今天凌晨,阿里巴巴开源了Qwen3家族最新模型Qwen3-30B-A3B-Thinking-2507。
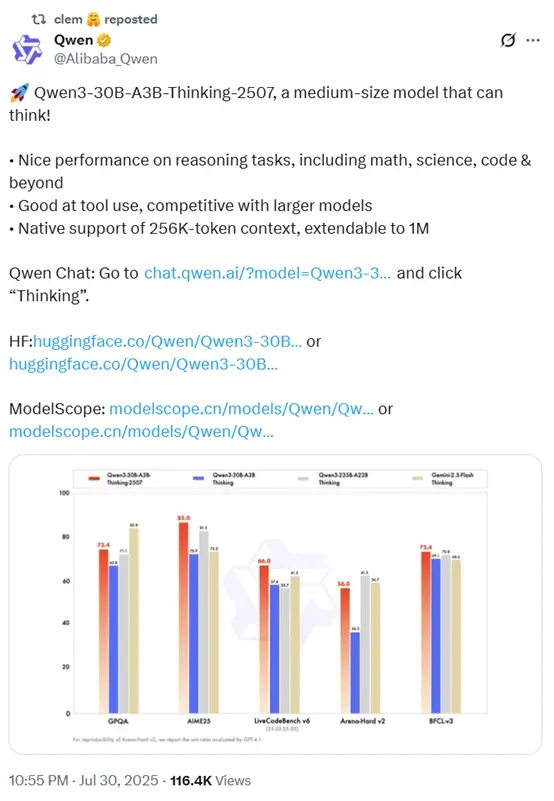
2507与之前阿里开源的Qwen3-30B-A3B-Thinking和Qwen3-235B-A22B-Thinking相比,在Agent智能体、AIME25数学、LiveCodeBench编程、GPQA解决复杂能力等方面,性能全部实现大幅度提升。
同时,2507也超过了谷歌的最新小参数模型Gemini-2.5-Flash-Thinking。
开源地址:https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507
https://modelscope.cn/models/Qwen/Qwen3-30B-A3B-Thinking-2507
对于阿里的新模型,网友表示,疯狂优秀的本地模型,绝对是我能在 20GB 以内装下的最佳选择。思考模式真的带来了天壤之别,恭喜你们,太给力了!

对于这么小的一个模型而言,它在各方面的性能提升都令人印象深刻。

不错,性能很强。现在只需要融合多模态能力,并支持 8 小时的音频和视频转录等功能就更好了。
干得漂亮,各位。真难以想象完成这项工作付出了多少努力,那些不眠之夜和全神贯注的时刻。

Qwen 团队的工作令人赞叹!Qwen3-30B-A3B-Thinking-2507模型在推理能力上的提升以及超大的上下文窗口具有颠覆性意义,为复杂问题的解决开辟了令人期待的新可能。期待探索它的潜力!
干的非常好,Qwen做的很棒。
Qwen3-30B-A3B-Thinking-2507总参数量达到 305 亿,其中激活的参数量为 33亿,非嵌入参数量为 299 亿。该模型包含 48层,采用 Grouped Query Attention机制,Q 的注意力头数为 32,KV 的注意力头数为 4。
此外,它还具备 128 个专家,其中激活的专家数量为8。原生支持256K上下文,但通过扩展可增加至100万。
在性能方面,Qwen3-30B-A3B-Thinking-2507相比其他模型在多个任务上都有出色表现。例如,在知识类的 MMLU-Pro 任务中得分为 80.9、MMLU-Redux为91.4、GPQA为73.4、SuperGPQA为56.8;在推理类的AIME25任务中得分为85.0、HMMT25为71.4、LiveBench 20241125 为 76.8;
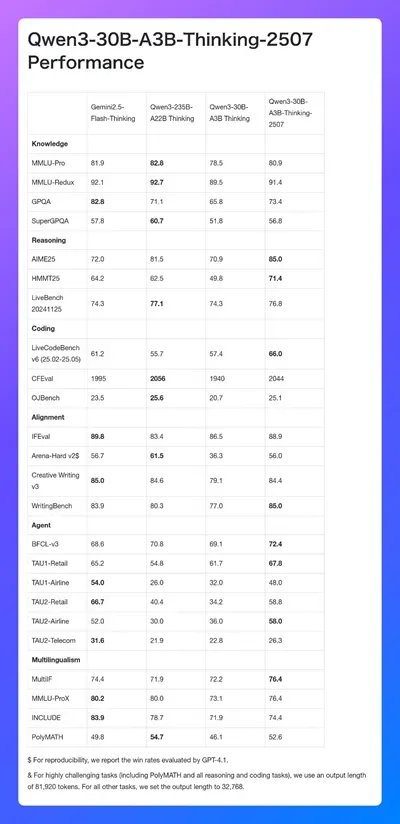
在编码类的LiveCodeBench v6(25.02 - 25.05)任务中得分为66.0、CFEval 为 2044、OJBench 为 25.1;在对齐类的IFEval 任务中得分为88.9、Arena-Hard v2 为 56.0、Creative Writing v3为84.4、WritingBench为85.0;
在Agent智能体类的BFCL - v3 任务中得分为72.4、TAU1 - Retail 为67.8、TAU1 - Airline为48.0、TAU2 - Retail 为 58.8、TAU2 - Airline 为 58.0、TAU2 - Telecom 为 26.3;
在多语言类的 MultiIF 任务中得分为 76.4、MMLU-ProX 为 76.4、INCLUDE为 74.4、PolyMATH为52.6。
Qwen3-30B-A3B-Thinking-2507在工具调用能力方面表现出色,推荐使用 Qwen - Agent 来充分发挥其代理能力,Qwen - Agent 内部封装了工具调用模板和工具调用解析器,大大降低了编码复杂性。可以通过 MCP 配置文件、Qwen - Agent 的集成工具或自行集成其他工具来定义可用工具。
为了达到最佳性能,建议采用这些设置:在采样参数方面,建议使用温度为0.6、TopP 为 0.95、TopK为20、MinP为0,对于支持的框架,还可以在0到2之间调整 presence_penalty 参数以减少无休止的重复,但使用较高值可能会偶尔导致语言混合和模型性能略有下降;
在输出长度方面,建议大多数查询使用 32768个token的输出长度,对于高度复杂问题如数学和编程竞赛的基准测试,建议将最大输出长度设置为 81920 个token,为模型提供足够的空间来生成详细全面的回答,从而提升整体性能。


