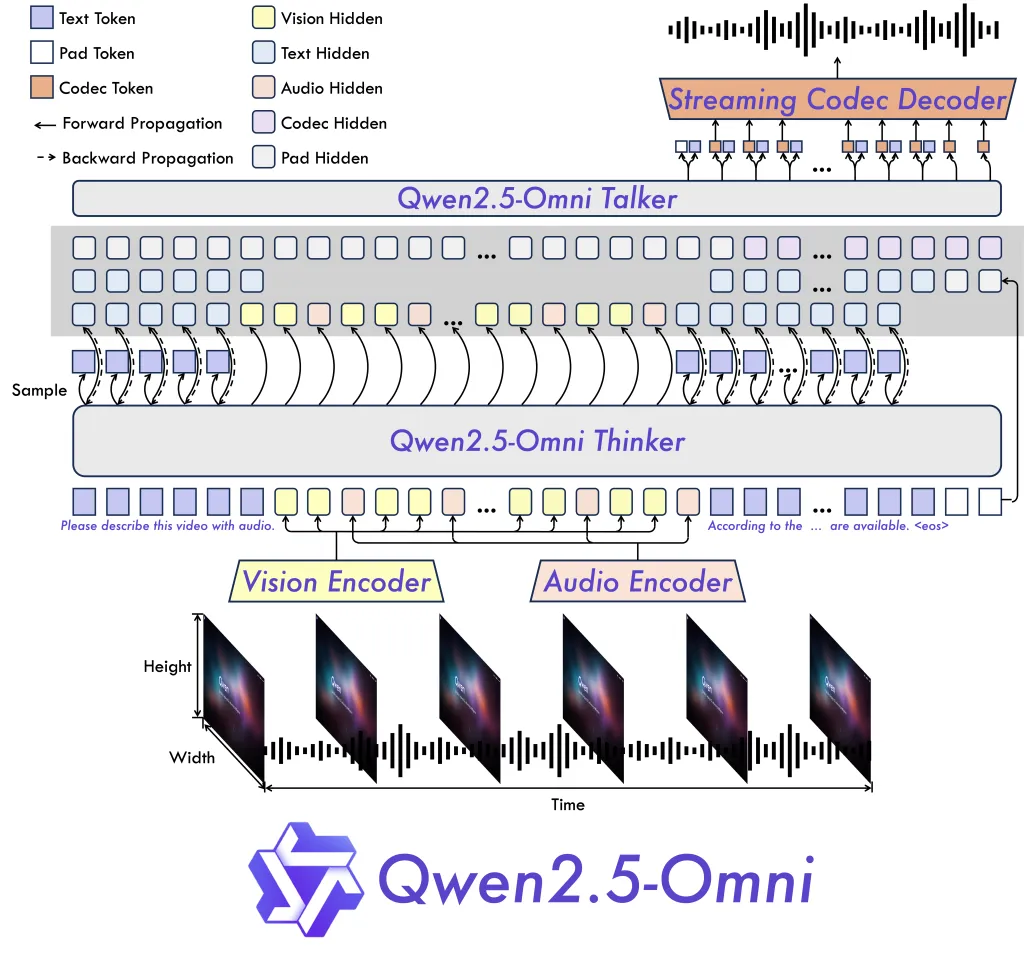
其架构创新,如 Thinker-Talker 设计和定制位置嵌入方法 TMRoPE,确保了视频与音频输入的同步理解。此外,模型支持 FlashAttention 2 和 BF16 精度优化,进一步提升速度并降低内存消耗。
Qwen2.5-Omni-3B 的使用受到严格限制。根据许可条款,该模型仅限研究用途,企业若想开发商业产品,必须先从阿里巴巴 Qwen 团队获取单独许可,意味着该模型非直接生产部署,定位更偏向于测试和原型开发。
参考
Hugging Face
GitHub 页面
魔搭社区
Multimodal AI on Developer GPUs: Alibaba Releases Qwen2.5-Omni-3B with 50% Lower VRAM Usage and Nearly-7B Model Performance
Qwen swings for a double with 2.5-Omni-3B model that runs on consumer PCs, laptops


