当碳基生物还在为写文献综述,打开了一百个浏览器窗口时,隔壁AI已经卷起来了。(doge)
两天完成人类12年工作——
医学研究领域中,系统评价(SRs)作为临床决策的黄金标准,平均耗时超过16个月,花费10万美元以上,且容易延长无效或有害治疗方法的使用。
于是多伦多大学、哈佛医学院等机构联合开发了AI端到端工作流程——otto-SR。
结合GPT-4.1和o3-mini进行筛选和数据提取,仅花费两天时间就完成了传统方法需要12年才能完成的Cochrane系统评价更新。
在多项指标上更是超越人类,基准测试中otto-SR灵敏度达96.7% (人类81.7%),特异度93.9%,数据提取准确率93.1% (人类79.7%),还发现了发现人类遗漏的54篇关键研究。
所以那些年我们在PubMed上熬的夜、掉的头发,又算什么……

擦干眼泪,下面一起来看具体实现过程。
用于系统综述自动化的智能工作流程
团队引入了一种基于LLM的端到端工作流程otto-SR,支持从初始检索到数据分析,完全自动化和人机协作的系统综述流程。
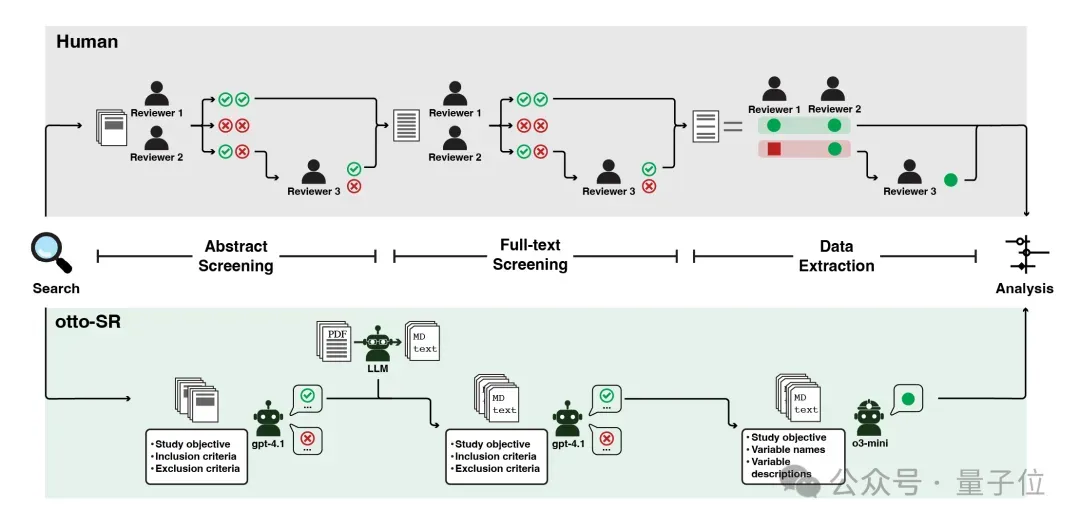
otto-SR首先会收集从原始检索中识别的RIS格式的引用文献,GPT-4.1随即会作为独立评审员进行筛选。
筛选出的文章集合将输入o3-mini-high模型进行数据提取,其中PDF格式将会由Gemini 2.0 flash处理并转换为结构化Markdown文件,并用于下游任务。
具体而言,可以细分为筛选和提取两种功能:
SR文献筛选
研究团队开发了一种筛选Agent,利用擅长指令跟随的GPT-4.1模型,并结合优化的提示策略,可以在摘要和全文阶段对文献进行筛选。
另外,该Agent会将各综述的初始目标和合格标准纳入补充说明。
研究在五项综述的完整原始检索(总计32357条引文)中,进行otto-SR筛选性能评估。
综述涵盖牛津循证医学中心(CEBM)的四种问题类型(患病率、诊断试验准确性、预后、干预效益),并横向对比双人人类评审员 (当前标准工作流程)和Elicit (基于LLM的商业系统综述自动化软件)的评估结果。
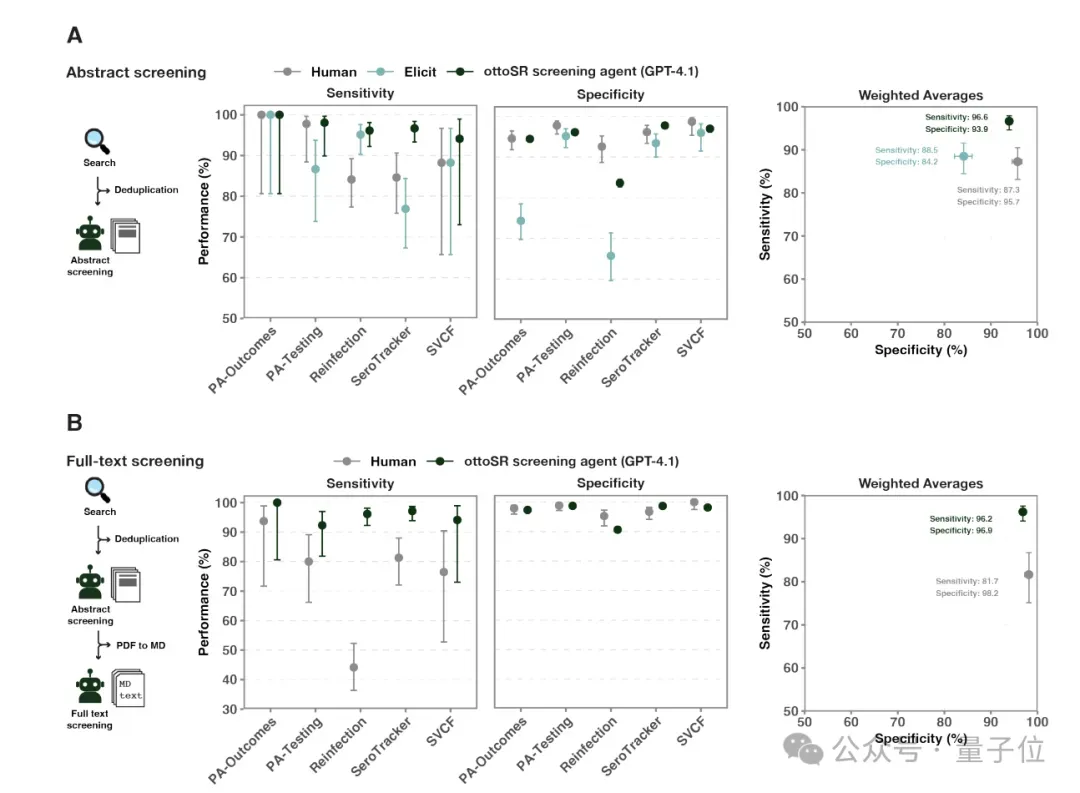
在摘要筛选阶段,otto-SR实现了最高的敏感性96.6%,在特异性上以93.9%和人类评审的95.7%相当。
在全文筛选阶段,otto-SR也同样保持了最高的敏感性96.2%,而人类评审员的敏感性显著下降至63.3%,特异性则两者都保持较高水平。
因此研究发现,otto-SR可以比传统的双人人工筛选,在捕获更多的相关研究时,还能保持足够的特异性。
SR数据提取
研究团队选择OpenAI o3mini-high模型作为提取Agent,因为其强大的科学推理能力、稳健的长上下文检索能力和成本效益,其中Prompt均采用原作者定义的变量描述。
研究在七项综述495项研究中比较otto-SR和Elicit的数据提取性能,再让双人人类评审员在每项综述的随机抽样文献子集中进行评估。
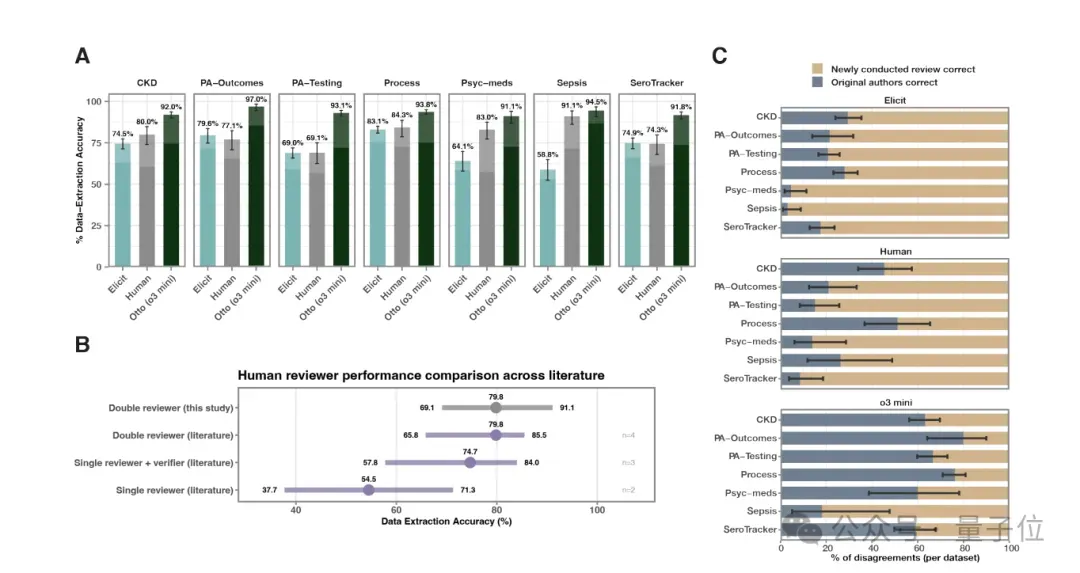
结果发现,otto-SR的平均加权准确率可达93.1%,远高于双人人类评审员的79.7%和Elicit的74.8%。
另外,为了解决部分情况下,otto-SR的提取值与原综述作者存在差异,团队引入盲法评审员小组进行抉择,其中在69.3%的案例中选择支持otto-SR。
相比之下,盲法评审员小组只在28.1%的案例中支持双人人类提取员,在22.4%的案例中支持Elicit。
这进一步体现了otto-SR在数据提取性能上的优越性,显著高于其他方法。
可快速重现和更新综述
为了评估otto-SR的实际适用性,团队对Cochrane数据库的2024年4月期SRs进行完整复现,而这些系统综述通常用于为临床指南提供信息。
将检索更新至2025年5月8日,针对可用的12篇综述,共识别出146276条引文,然后经过去重处理后,交由otto-SR根据原标准进行筛选。
再将结果过滤至与原始检索截止日期一致,otto-SR共确定了54项被遗漏的合格研究(中位数2,IQR:每项综述1至6.25),另外经过人工评审后,发现otto-SR错误纳入了10篇假阳性文章,其中九篇都可能包含相关数据。
而将日期扩展回2025年5月8日,则多出14项合格研究(总计n=64,中位数2.5,IQR 每项综述1至7.25),包含另外2篇假阳性文章,其中1篇包含相关数据。
以上工作将符合条件的文章数量翻了一倍,并让研究人员需要12个工作年才能完成的工作,缩短至48小时内。
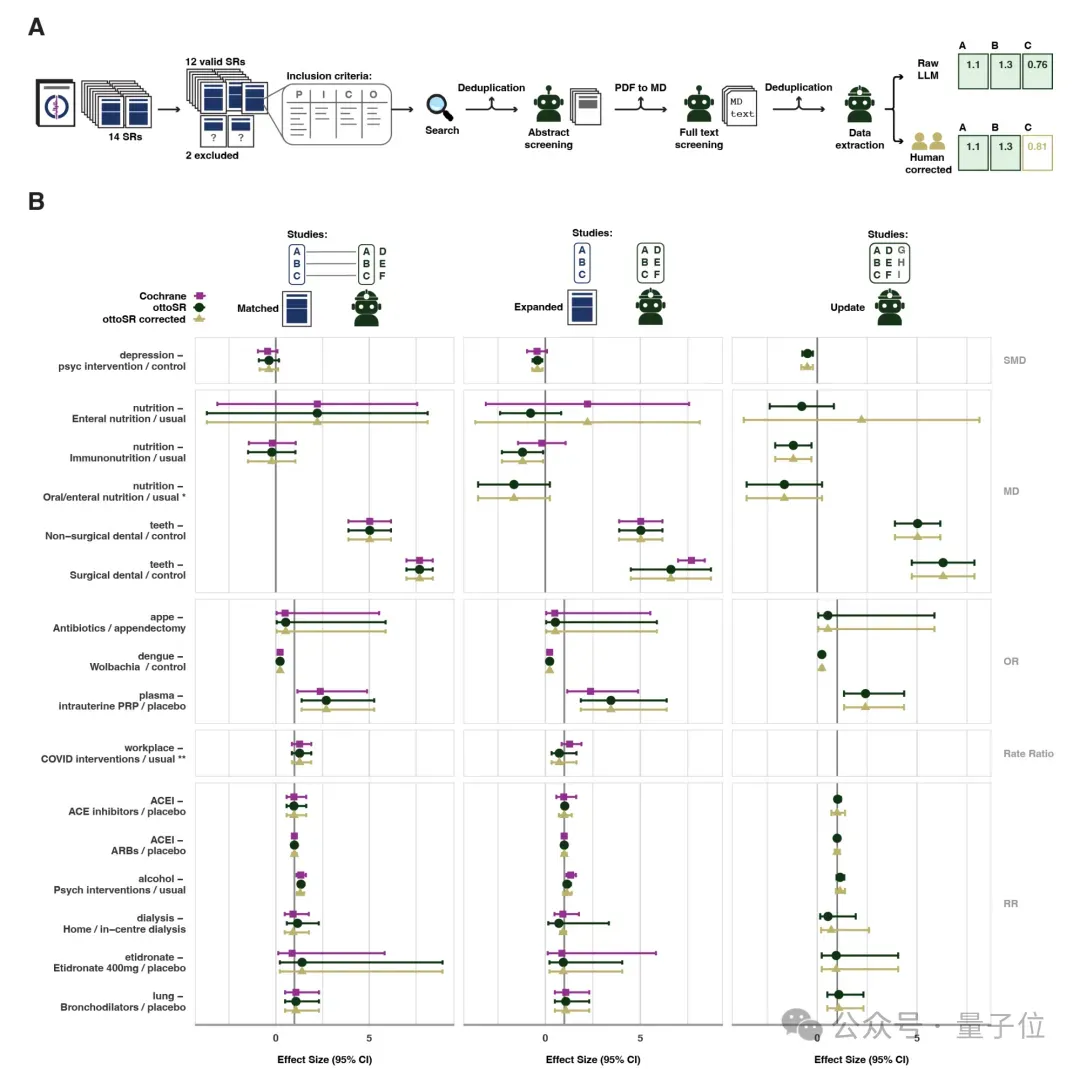
将提取数据与原综述进行Meta分析,涉及三个比较组:
- 匹配组otto-SR与原Cochrane分析中包含的相同文章集。
- 扩展组包括otto-SR识别的所有合格研究,过滤至原始检索截止日期。
- 更新组评估所有文章,检索截止日期更新为2025年5月8日。
另外考虑到可能存在的数据提取任务,还引入双人人工审查为每个组得出校正值,即移除假阳性文章和添加假阴性文章。
在匹配组中,otto-SR生成的Meta分析效应估计值,与原Cochrane数据和校正数据集的95%CI重叠。
在扩展分析中,则发现有两篇综述产生了新的统计学意义,也存在一篇综述失去了意义。
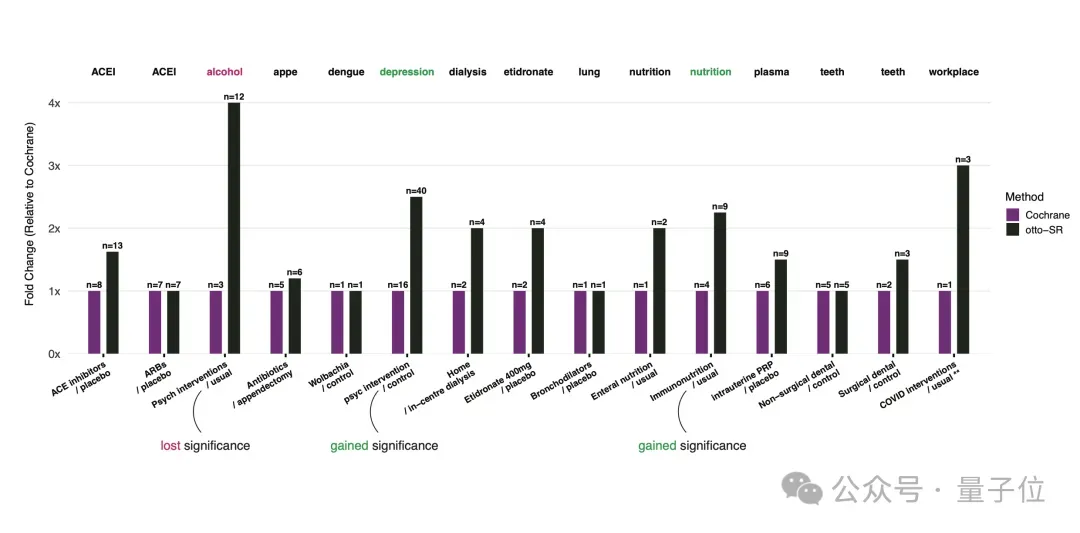
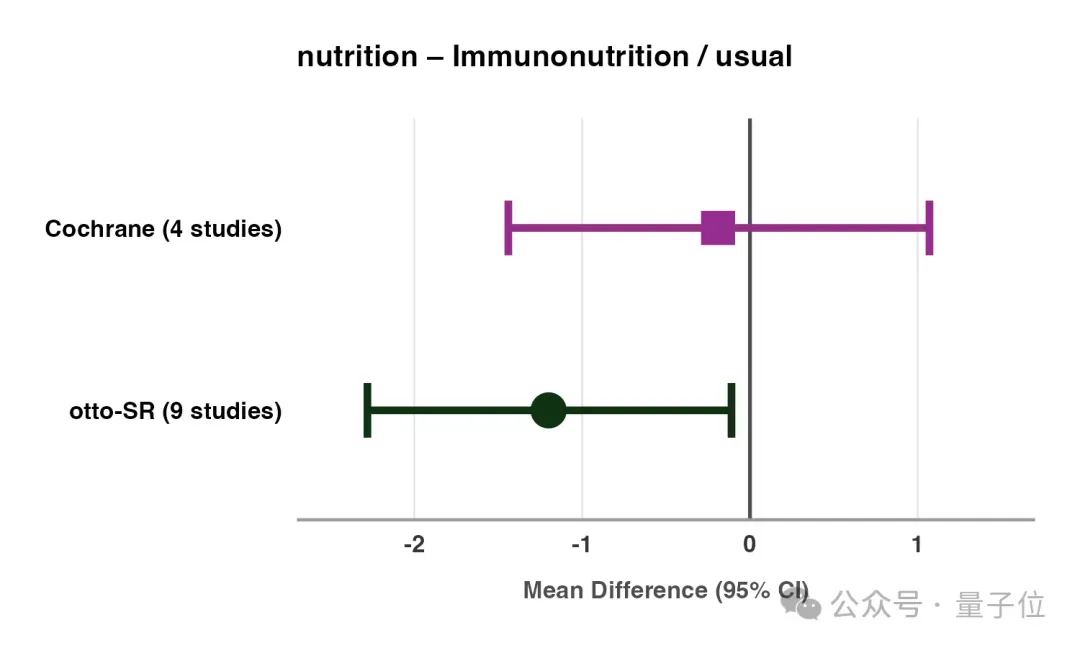
例如在营养领域综述中,otto-SR识别出5项额外研究,并发现了一个有趣的事实:胃手术前进行术前免疫增强,可能会将平均住院时间缩减一天。
otto-SR的出现,将会极大地缓解系统评价缓慢而费力的过程,在未来,可能将会从需要数月甚至数年才能完成的工作缩减至几个小时或几分钟,从而可以更快地对新疗法或者大流行病做出反应。

另外,一些因为资金不足而缺乏进行系统评价的地区,也能够享受到前沿医学,正如作者在文章末尾写道:
简言之,黄金标准已不再属于人类。In short, the gold standard is no longer human.


