第一作者陈昌和是美国密歇根大学的研究生,师从 Nima Fazeli 教授,研究方向包括基础模型、机器人学习与具身人工智能,专注于机器人操控、物理交互与控制优化。
第二作者徐晓豪是美国密歇根大学机器人学院博士生,研究涵盖3D 感知、视觉语言模型驱动的多模态异常检测及鲁棒三维重建。
共同第一作者 Quantao Yang 是瑞典皇家理工学院博士后,师从 Olov Andersson 教授,研究聚焦于利用视觉语言模型与大型语言模型提升自主系统在动态环境中的感知与导航能力。
密歇根大学和瑞典皇家理工学院的研究团队提出了 ViSA-Flow 框架,这是一种革命性的机器人技能学习方法,能够从大规模人类视频中提取语义动作流,显著提升机器人在数据稀缺情况下的学习效率。该方法在 CALVIN 基准测试中表现卓越,仅使用 10% 的训练数据就超越了使用 100% 数据的现有最佳方法。

- 作者: Changhe Chen, Quantao Yang, Xiaohao Xu, Nima Fazeli, Olov Andersson
- 机构: 密歇根大学、瑞典皇家理工学院
- 网页: https://visaflow-web.github.io/ViSAFLOW
- 论文链接:https://arxiv.org/abs/2505.01288
- 代码开源: 即将发布

研究背景与挑战
机器人模仿学习在使机器人获得复杂操作技能方面取得了显著成功,但传统方法面临一个根本性限制:需要大量精心策划的机器人数据集,收集成本极其昂贵。这已成为开发能够执行多样化现实世界任务的机器人的关键瓶颈。
相比之下,人类展现出通过观察他人学习新技能的非凡能力。无论是面对面学习、观看教学视频还是体育转播,人类本能地专注于语义相关的组件。例如,学习网球时,我们自然地关注球员的身体动作、球拍处理技巧和球的轨迹,同时有效过滤无关的背景信息。
核心创新:语义动作流表示
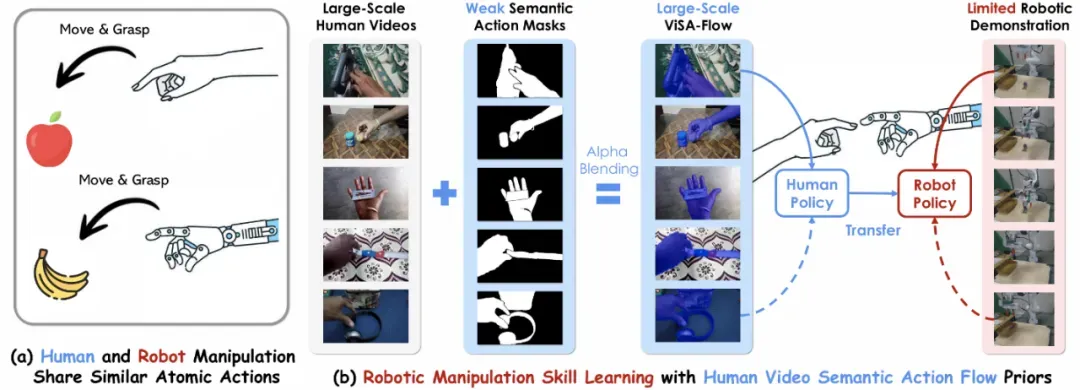
人类和机器人操作共享相似原子动作
ViSA-Flow 框架的核心创新在于引入了语义动作流(Semantic Action Flow)作为中间表示,捕捉操作器 - 物体交互的本质时空特征,且不受表面视觉差异影响。该框架包含以下关键组件:
1. 语义实体定位
利用预训练的视觉语言模型(VLM)对操作器(如 "手"、"夹具")和任务相关物体(如 "红色方块")进行文本描述定位,然后使用分割模型(如 SAM)生成初始分割掩码。
2. 手 - 物体交互跟踪
由于语义分割在连续帧间的不稳定性,研究团队提出跟踪正确分割的手 - 物体交互掩码。通过在初始掩码内密集采样点,使用点跟踪器(如 CoTracker)估计这些点在序列中的 2D 图像轨迹。
3. 流条件特征编码
为产生最终的 ViSA-Flow 表示,研究团队将流信息编码为丰富的特征向量,同时保留视觉上下文。使用跟踪点轨迹生成空间局部化放大掩码,通过放大因子调制感兴趣区域内的像素强度。
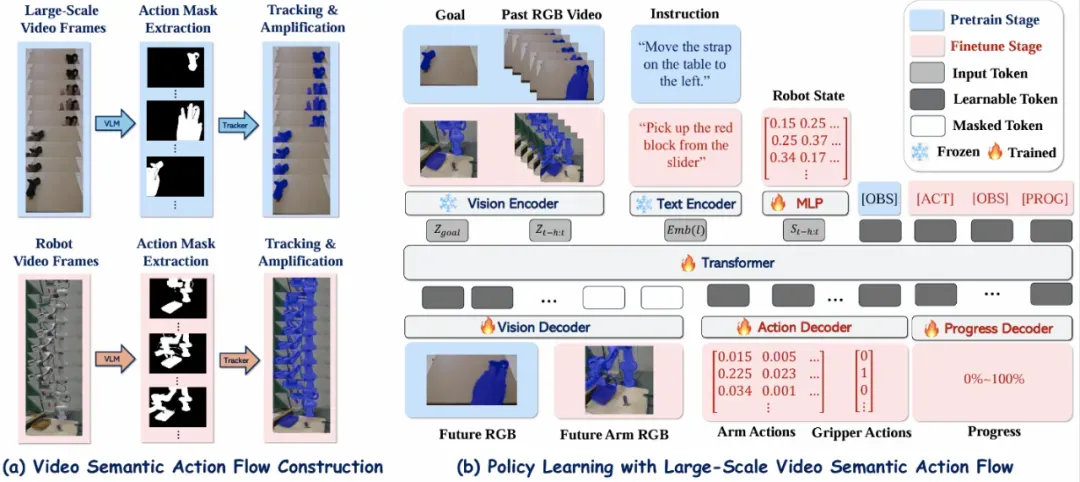
ViSA-Flow 架构和策略学习框架图
两阶段学习框架
第一阶段:预训练 - 学习 ViSA-Flow 动态先验
使用大规模人类视频数据集,预训练生成模型以建模 ViSA-Flow 空间内的动态。模型学习基于过去上下文和语言指令预测未来表示,目标函数为:
L_pretrain (ψ) = E [||g_ψ(z≤t, l)[OBS] - z_{t+1:t+n}||²]
第二阶段:微调 - 策略适应
使用少量机器人演示数据集微调模型,学习目标策略。采用多任务目标函数,结合动作预测和持续动态建模:
L_finetune (ψ) = E [L_act + λ_fwd*L_obs + λ_prog*L_prog]
实验评估
CALVIN 仿真实验
研究团队在 CALVIN 基准测试上进行了全面评估,使用 ABC→D 分割,在环境 A、B、C 上训练,在未见环境 D 上进行零样本评估。
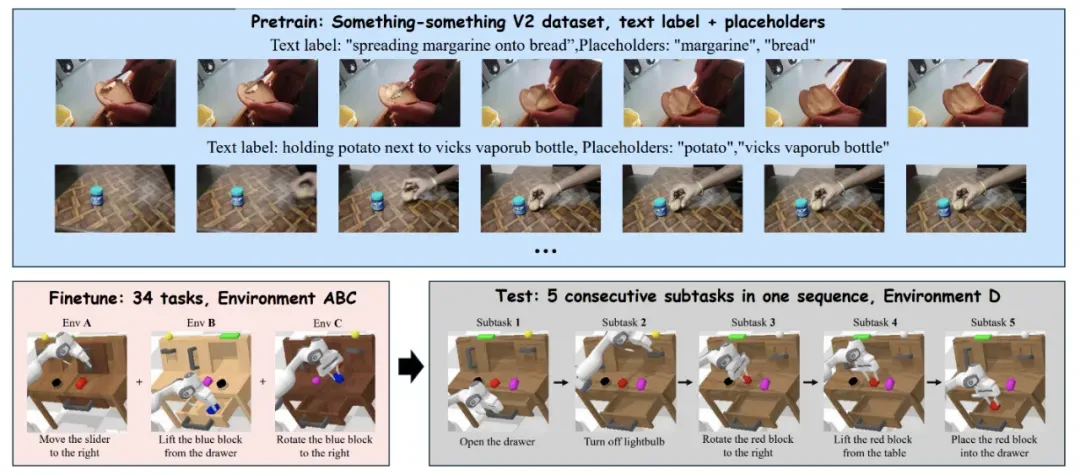
预训练,微调以及评估所使用数据集
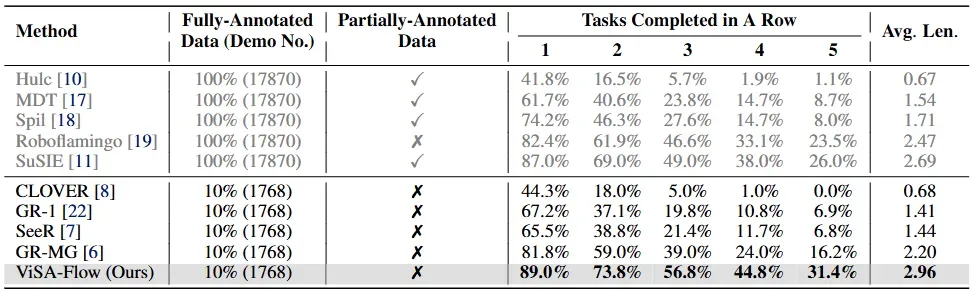
CALVIN ABC→D 基准测试的对比评估结果
关键发现
1. 数据效率优势:ViSA-Flow 仅使用 10% 的注释机器人轨迹(1,768 个),就超越了所有基线方法,包括使用 100% 数据的方法。
2. 连续任务性能:在 5 个连续任务完成方面,ViSA-Flow 达到 31.4% 的成功率,几乎是使用 10% 数据的次佳方法 GR-MG(16.2%)的两倍,甚至超过了使用 100% 数据训练的 SuSIE(26.0%)。
3. 平均序列长度:2.96 的平均序列长度进一步证明了 ViSA-Flow 在处理长时程操作任务方面的有效性。
消融研究
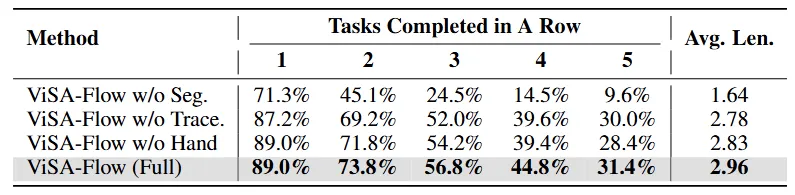
评估 ViSA-Flow 关键组件贡献的消融研究结果
消融研究结果表明:
- 移除语义实体定位显著降低性能,5 任务序列成功率从 31.4% 降至 9.6%
- 省略时间跟踪阶段使平均成功长度从 2.96 降至 2.78
- 排除操作器定位导致适度性能下降
真机实验
研究团队在真实世界环境中评估了 ViSA-Flow 的性能,包括两个单阶段操作任务和一个长时程操作任务。
实验设置:
- 使用 7 自由度 Franka Emika Panda 机械臂
- 通过 Oculus 应用程序进行遥操作数据收集
- 双摄像头设置(眼内、眼外)提供 RGB 观察

真机实验设置
结果分析:
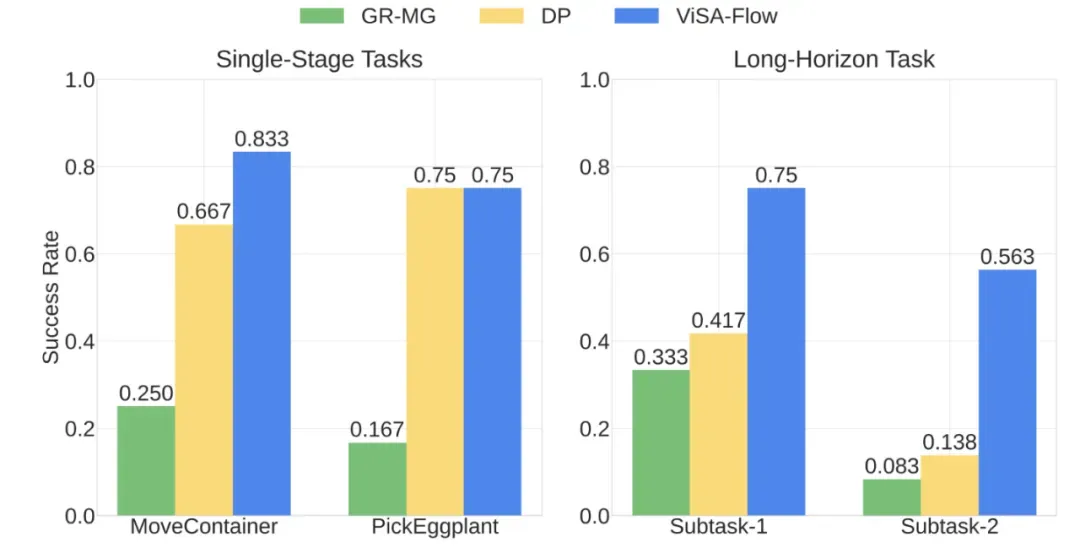
真实世界实验结果图表
- 单阶段任务:ViSA-Flow 在 MoveContainer 和 PickEggplant 任务上显著优于 GR-MG
- 长时程任务:ViSA-Flow 达到 56.3% 的整体成功率,而 GR-MG 和 DP 分别仅达到 8.3% 和 13.8%
定性分析
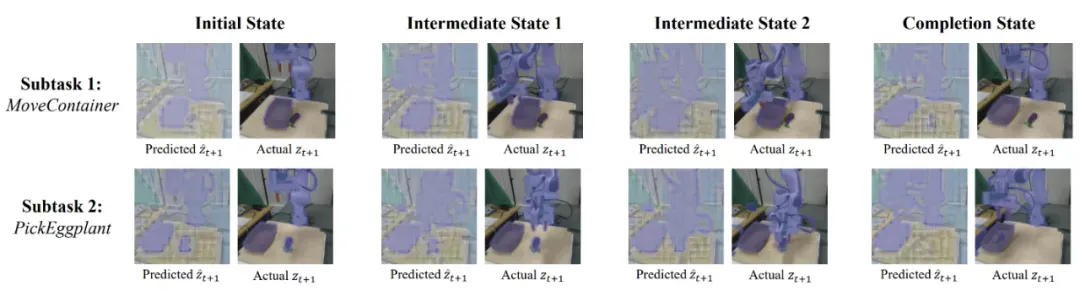
真实世界长时程任务的定性结果可视化
定性结果显示,ViSA-Flow 的单步预测在整个长时程执行过程中与真实流保持紧密对齐:
- 模型持续聚焦于机器人夹具和任务相关物体
- 空间支持随场景转换平滑连贯地演化
- 在两个连续子任务中保持相同的准确性水平
奖励差异水平的性能分析
为评估 LLM 在不同难度水平下选择更优设计的能力,研究团队采用了难度加权准确率 (DWA) 指标进行分析。结果显示,ViSA-Flow 在处理细微性能差异的任务时表现更稳定,证明了语义动作表示的有效性。
提示设计分析
研究还探索了不同组件对框架性能的影响:
1. 语义分割的重要性:准确的语义实体识别是框架成功的关键
2. 时间跟踪的必要性:一致的点对应关系对保持时间动态至关重要
3. 跨域泛化能力:语义表示有效缓解了视觉外观差异的影响
技术优势与局限性
技术优势
1. 数据效率:仅需少量机器人演示数据即可达到优异性能
2. 跨域泛化:有效利用人类视频知识转移到机器人执行
3. 长时程稳定性:在复杂序列任务中保持稳定表现
4. 语义一致性:关注任务关键交互而非视觉外观
当前局限性
1.3D 几何建模缺失:缺乏显式的 3D 几何和接触动力学建模
2. 预训练组件依赖:依赖预训练 VLM 组件可能限制新领域适应性
3. 物理交互精度:在需要精细物理交互的任务中可能存在限制
未来发展方向
1. 物理建模增强:将接触物理学整合到 ViSA-Flow 表示中
2. 端到端训练:减少对预训练组件的依赖,实现联合训练
3. 强化学习集成:将 ViSA-Flow 先验与强化学习算法结合
4. 大规模预训练:扩展到网络规模的视频语料库进行预训练
研究意义与展望
ViSA-Flow 为机器人学习领域带来了重要突破,证明了从大规模人类视频中提取语义表示进行机器人技能学习的可行性。该方法不仅在理论上具有创新性,在实际应用中也展现出强大的性能优势。
通过引入语义动作流这一中间表示,ViSA-Flow 成功桥接了人类演示视频观察与机器人执行之间的差距,为构建更加智能、高效的机器人学习系统开辟了新的研究方向。
随着技术的进一步发展和完善,ViSA-Flow 有望在工业自动化、家庭服务机器人、医疗辅助等多个领域发挥重要作用,推动机器人技术向更加智能化和普适化的方向发展。


