一.引言
推理大语言模型(LLM),如 OpenAI 的 o1 系列、Google 的 Gemini、DeepSeek 和 Qwen-QwQ 等,通过模拟人类推理过程,在多个专业领域已超越人类专家,并通过延长推理时间提高准确性。推理模型的核心技术包括强化学习(Reinforcement Learning)和推理规模(Inference scaling)。
主流的大模型强化学习算法,如 DPO、PPO、GRPO 等,通常需要在完整的思维链上进行微调,需要高质量数据、精确的奖励函数、快速反馈和在线迭代、以及大量的算力。当处理复杂任务,如高级数学和编程问题时,模型需要更细粒度的搜索、更精确的推理步骤和更长的思维链,导致状态空间和策略空间的规模急剧扩大,难度大幅上升。
Inference scaling 策略,不依赖训练,通过延长推理时间进一步提高模型的 Reasoning 能力。常见方法,如 Best-of-N 或者蒙特卡洛树搜索(MCTS),允许 LLM 同时探索多条推理路径,扩大搜索空间,朝着更有希望的方向前进。这些方法计算成本高,特别是步骤多或搜索空间大的时候。采样随机性使得确定最佳路径困难,且依赖手动设计的搜索策略和奖励函数,限制了泛化能力。
在此背景下,普林斯顿大学团队联合北京大学团队合作开发了名为 ReasonFlux 的多层次(Hierarchical)LLM 推理框架。

- 文章链接:https://arxiv.org/abs/2502.06772
- 开源地址:https://github.com/Gen-Verse/ReasonFlux
(该论文作者特别声明:本工作没有蒸馏或用任何方式使用 DeepSeek R1。)
基于层次化强化学习(Hierachical Reinforcement Learning)思想,ReasonFlux 提出了一种更高效且通用的大模型推理范式,它具有以下特点:
- 思维模版:ReasonFlux 的核心在于结构化的思维模板,每个模版抽象了一个数学知识点和解题技巧。仅用 500 个通用的思维模板库,就可解决各类数学难题。
- 层次化推理和强可解释性:ReasonFlux 利用层次化推理(Hierarchical Reasoning)将思维模板组合成思维轨迹(Thought Template Trajectory)、再实例化得到完整回答。模型的推理过程不再是 “黑盒”,而是清晰的展现了推理步骤和依据,这为 LLM 的可解释性研究提供了新的工具和视角,也为模型的调试和优化提供了便利。与 DeepSeek-R1 和 OpenAI-o1 等模型的推理方式不同,ReasonFlux 大大压缩并凝练了推理的搜索空间,提高了强化学习的泛化能力,提高了 inference scaling 的效率。
- 轻量级系统:ReasonFlux 仅 32B 参数,强化训练只用了 8 块 NVIDIA A100-PCIE-80GB GPU。它能通过自动扩展思维模板来提升推理能力,更高效灵活。
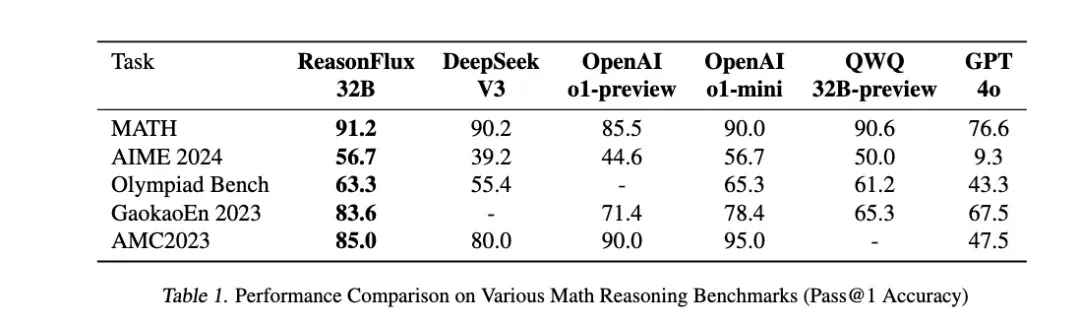
ReasonFlux-32B 在多个数学推理基准测试中表现出色,仅仅用了 500 个基于不同数学知识点的思维模版,就展现了其强大的推理能力和跻身第一梯队的实力。
二.ReasonFlux:
三大关键技术构建大模型推理新框架
ReasonFlux 的性能提升得益于其三大核心技术:
- 结构化的思维模板抽取:ReasonFlux 利用大语言模型从以往的数学问题中提取了一个包含大约 500 个结构化思维模板的知识库。每个模板都包含标签、描述、适用范围、应用步骤等信息,这些信息经过组织和结构化处理,为 LLM 的推理提供了元知识参考。这些模板覆盖了多种数学问题类型和解题方法,如不等式求解、三角函数变换、极值定理等,是 ReasonFlux 进行推理的基础。
- 多层次强化学习(Hierarchical RL) — 选择最优的 Thought Template Trajectory:该算法通过 Hierarchical Reinforcement Learning 训练一个 High-level 的 navigator,使其能够对输入问题进行拆解,转而求解多个更简单的子问题,根据子问题类型从模板库中检索相关的思维模板,并规划出最优的 Thought Template Trajectory。它可以看作是解决问题的 “路线图”,它由一系列的模板组合而成。这种基于 Hierarchical RL 的优化算法通过奖励在相似问题上的泛化能力,提升了推理轨迹的鲁棒性和有效性,使得 ReasonFlux 能够举一反三,为各种数学问题生成有效的思维模板轨迹。
- 新型 Inference Scaling 系统:该系统实现了结构化模板库和 inference LLM 之间的多轮交互。“Navigator” 负责规划模板轨迹和检索模板,inference LLM 负责将模板实例化为具体的推理步骤,并通过分析中间结果来动态调整轨迹,实现高效的推理过程。这种交互机制使得 ReasonFlux 能够根据问题的具体情况灵活调整推理策略,从而提高推理的准确性和效率。
(a)推理示例对比:
接下来我们来分析 ReasonFlux 在解决实际问题上相较于 o1-mini 的对比。
我们来看和 o1-mini 的对比

如上图可知,o1-mini 在面对这道难题时,尝试了多种策略,但均未能找到有效的突破口。它首先试图通过引入新变量和利用对称性来简化方程组,但收效甚微;接着又尝试假设变量相等来寻找特解,结果却得出了矛盾;随后,它试图用一个变量表示其他变量,并尝试平方去根号,但复杂的表达式使其望而却步;最后,它甚至想到了三角换元,但由于未能正确应用,最终只能无奈地放弃求解。
相比之下,ReasonFlux 的解题过程如下:
- 分析与规划:ReasonFlux 首先对题目进行分析,确定了解题的主要步骤:初步确定 k 值的范围、利用三角换元、化简方程组、求解 θ、计算目标值。这一步反映了 ReasonFlux 的问题分析和规划能力,为后续解题过程提供了基础。
- 模板化推理:ReasonFlux 随后依次应用了 “三角换元”、“化简方程组”、“求解 θ” 等模板,将复杂的方程组逐步简化,并最终求解出 θ 的值。每一步都依据模板的指导,旨在保证解题过程的准确性。
- 逐步推导:ReasonFlux 根据求得的角度值,计算出 (x, y, z) 的值,并最终计算出目标值
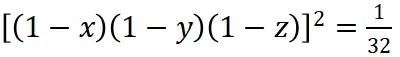 ,从而得到 (m=1, n=32, m+n=33)。整个过程逻辑清晰,步骤明确,展示了 ReasonFlux 的规划和推理能力。
,从而得到 (m=1, n=32, m+n=33)。整个过程逻辑清晰,步骤明确,展示了 ReasonFlux 的规划和推理能力。
 图片
图片
(b) 新的 inference scaling law:
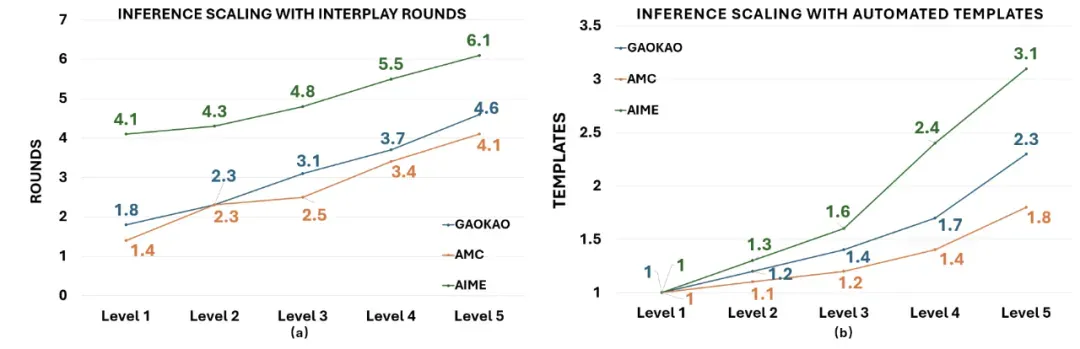
如上图所示,随着问题复杂度的增加,ReasonFlux 正确解答问题时所需的模板数量和交互轮数也相应增加。这表明 ReasonFlux 能够根据问题的难度动态调整推理策略,体现了其优秀的自适应能力。并且可以观察到,交互轮数的增长趋势略高于模板数量,这意味着规划能力的提升对解决复杂问题至关重要。
三.主流推理范式对比:
ReasonFlux vs Best-of-N & MCTS
目前,提升 LLM 推理性能的主流方法通常依赖于增加模型规模和计算资源。例如,增加模型参数量、采用 Best-of-N 或蒙特卡洛树搜索 (MCTS) 等方法来扩大搜索空间以寻找更优解。然而,这些方法往往计算成本较高,且模型的推理过程难以解释。
ReasonFlux 采用了一种不同的方法,通过构建结构化的思维模板库和设计新的层次化强化学习算法,实现了一种更高效和可解释的推理方式。
传统的 Inference Scaling 方法,如 Best-of-N 和 MCTS,主要通过扩大搜索空间来提高准确率。但随着问题复杂度的增加,搜索空间呈指数级增长,导致计算成本显著上升。
在 ReasonFlux 的推理过程中,Navigator 与 Inference LLM 之间存在多轮交互。Inference LLM 根据 Navigator 给出的模板轨迹执行推理步骤后,Navigator 会对执行结果进行评估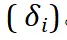 。如公式
。如公式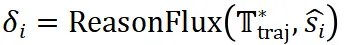 所示,根据评估结果,Navigator 会动态调整模板轨迹
所示,根据评估结果,Navigator 会动态调整模板轨迹 ,例如修改当前步骤的模板、添加或删除步骤等。这种迭代优化的机制使得 ReasonFlux 能够根据问题的具体情况灵活调整推理策略,从而提高推理的准确性和效率。
,例如修改当前步骤的模板、添加或删除步骤等。这种迭代优化的机制使得 ReasonFlux 能够根据问题的具体情况灵活调整推理策略,从而提高推理的准确性和效率。
ReasonFlux 通过引入结构化的思维模板,将搜索空间从 “原始解空间” 缩小到 “模板空间”,从而降低了搜索的难度和成本。如果说传统的推理范式是 “大海捞针”,那么 ReasonFlux 则是 “按图索骥”。这些模板并非简单的规则堆砌,而是经过提炼和结构化处理的知识模板,它们将复杂的推理过程分解为一系列可复用的步骤,从而提升了推理的效率和准确率。
 图片
图片
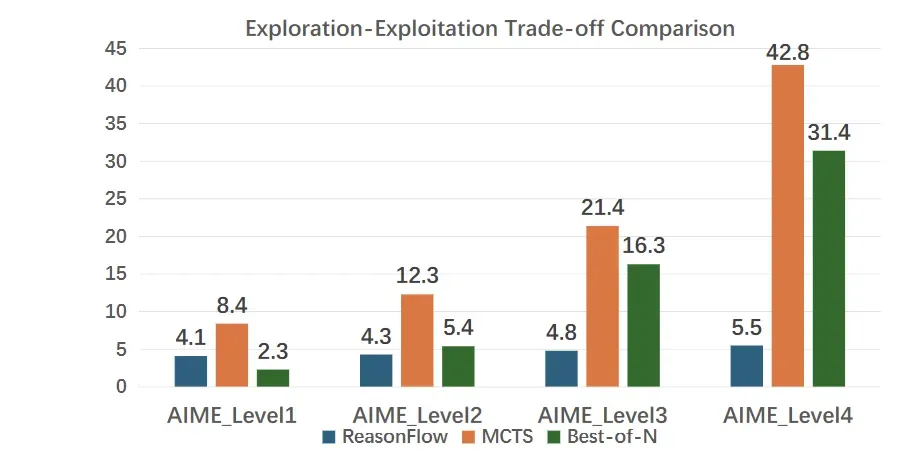
如上图所示,随着问题难度的提升,Best-of-N 和 MCTS 的探索成本(例如采样轨迹数量和迭代次数)显著增加,而 ReasonFlux 的探索成本(交互轮数)则保持在较低水平且相对稳定。这说明 ReasonFlux 能够更高效地利用已有的知识模板来解决问题,而不需要像 Best-of-N 和 MCTS 那样进行大量的试错和探索。这得益于 ReasonFlux 的结构化模板库和模板轨迹规划机制,使其能够在更小的搜索空间内找到正确的推理路径。
四.训练及推理框架介绍
下图展示了 ReasonFlux 的训练框架,其核心在于利用结构化的思维模板库和基于思维模板轨迹奖励的层次化强化学习算法,训练出一个能够进行高效推理的大模型。整个训练过程可以分为两个主要阶段:结构化知识学习和思维模板轨迹优化。
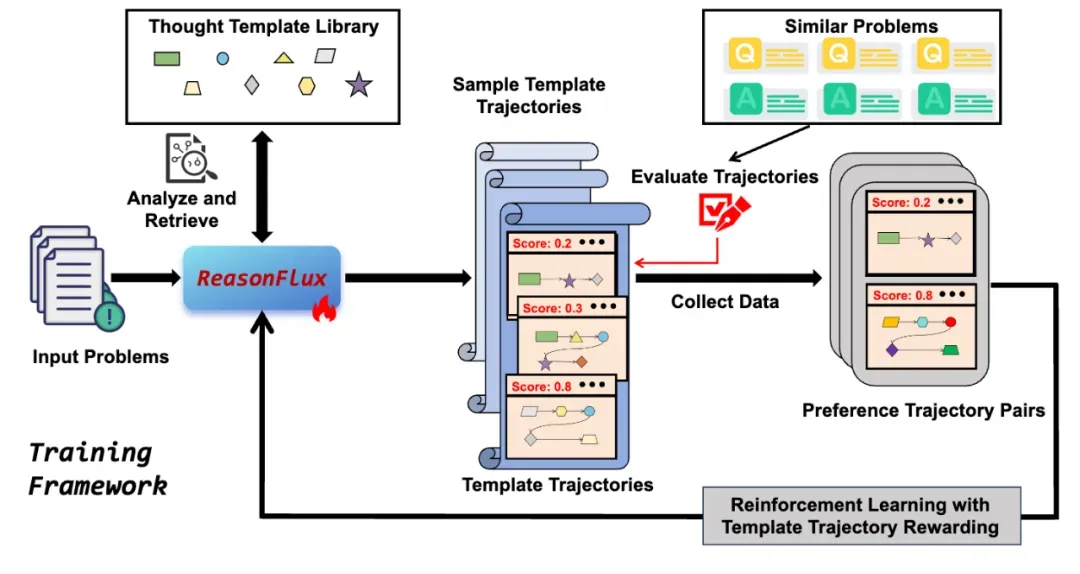
1. 结构化知识学习阶段:这个阶段的目标是让模型学习思维模板库中蕴含的结构化知识。这些结构化的 Thought template 格式如下图所示:

然后,我们利用这些结构化模板数据 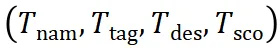 对一个基础 LLM 进行微调,得到模型
对一个基础 LLM 进行微调,得到模型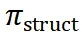 。训练的目标是让模型能够根据模板的名称和标签,生成对应的描述和适用范围 。通过这个阶段的训练,模型学习到了模板库中蕴含的丰富知识,并具备了初步的模板理解和应用能力。
。训练的目标是让模型能够根据模板的名称和标签,生成对应的描述和适用范围 。通过这个阶段的训练,模型学习到了模板库中蕴含的丰富知识,并具备了初步的模板理解和应用能力。
2. 模板轨迹优化阶段:这个阶段的目标是训练模型生成有效的模板轨迹,即针对特定问题,选择合适的模板并进行排序,形成解决问题的 “路线图”。我们利用新颖的基于 Thought Template Trajectory 的 Hierarchical RL 算法来实现这一目标。在这个阶段,我们使用 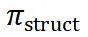 模型针对输入问题
模型针对输入问题 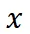 生成多个候选的 high-level 思维模板轨迹
生成多个候选的 high-level 思维模板轨迹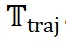 。每个轨迹由一系列步骤
。每个轨迹由一系列步骤 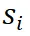 组成,每个步骤都关联到一个特定的模板。为了评估轨迹的质量,我们构建了一组与输入问题
组成,每个步骤都关联到一个特定的模板。为了评估轨迹的质量,我们构建了一组与输入问题 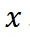 相似的问题集
相似的问题集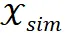 。然后,我们利用 inference LLM
。然后,我们利用 inference LLM 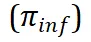 根据模板轨迹对这些相似问题进行具体的解答,并计算平均准确率作为轨迹的奖励
根据模板轨迹对这些相似问题进行具体的解答,并计算平均准确率作为轨迹的奖励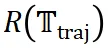 。基于这个奖励信号,我们构建了优化样本对
。基于这个奖励信号,我们构建了优化样本对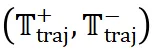 ,其中
,其中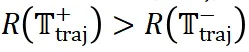 。然后,我们利用这些样本对,通过 DPO 对
。然后,我们利用这些样本对,通过 DPO 对 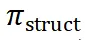 进行进一步优化,得到最终的 navigator 模型
进行进一步优化,得到最终的 navigator 模型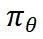 ,也就是我们的 ReasonFlux 模型。
,也就是我们的 ReasonFlux 模型。
通过这两个阶段的训练,ReasonFlux 模型不仅学习到了结构化的模板知识,还学会了如何针对特定问题选择和组合模板,形成有效的推理路径。这种能力使得 ReasonFlux 能够高效地解决各种复杂的数学推理问题。
下图是 ReasonFlux 的推理框架。其核心在于 navigator、inference LLM 和结构化模板库之间的多轮交互。这种交互机制使得 ReasonFlux 能够根据问题的具体情况灵活调整推理策略,从而提高推理的准确性和效率。
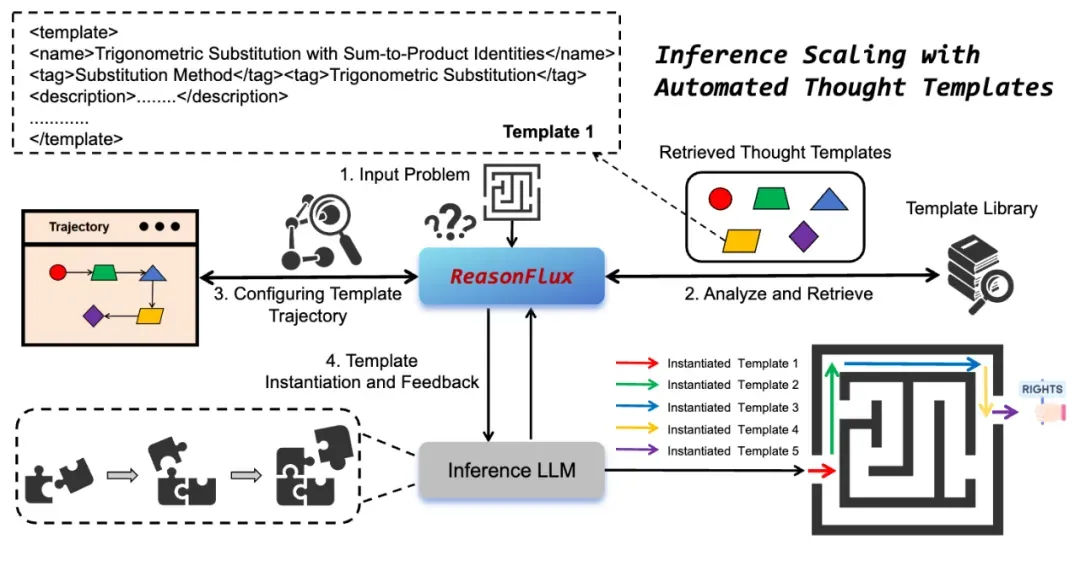
以下是 ReasonFlux 的推理流程:

通过这种 navigator 引导、inference LLM 执行、模板库支持、动态调整轨迹的多轮交互机制,ReasonFlux 能够高效地解决各种复杂的数学推理问题。这种推理框架不仅提高了推理的准确性和效率,还增强了模型的可解释性,因为我们可以清晰地追踪模型的推理过程和依据。
五.数学推理数据集上的表现:
小模型媲美大模型,展现未来应用潜力
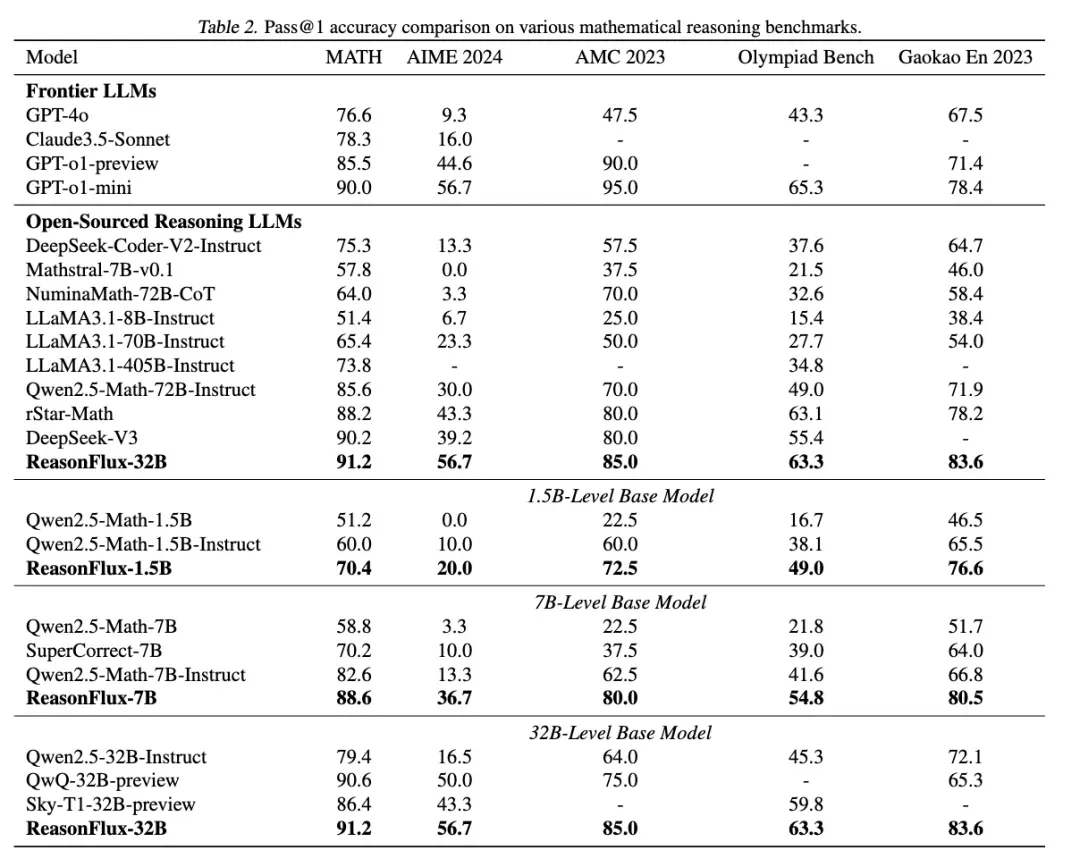
ReasonFlux 在 MATH、AIME 2024、AMC 2023、OlympiadBench 和 Gaokao En 2023 等多个具有挑战性的数学推理数据集上进行了测试,并取得了良好的结果。
ReasonFlux-32B 在这些数据集上的表现处于前列,与其他先进模型相比具有竞争力。如下表所示,在 MATH 数据集上,ReasonFlux-32B 的准确率为 91.2%;在 AIME 2024 数据集上,ReasonFlux-32B 的准确率为 56.7%。这些结果表明 ReasonFlux 框架具有有效性。更重要的是,它表明较小规模的模型通过优化推理框架,可以达到甚至在某些情况下超越较大模型的性能。
ReasonFlux 还可用于不同大小(1.5B, 7B 和 32B)的基础模型,并且都能获得巨幅的推理效果提升,足见其通用性和泛化性。
ReasonFlux 的成功不仅限于数学推理领域,其背后的核心思想 —— 结构化思维模板和模板轨迹 —— 具有广泛的应用潜力。未来,ReasonFlux 有潜力被应用于更多领域,如代码生成,医疗诊断,具身智能等多个领域。
六.作者介绍
杨灵:北大在读博士,普林斯顿高级研究助理,研究领域为大语言模型和扩散模型。
余昭辰:新加坡国立大学在读硕士,北京大学 PKU-DAIR 实验室科研助理,研究领域为大语言模型和扩散模型。
崔斌教授:崔斌现为北京大学计算机学院博雅特聘教授、博士生导师,担任计算机学院副院长、数据科学与工程研究所所长。他的研究方向包括数据库系统、大数据管理与分析、机器学习 / 深度学习系统等。
王梦迪教授:王梦迪现任普林斯顿大学电子与计算机工程系终身教授,并创立并担任普林斯顿大学 “AI for Accelerated Invention” 中心的首任主任。她的研究领域涵盖强化学习、可控大模型、优化学习理论以及 AI for Science 等多个方向。


