推理大模型虽好,但一个简单的算数问题能推理整整三页,还都是重复的“废话”,找不到重点……
一种可以把大模型的“碎碎念”转化为可控记忆条目的高效压缩方法,出现了!
R-KV开源登场:显存↓90%、吞吐×6.6、准确率=100%。
它可以通过实时对token进行排序,兼顾重要性和非冗余性,仅保留信息丰富且多样化的token,从而解决大模型推理时的冗余问题。
让“长时间推理”不再是奢侈品。

项目详情可见文末链接。
R-KV三步走:冗余识别+重要性评估+动态淘汰
链式思考(Chain-of-Thought,CoT)让LLM解题思路清晰可见,却也让推理长度指数级膨胀。
以DeepSeek-R1-Llama-8B为例,一道AIME数学题就能写出3.2万个Token:模型权重15.5GB,KV缓存再吃4.1GB——显存瞬间见底。
现有KV压缩方法(SnapKV、StreamingLLM、H2O等)主要针对长输入设计,可一旦模型在输出端开始“碎碎念”,相似句子之间互相打高分注意力,反而让“按注意力删低分”策略失灵:
造成关键步骤被误删、重复内容却被保留、准确率断崖式下跌等问题。
而R-KV通过以下步骤,在模型解码时实时压缩KV缓存来处理冗余的键/值(KV)标记,仅保留重要且非冗余的标记:
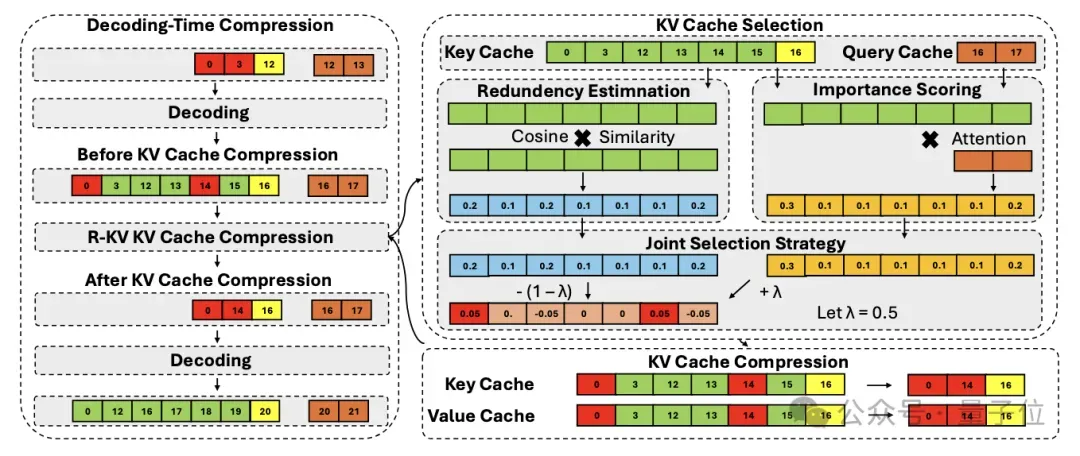
- 边生成边压缩(Decoding-Time Compression)Token还没写进KV,就先判断“去留”,彻底阻断显存膨胀。
- 重要性打分(Importance)多头注意力综合评估,每个Token对后续答案的贡献度。
- 冗余打分(Redundancy)计算Key向量余弦相似度,找出“复读机”式内容。
- 联合淘汰(Joint Eviction)按「高重要+低冗余」优先级实时调度KV配额,λ≈0.1时效果最佳。
整个流程训练-free、模型-agnostic,无需改动模型结构,直接“即插即用”。因此可以直接被用到强化学习的采样过程中,非常灵活。
可视化:R-KV vs. SnapKV

上图展示了R-KV和纯注意力基线SnapKV在相同解码步骤中选择了哪些token。灰色=未选;由浅到深红=被越多注意力头选中。
可以看到,SnapKV关注点集中在离当前Query最近的局部片段,甚至重复保留多次「3 students are leaving early…」等无用自述。
而R-KV选出的Token横跨整段推理:题目关键词30 students,关键中间值24,12及最终答案全部被保留,此外语义覆盖面更广。
通过结合注意力强度与冗余过滤,R-KV保留了重要上下文并去除噪声,成功完成任务;而SnapKV误删关键信息导致答案错误。
得到结果:R-KV有更广泛的覆盖范围、更高的信息多样性和更显著的去冗余能力。
性能测试:准确率不降反升
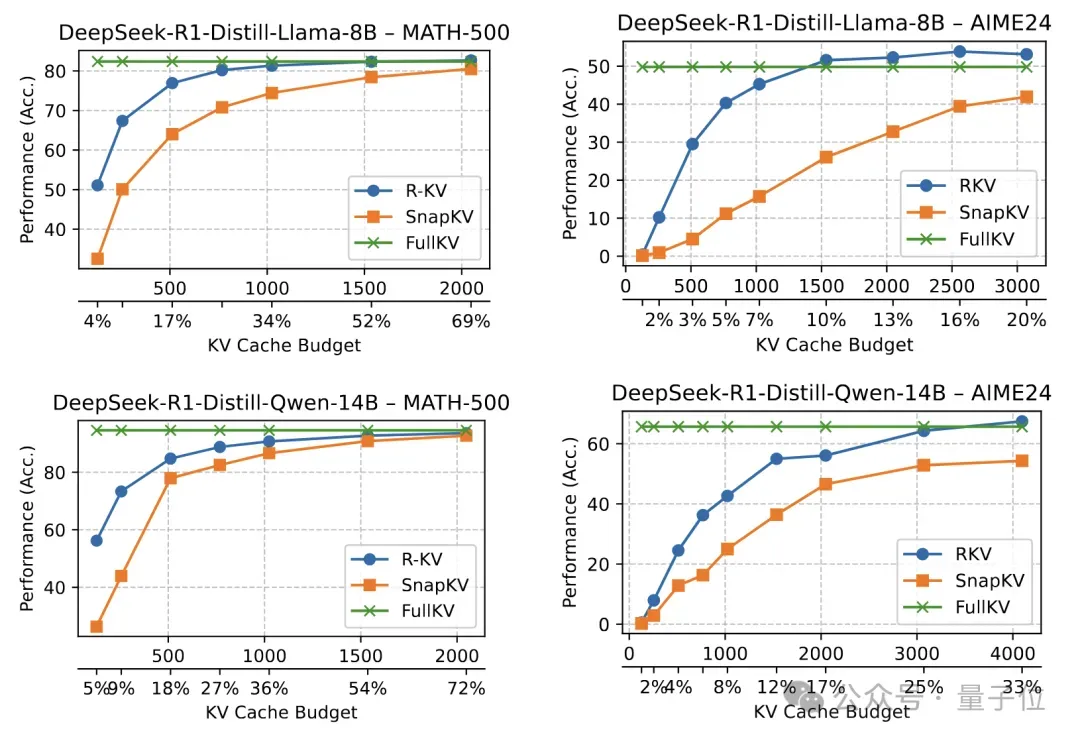
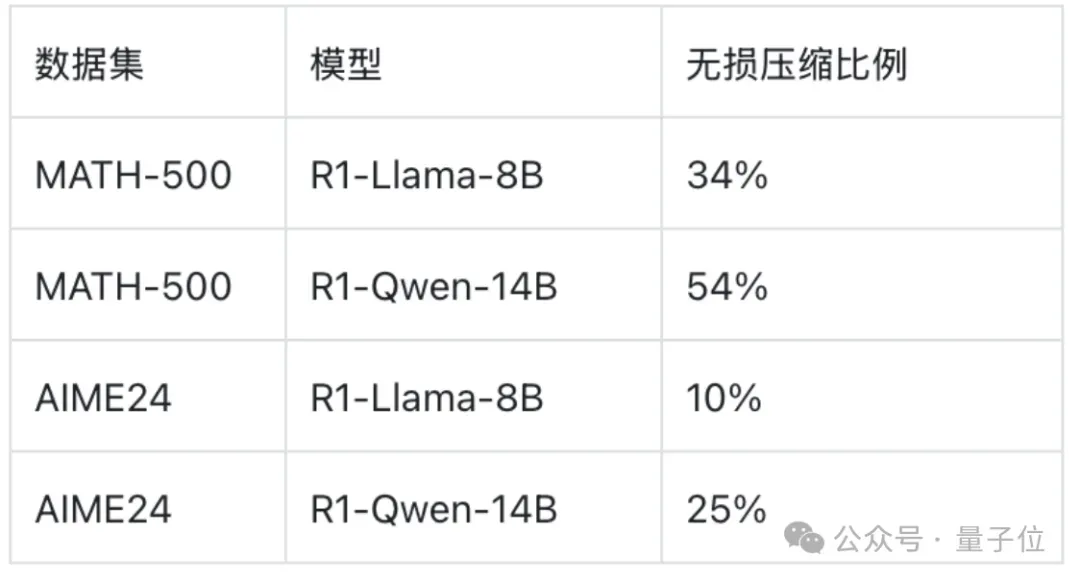
可以看到,R-KV在具有挑战性的数学基准测试中大幅超越了基线,甚至超过了完整的KV。
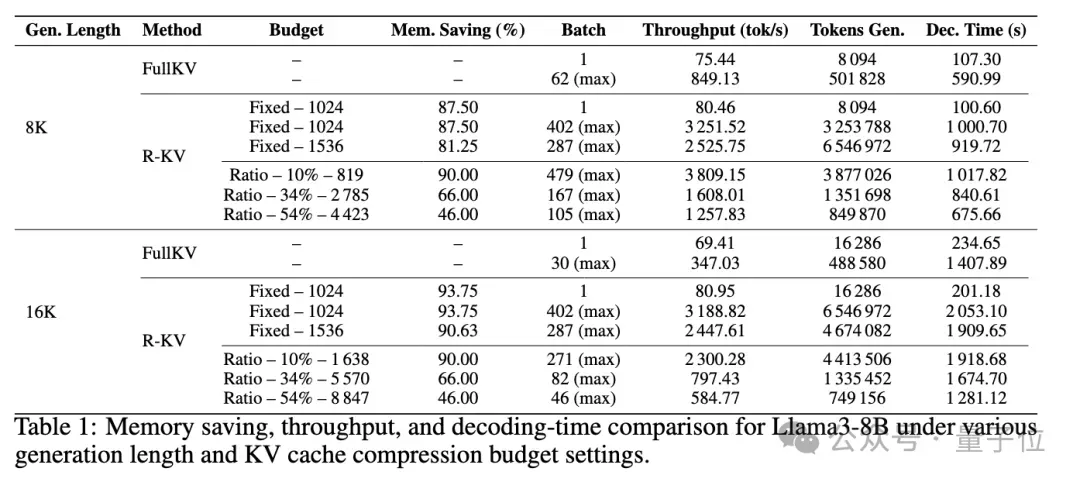
在计算开销上,R-KV引入了重要性评分和冗余评分的额外计算,但总体开销适中,通常会被压缩KV缓存带来的注意力成本降低所抵消。随着序列长度的增加,这种权衡变得越来越有利。
对内存节省和端到端吞吐量提升进行实时分析,可以看到,当批处理大小为1时,R-KV在吞吐量上略优于FullKV。这表明R-KV通过减少注意力计算所实现的加速效果超过了R-KV自身的计算开销。
然而,这种直接的速度提升仅占整体收益的一小部分,R-KV带来的主要吞吐量提升来自于KV缓存压缩,使模型能够支持显著更大的推理批处理大小。
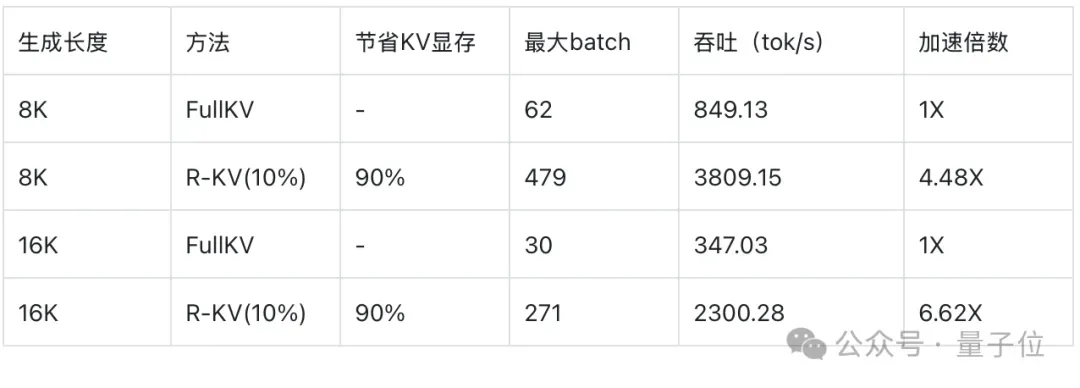
对基于比例和固定KV缓存预算的端到端吞吐量进行评估,发现R-KV始终能够实现比FullKV大得多的批处理大小和更高的吞吐量,同时不损失任务性能。
R-KV的适用场景如下:
- 边端设备长链推理显存断崖缩减,让消费级GPU甚至手机NPU也能跑
- 多轮Agent反思-重写-自评等复杂流程不再受显存限制。
- 直接用于加速强化学习的采样过程training-free的方法即插即用。
论文PDF:https://arxiv.org/pdf/2505.24133.pdf
项目主页:https://zefan-cai.github.io/R-KV.page/
代码仓库:https://github.com/Zefan-Cai/R-KV


