这款模型采用了完全不同于以往的生成方式,不再是“一个词一个词”地慢慢生成,而是整段代码并行生成,一次生成多个片段。
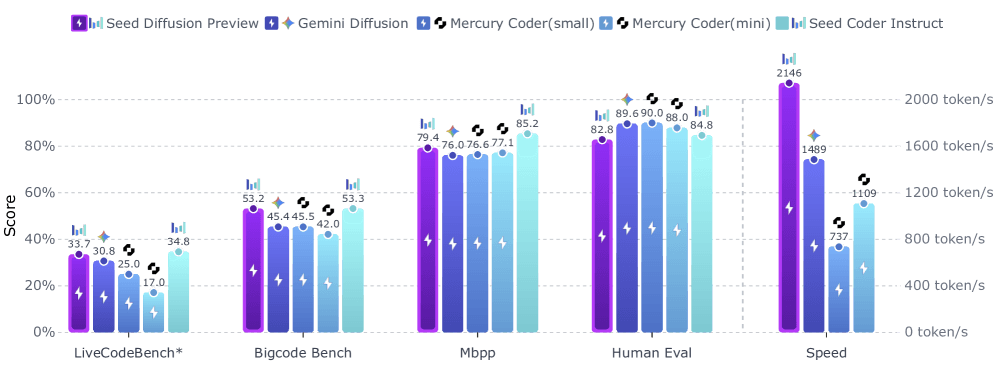
据官方披露,Seed Diffusion Preview在Nvidia H20 GPU上的生成速度高达2146个token每秒,比传统模型提升了最多5.4倍。
 图片
图片
与传统的自回归模型不同,这款新模型采用“离散状态扩散”(discrete-state diffusion)的方法,将图像扩散模型的思路移植到了文字和代码领域。
它的工作原理是:先制造一段带有噪声和占位符的初始代码,然后一步步地“复原”出真实的代码,而不是从头开始一个字符一个字符地拼凑。
这样的结构,使得模型可以一次性生成多个部分,再通过Transformer建模依赖关系,并结合因果顺序与轨迹蒸馏来提升一致性。
在多项基准测试中,Seed Diffusion Preview的表现不输其它主流模型,在代码编辑等任务中表现尤为突出。
1.双阶段训练机制
为了兼顾速度和质量,字节跳动为Seed Diffusion Preview设计了一套双阶段训练机制。
第一阶段采用遮罩训练,将部分代码替换为特殊的占位符,训练模型还原这些被遮罩的内容。但单靠这一阶段会产生一个问题:模型可能忽视未被遮罩的部分,只是盲目复制原文而不加检验。(前 80%)
独立性假设:
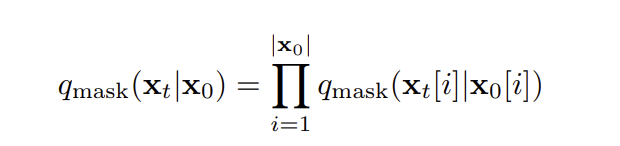 图片
图片
边际概率分布:
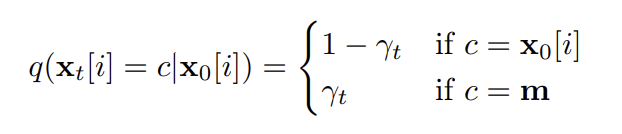 图片
图片
为此,团队加入了第二阶段:基于编辑的训练,引入插入和删除操作,强迫模型检查并修正所有部分,不只是那些被遮挡的片段。
此外,字节跳动还优化了代码的生成顺序。
模型通过约束顺序训练引导模型遵循依赖关系(如先声明后使用),以提升完整性与可执行性。
训练语料是,在常规代码语料基础上,额外用预训练扩散模型生成轨迹并筛选蒸馏,以提升顺序与一致性。
2.瞄准谷歌,进军复杂推理领域
Seed Diffusion Preview不仅是一个技术展示,它的推出也有明确的对标对象。
谷歌在今年5月推出了Gemini Diffusion模型,同样主打代码生成。字节跳动此举,正面迎战谷歌。
从性能对比看,Seed Diffusion Preview在推理速度上全面领先,并且在代码编辑、生成结构完整代码方面也能与之抗衡甚至超越。(即在作者给定设置下速度更快,由于硬件与评测差异,跨模型直接对比需谨慎)
特别是在并行解码方面,Seed Diffusion Preview采用了“自我优化生成机制”(同策略学习(on-policy)。
在训练中引入验证器的同策略目标,以减少生成步数并维持质量。
此外,字节跳动针对扩散生成流程开发了内部的框架支持工具链,优化了整个软件栈。
生成过程中,虽然各个代码块并行生成,但整体上仍然保持逻辑顺序,保证变量依赖关系和执行顺序的正确性。
未来,字节跳动计划继续扩大模型规模,并尝试将这种并行扩散架构推广到更复杂的推理任务中。
目前,该模型已有在线演示版本。不过因为太火,显示服务繁忙。
https://studio.seed.ai/exp/seed_diffusion/


