大家好,我是肆〇柒。今天一起看看由东南大学、布朗大学与微软研究院联合推出的最新研究成果——InfoAgent。这项工作直指当前深度研究智能体领域的核心痛点,通过创新的数据合成管道和自托管搜索工具,成功让14B参数的模型在复杂研究任务上超越72B参数的竞品。在信息过载的时代,这项研究或许能为我们带来真正"懂你"的信息检索体验。
想想看,当你在医疗研究中试图寻找"罕见病的最新治疗方案",或在商业分析中探索"特定市场细分的最新消费者行为趋势"时,你是否曾遇到过这样的困境:普通搜索引擎返回大量相关但浅层的信息,却无法整合出真正有价值的答案?现有开源深度研究智能体(DRA)同样束手无策——它们平均仅进行5.4次(ASearcher)至9.5次(DeepDive)工具调用,而这类问题通常需要20次以上搜索才能解决。这意味着,当你面对需要多源信息整合的复杂研究问题时,当前开源DRA可能无法提供可靠答案。InfoAgent的研究探索,就是为了突破这一限制,让信息检索真正理解并解决你的复杂问题。
为什么"浅层搜索"总让你失望?
深度研究智能体(DRA)与普通搜索引擎或检索增强生成(RAG)系统有着本质区别:RAG将检索段落视为潜在变量,表现出高效、静态和局部检索的特点;而DRA则通过迭代方式与工具交互,实现灵活的多源信息整合,能够处理更复杂的长视野搜索任务。这一区别至关重要——当你面对需要整合多个信息源的复杂研究问题时,DRA的长视野搜索能力决定了你能否找到关键答案。
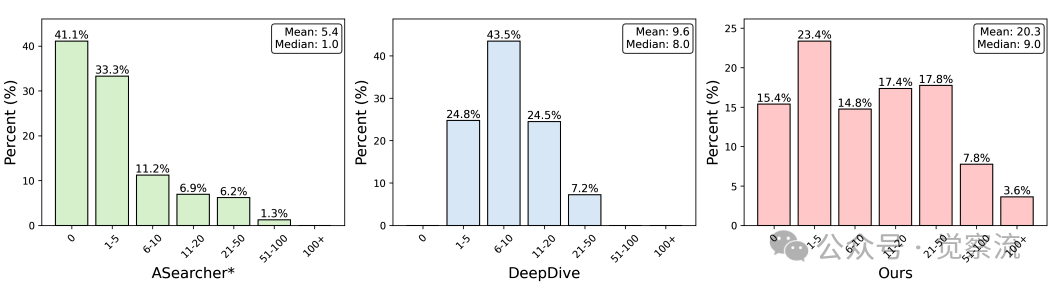
工具调用分布分析
上图直观揭示了问题所在:ASearcher数据集呈现出高度倾斜的工具调用分布,大部分示例需要零次或极少工具调用(平均5.4次,中位数1次);DeepDive虽有更密集的工具调用分布(平均9.5次,中位数8次),但工具调用数量仍远低于实际需求。相比之下,InfoAgent数据集展现出显著更高的工具使用频率(平均20.3次)和更广分布,大量轨迹需要20-50次调用,甚至有非忽略比例超过100次。
这意味着什么?当你试图了解"1930年代出生于弗吉尼亚县(国会在1846年归还给该州并在1920年更名)的棒球投手首次亮相的球队"时,普通DRA可能只进行5-10次搜索就放弃或给出错误答案。ASearcher数据集就像浅尝辄止的网络冲浪者,而InfoAgent数据集则像专业研究员——它不满足于表面答案,而是不断深入挖掘,直到找到确凿证据。
瓶颈一:高质量训练数据的缺乏与InfoAgent的突破
要让DRA真正"懂你",首先需要解决训练数据问题。InfoAgent通过创新的数据合成管道,系统性地增加了问题难度,确保模型必须进行长视野搜索才能找到答案。
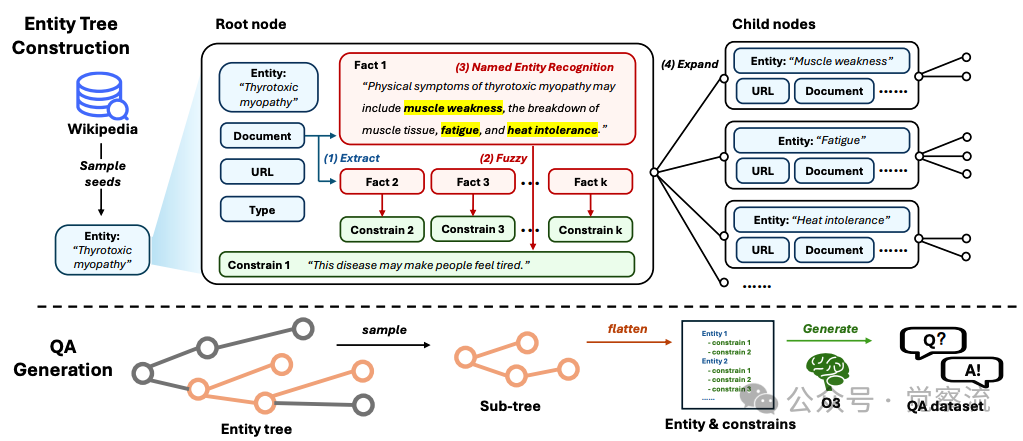
多实体搜索问题的合成流程
上图展示了这一管道的核心机制:从维基百科实体构建结构化问题的完整流程。管道首先将原始实体转换为节点,每个节点包含实体名称、URL和从对应页面提取的事实集合;然后通过子树采样系统性地增加问题难度。

这种处理确保实体名称和具体日期/数字被替换为模糊对应物,使模型难以基于内部知识或直接搜索识别实体。例如,"哪位1992年获得诺贝尔奖的物理学家"变为"哪位1990年代初获得重要科学奖项的科学家",迫使模型必须进行多步推理而非简单匹配。

子树提取算法通过随机选择节点并回溯到根节点的路径,逐步构建子树,确保问题难度的可控增加。这一算法确保了问题难度的系统性提升,是InfoAgent数据合成管道的核心环节。
这些设计带来的效果显著:InfoAgent在BrowseComp上的准确率从SFT阶段的4.7%提升至RL后的15.3%,在BrowseComp-ZH上从17.0%提升至29.2%。这意味着,在100个复杂研究问题中,InfoAgent能正确回答15个左右,而其他开源模型可能只能回答不到5个。在医疗研究或法律咨询等关键场景中,这10%的差距可能就是"找到救命方案"与"一无所获"的区别。
瓶颈二:搜索工具的质量与可控性——摆脱商业API的"黑盒"困境
即使拥有高质量训练数据,如果工具环境不佳,DRA性能仍会受限。现有研究往往依赖商业搜索API,导致检索过程隐藏在专有服务背后,行为不可控,且效率受外部速率限制和工具可用性约束。这不仅使智能体行为难以预测,也使训练和评估难以复现。另一些工作采用简单的维基检索器,其信息质量有限,无法处理需要最新网络信息的问题。
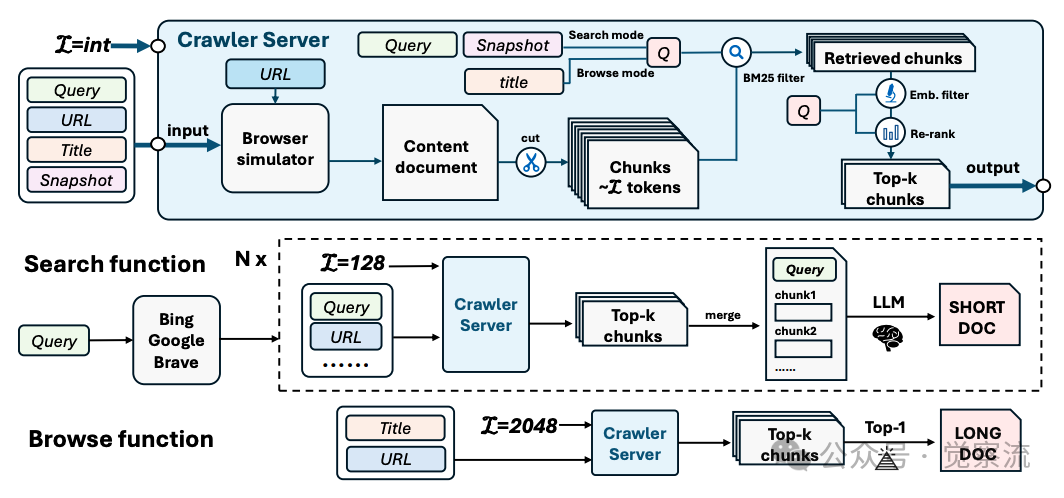
搜索工具工作流程
上图详细展示了InfoAgent搜索工具的完整工作流程,揭示了如何解决这一瓶颈。该工具提供两种功能:搜索功能返回相关URL和网页片段;浏览功能则允许深入调查特定URL的内容。
搜索功能的工作流程始于从搜索引擎(主要使用Google,Bing/Brave作为备用)获取初始结果;然后通过网络爬虫获取完整网页,分割为128 token短文本块;针对约15%无法爬取的网站,添加搜索引擎快照作为备用内容。为提升搜索结果质量,InfoAgent采用多级内容过滤机制:
1. 首先使用BM25算法检索前40块,快照作为查询检索前3块
2. 接着利用Qwen-3-Embedding-0.6B筛选前8块
3. Qwen-3-Reranker-0.6B筛选前3块
4. 最后由GPT-4o-mini生成不超过60词的简洁片段
这一多级过滤机制确保了搜索结果的精准性和相关性。浏览功能则获取2048 token长内容块,用于深度探索。
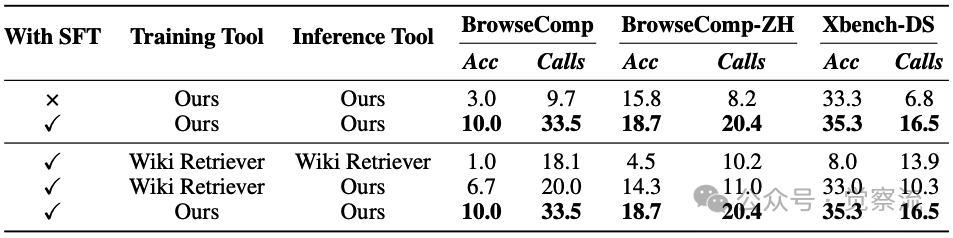
在 BrowseComp、BrowseComp-ZH 和 Xbench-DS 上,不同设置下训练和评估的模型的准确率和工具调用次数对比表明,跳过 SFT(冷启动监督微调)阶段,或者使用 Wiki Retriever 进行训练/评估的模型,表现较差。
上表数据直观展示了工具质量的重要性:当训练和推理均使用InfoAgent工具时,BrowseComp准确率达10.0%,BrowseComp-ZH达18.7%;仅SFT阶段使用优质工具时,准确率降至3.0%和15.8%;而使用Wiki检索器训练和推理时,准确率仅为1.0%和4.5%。这一10倍的性能差距凸显了优质搜索工具的决定性作用。
更令人惊讶的是,尽管所有训练数据均为英文,InfoAgent在中文基准测试中表现优异(BrowseComp-ZH达29.2%),展示了出色的跨语言泛化能力。这是一个关键的"啊哈时刻":核心推理能力不依赖于语言特定知识,而更多基于对问题结构和逻辑关系的理解。对于多语言用户而言,这意味着无论你使用何种语言提问,InfoAgent都能提供高质量的复杂问题解决方案。
两阶段训练:从行为模仿到能力飞跃
InfoAgent采用两阶段训练方法:冷启动监督微调(SFT)和强化学习(RL)。下图直观展示了SFT冷启动对RL训练的关键影响:
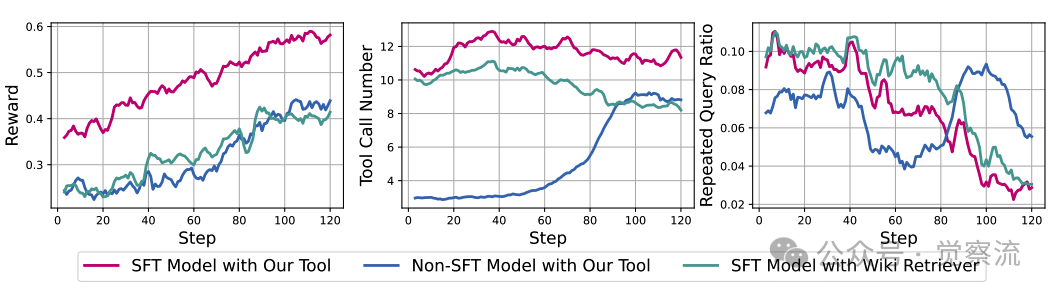
强化学习训练过程比较
- 左图显示无SFT冷启动的初始指令模型几乎无法学习获得更高奖励(准确率提升有限),而SFT模型则能持续提升性能
- 中图表明SFT模型的工具调用次数显著更高
- 右图显示SFT模型的重复查询比例随训练明显下降,表明其学会了尝试不同查询获取更多信息
这一现象证实,深度研究需要规划、信息检索、回溯等复杂能力,充分的高质量SFT不可或缺。当模型没有SFT冷启动时,它不知道如何充分利用工具,重复查询比例高,工具调用次数低。
想象训练一个研究员却不教他基本研究方法——这就是没有SFT冷启动的情况。上图左侧显示,没有SFT冷启动的模型像无头苍蝇般乱撞,重复查询比例高,工具调用次数低;而SFT模型则像受过专业训练的研究员,逐步优化搜索策略,准确率持续提升。SFT阶段植入的长视野搜索行为,为RL阶段的性能飞跃奠定了基础。
在SFT阶段,InfoAgent在14k合成轨迹上微调Qwen3-14B,批大小128,学习率2e-5,训练2个周期,上下文长度32k tokens。表3分析了轨迹长度的影响:训练轨迹包含≥10次工具调用时,BrowseComp准确率达7.1%(但80%超出上下文);而<10次工具调用时,准确率仅为2.8%。这表明模型需要长轨迹训练才能解决复杂任务,但过长轨迹可能导致上下文耗尽。
RL阶段进一步优化了SFT模型的推理驱动工具使用能力。研究采用难度筛选策略,选择pass@4在0.25-0.75之间的样本(5.7k样本),确保数据难度适中。RL阶段采用GRPO算法优化,以AdamW优化器,学习率1e-6,批大小128,训练5个周期。为加速训练并鼓励高效解决问题,响应被限制在16k tokens内。
RL训练后,InfoAgent在多个基准测试上显著提升:BrowseComp从4.7%提升至15.3%,BrowseComp-ZH从17.0%提升至29.2%,Xbench-DS从28.0%提升至40.4%。这一提升直接反映了两阶段训练方法的有效性——SFT阶段植入长视野搜索行为,为RL阶段的性能飞跃奠定基础。
棒球投手案例:一场智能推理的精彩演绎
论文中的附录提供了一个详细案例,展示了InfoAgent解决需要多步推理、整合历史地理与体育数据的复杂问题的能力:
问题:"哪支大联盟棒球队是那位在1930年代出生于弗吉尼亚县(国会在1846年归还给该州并在1920年更名)的投手首次亮相的?"
这一问题看似简单,实则包含多重线索:历史地理信息(1846年归还、1920年更名的弗吉尼亚县)、时间线索(1930年代出生)、体育数据(近20次救援成功)。InfoAgent通过7步推理过程解决:
1. 地理线索破解:确定县为阿灵顿县(原亚历山德里亚县,1846年归还,1920年更名)
2. 初步搜索受挫:搜索"阿灵顿县弗吉尼亚1930年代出生的棒球投手",但结果不匹配
3. 策略调整关键点:结合"近20次救援成功"线索,搜索"1950年代第三名近20次救援",发现Roy Face和Hoyt Wilhelm,但出生地不符
4. 精确化搜索:将模糊的"1930年代"精确化为"1930年",搜索"1930年阿灵顿县弗吉尼亚棒球",找到Bill Dailey
5. 验证关键信息:浏览Bill Dailey维基百科页面确认:1935年5月13日生于阿灵顿县
6. 数据交叉验证:确认1963年记录21次救援("近20次"),1961年8月17日首次亮相于克利夫兰印第安人队




棒球投手问题解决轨迹
上图展示了这一完整推理过程,特别突出了关键决策点。在Step 3中,当初始搜索结果不匹配时,InfoAgent没有放弃,而是巧妙地利用问题中的隐含线索"近20次救援"调整搜索策略,从宽泛搜索转向更精确的查询。在Step 4中,模型进一步精确化查询,将"1930年代"细化为"1930年",并明确指定"弗吉尼亚",最终成功定位目标实体Bill Dailey。
这种基于中间结果动态调整搜索策略的能力,正是InfoAgent解决复杂研究问题的核心优势。它不是机械地执行预设步骤,而是像人类研究员一样,根据已有信息不断调整研究方向,直至找到答案。当你试图了解类似问题时,普通搜索引擎会直接返回"1920年弗吉尼亚县"的地理信息,而不会关联到棒球历史。InfoAgent通过7步推理找到Bill Dailey和克利夫兰印第安人队,这正是你需要的深度研究能力。
实际价值:超越数字的真正意义
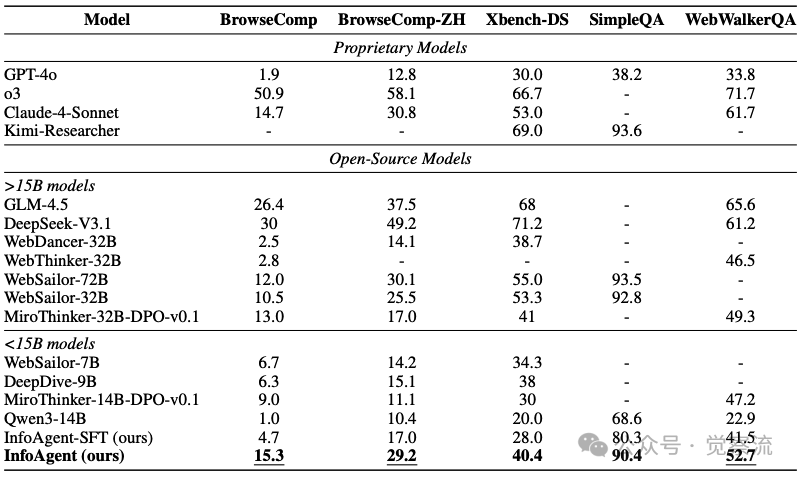
在深度研究基准上的评估
上表全面展示了InfoAgent与其他开源和专有模型在五个基准测试上的对比结果。InfoAgent在BrowseComp达到15.3%,在开源<15B参数模型中表现最佳,并超越了WebSailor-72B(12.0%)和MiroThinker-32B-DPO-v0.1(13.0%)等更大模型。在中文基准BrowseComp-ZH上,InfoAgent达到29.2%准确率,超越WebSailor-32B(25.5%);在Xbench-DS上达到40.4%,在WebWalkerQA上达到52.7%,均优于同类模型。
这些数字背后的实际意义是什么?15.3%的准确率意味着,在100个复杂研究问题中,InfoAgent能正确回答15个左右,而其他开源模型可能只能回答不到5个。虽然看起来不高,但考虑到这些问题的复杂性(平均需要20.3次工具调用),这已经显著优于其他开源模型。在信息获取至关重要的场景中,这10%的差距可能就是"找到关键治疗方案"与"一无所获"的区别。
更值得注意的是,尽管所有训练数据均为英文,InfoAgent在中文基准上的出色表现(29.2%)展示了其强大的跨语言泛化能力。这揭示了一个重要洞见:核心推理能力不依赖于语言特定知识,而更多基于对问题结构和逻辑关系的理解。对于多语言用户而言,这意味着无论你使用何种语言提问,InfoAgent都能提供高质量的复杂问题解决方案。
两大瓶颈的解决方案
InfoAgent通过创新的数据合成管道和自托管搜索工具,有效解决了DRA领域的两大核心瓶颈:
数据合成管道采用实体树构建、实体模糊化三阶段处理和约束集优化,系统性增加问题难度,确保需要长视野搜索和多步推理,产生平均20.3次工具调用的高质量训练数据。这一管道的关键在于:它不是简单地增加工具调用次数,而是通过精心设计的问题结构,强制模型进行真正的多步推理。
自托管搜索工具提供精细控制的输出,避免商业API限制,采用多级过滤机制(BM25+嵌入模型+重排序+LLM提炼)确保内容质量,并通过缓存机制和混合服务策略优化系统性能。训练和推理使用优质工具带来显著性能提升,使InfoAgent在多个基准测试中超越更大规模的开源模型。
对开发者的实用启示
构建高质量DRA时,应关注以下关键点:
构建高质量训练数据:
- 确保问题需要多步推理而非浅层匹配:通过实体模糊化和约束集优化,确保问题无法通过简单搜索解决
- 监控工具调用链长度:目标平均20+次且分布广泛,避免数据过于简单
- 实施严格的可解性验证:使用先进模型测试问题难度,确保问题既具挑战性又可解决
投资搜索工具质量:
- 实现多级内容过滤机制:BM25基础过滤、嵌入模型语义匹配、重排序模型精炼
- 开发专用片段生成能力:不超过60词的精准摘要,确保信息密度和相关性
- 优化系统性能:缓存机制提高训练吞吐量,混合服务策略应对长尾问题
重视SFT冷启动:
- 针对复杂任务设计高质量SFT数据:确保模型首先学习正确的长视野搜索行为
- 混合长短轨迹训练:平衡性能与上下文限制,确保模型既能解决复杂问题又不会频繁耗尽上下文
- 优先植入长视野搜索行为:为RL阶段的性能飞跃奠定基础
超越当前局限
InfoAgent揭示了未来发展方向:突破上下文长度限制,采用原生长上下文窗口的基础模型和更先进的RL基础设施;拓展数据来源,从维基百科扩展到更广泛网络;探索过程奖励机制,优化奖励设计以提升训练效率;增强跨语言能力,开发多语言深度研究智能体。
特别值得注意的是,研究探索了过程奖励机制对RL训练的影响。通过存储问题涉及的实体和源网页URL,计算轨迹中目标实体的召回率作为额外奖励
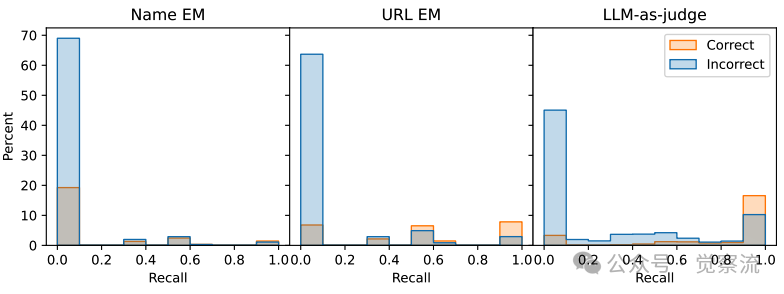
不同方法计算的召回率分布情况
上图显示了三种召回率计算方法的分布差异:名称精确匹配(EM)、URL精确匹配(EM)和LLM评估。其中,LLM评估方法能获得更多的非零召回奖励。
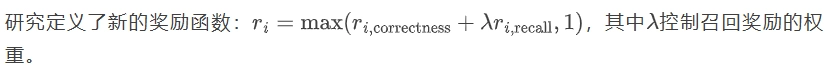
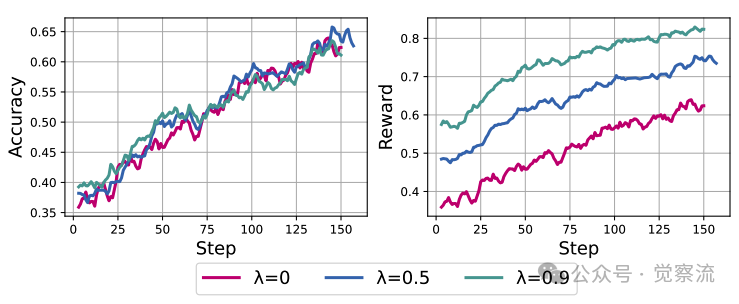
不同奖励权重下的训练曲线

这一发现对理解RL训练机制具有重要启示:过程奖励虽能提升训练信号的丰富度,但在当前任务复杂度下,其对最终性能的提升有限。研究提出两个假设解释这一现象:(1)召回奖励添加到最终奖励中,但发现目标实体的确切步骤未获得明确的正向反馈,使模型难以从这些轨迹中学习;(2)训练数据集相对简单,正确性奖励已足够教会模型必要的技能。
让信息检索真正"懂你"
通过InfoAgent的实践,我们看到解决深度研究智能体的两大瓶颈——高质量训练数据和优质搜索工具——是提升DRA性能的关键。这些经验不仅适用于信息检索领域,也为构建能够真正与现实世界交互的智能体提供了重要启示。
InfoAgent的价值不仅在于技术指标的提升,更在于它让信息检索真正"懂你":当你提出复杂问题时,它不会简单地返回表面相关但缺乏深度的答案,而是像一位经验丰富的研究员,通过多步推理、信息整合和策略调整,为你找到真正需要的答案。
在信息过载的时代,这种深度研究能力不是奢侈品,而是必需品。InfoAgent的实践表明,通过精心设计的数据合成管道和高质量工具环境,我们能够构建真正理解并解决复杂问题的智能体,让信息检索从"找到相关信息"迈向"解决实际问题"的新阶段。
InfoAgent的实践为我们指明了方向——通过高质量训练数据和优质搜索工具,我们可以构建真正理解你需求、能够深入挖掘复杂答案的智能体。这不仅是技术的进步,更是人机协作研究方式的革新。