ThinkSound 首次将 CoT(Chain-of-Thought,思维链)应用到音频生成领域,让 AI 学会一步步“想清楚”画面事件与声音之间的关系,从而实现高保真、强同步的空间音频生成 —— 不只是“看图配音”,而是真正“听懂画面”。
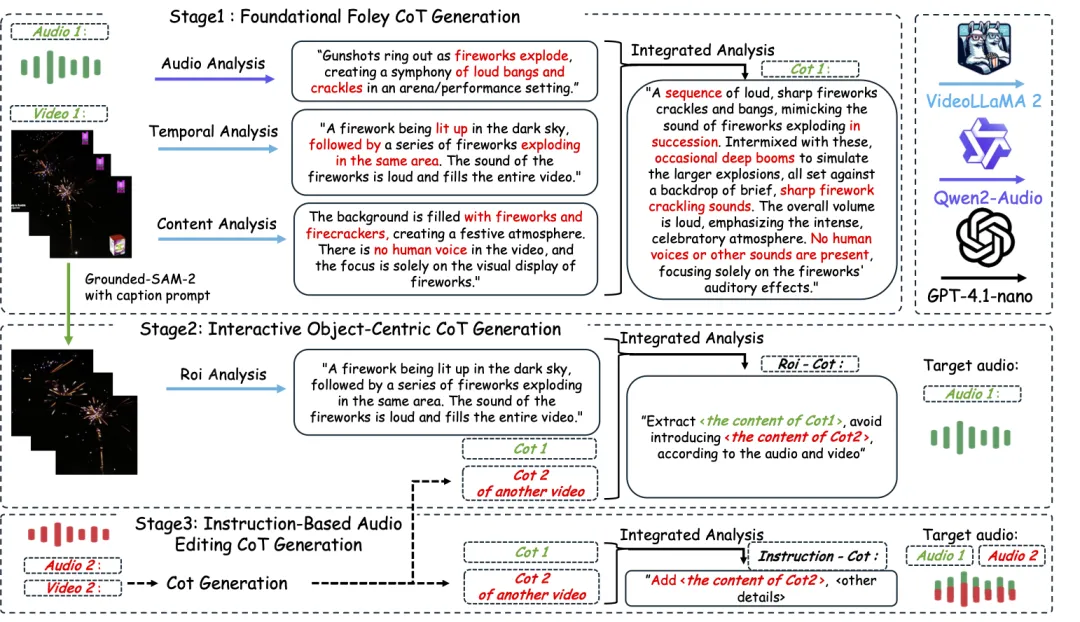
为了让 AI 学会“有逻辑地听”,通义实验室语音团队构建了首个支持链式推理的多模态音频数据集 AudioCoT。
AudioCoT 融合了来自 VGGSound、AudioSet、AudioCaps、Freesound 等多个来源的 2531.8 小时高质量样本。这些数据覆盖了从动物鸣叫、机械运转到环境音效等多种真实场景,为模型提供了丰富而多样化的训练基础。为了确保每条数据都能真正支撑 AI 的结构化推理能力,研究团队设计了一套精细化的数据筛选流程,包括多阶段自动化质量过滤和不少于 5% 的人工抽样校验,层层把关以保障数据集的整体质量。
在此基础上,AudioCoT 还特别设计了面向交互式编辑的对象级和指令级样本,以满足 ThinkSound 在后续阶段对细化与编辑功能的需求。
ThinkSound 由两个关键部分组成:一个擅长“思考”的多模态大语言模型(MLLM),以及一个专注于“听觉输出”的统一音频生成模型。正是这两个模块的配合,使得系统可以按照三个阶段逐步解析画面内容,并最终生成精准对位的音频效果 —— 从理解整体画面,到聚焦具体物体,再到响应用户指令。
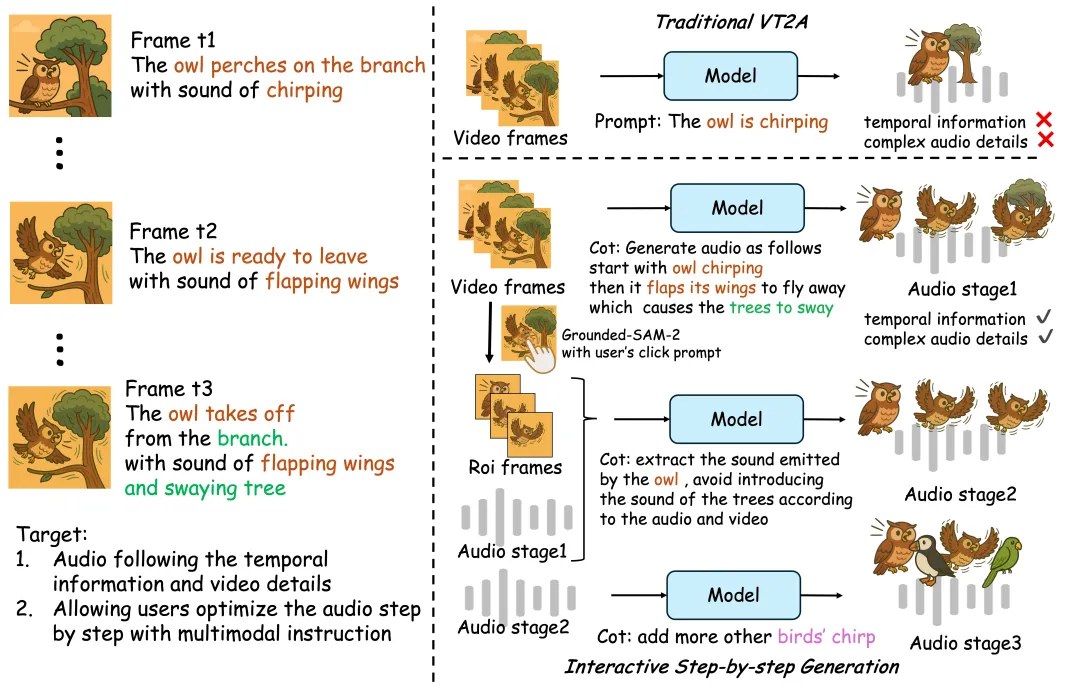
据官方介绍,近年来,尽管端到端视频到音频(V2A)生成技术取得了显著进展,但仍难以真正捕捉画面中的动态细节和空间关系。像猫头鹰何时鸣叫、何时起飞,树枝晃动时是否伴随摩擦声等视觉-声学关联,往往被忽视,导致生成的音频过于通用,甚至与关键视觉事件错位,难以满足专业创意场景中对时序和语义连贯性的严格要求。
这背后的核心问题在于:AI 缺乏对画面事件的结构化理解,无法像人类音效师那样,一步步分析、推理、再合成声音。
AI在线附开源地址:
https://github.com/FunAudioLLM/ThinkSound
https://huggingface.co/spaces/FunAudioLLM/ThinkSound
https://www.modelscope.cn/studios/iic/ThinkSound


