近日,一篇名为《排行榜幻觉》的论文在学术界引发了广泛关注,尤其是对大型语言模型(LLM)领域中备受推崇的 Chatbot Arena 排行榜提出了严厉质疑。研究指出,排行榜的可信度因数据访问不平等、模型私下测试等问题而受到挑战。
论文显示,一些大型科技公司可以在公开发布之前对多个模型版本进行私下测试。例如,Meta 在发布 Llama4之前测试了多达27个版本,然后只对外公布表现最佳的模型。这种 “最佳选择” 策略不仅导致了模型排行榜的膨胀,还可能误导用户对模型真实能力的判断。
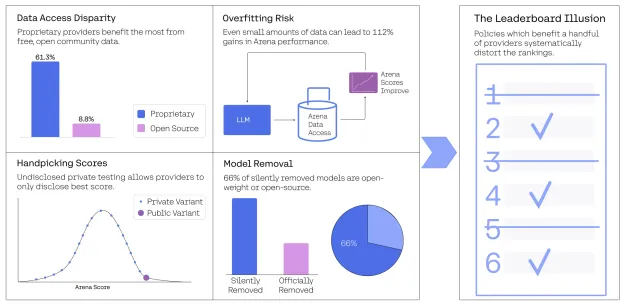
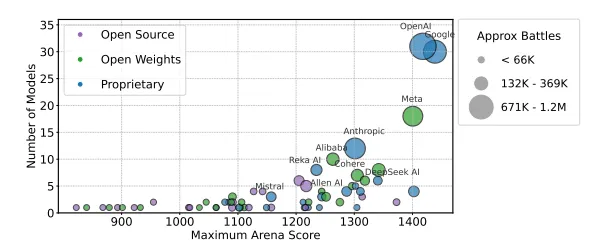
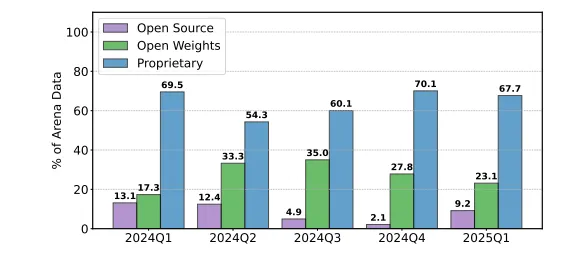
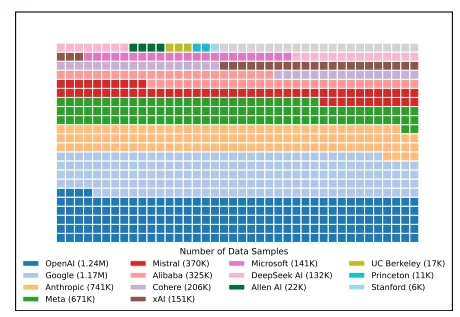
此外,研究还发现,专有模型获得的用户反馈数据远超过开源模型,这种数据访问的不平等使得一些开源模型在竞争中处于劣势。以 Google 和 OpenAI 为例,它们分别占据了测试数据的19.2% 和20.4%,而83个开源模型仅获得了约29.7% 的数据。这意味着,开源模型在排行榜上难以获得公平的展示机会。
更令人担忧的是,研究团队还发现,243个模型中有205个被悄然弃用,这一数量远超官方统计的47个。这种现象使得排行榜的公正性进一步受到质疑。
针对论文提出的问题,大模型竞技场的官方回应表示,虽然存在私下测试的情况,但这并不意味着排行榜存在偏见。同时,他们强调,排行榜的排名反映了大量用户的真实偏好。不过,研究团队认为,这种快速刷榜的现象并不真实地反映模型的技术进步。
为了提高排行榜的公正性,研究团队提出了五项改进建议,包括禁止撤回提交分数、限制每个厂商的非正式模型数量,以及提高模型弃用的透明度等。
目前,随着对排行榜机制的深入探讨,AI 社区意识到,单一排行榜可能无法全面反映模型的能力,寻找多个评估平台变得愈发重要。对此,卡帕西建议使用 OpenRouter,这是一个能够统一访问多种模型的接口,虽然目前在多样性和使用量上还有待提升,但具有巨大的潜力。


