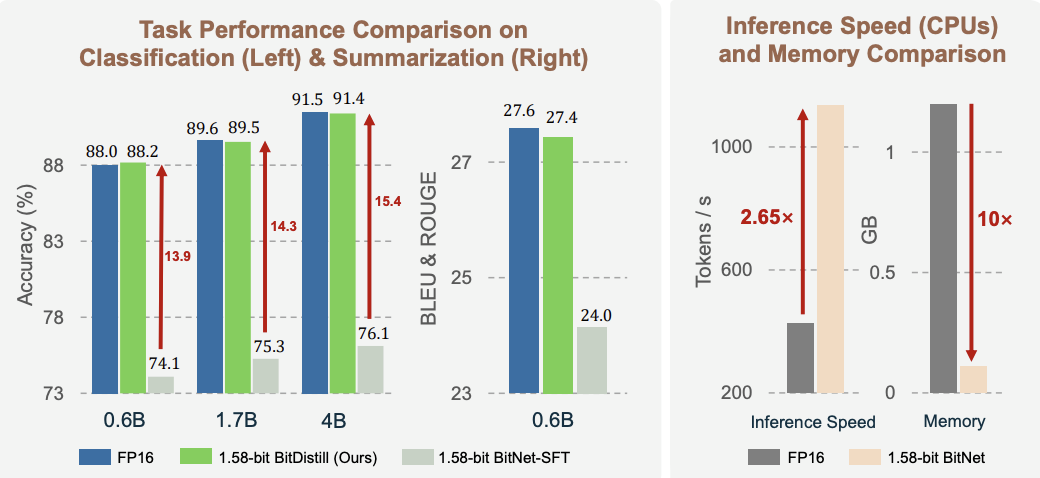
1.58bit量化,内存仅需1/10,但表现不输FP16?
微软最新推出的蒸馏框架BitNet Distillation(简称BitDistill),实现了几乎无性能损失的模型量化。
该框架在4B及以下的Qwen、Gemma上已被证实有效,理论上可用于其他Transformer模型。

同等硬件性能下,使用该方法量化后的推理速度提升2.65倍,内存消耗仅1/10。
网友看了之后表示,如此一来昂贵的GPU将不再是必需品,英伟达的好日子要到头了。
BitDistill框架设计
BitDistill包含三个依次衔接的阶段,分别是模型结构优化(Modeling Refinement)、继续预训练(Continue Pre-training)和蒸馏式微调(Distillation-based Fine-tuning)。
建模结构优化的主要目标是为1.58-bit模型训练提供结构层面的支持,缓解低精度训练中常见的优化不稳定问题。
在传统的全精度Transformer模型中,隐藏状态的方差通常在预训练时已被良好控制。然而,当模型被压缩到极低位宽(如1.58-bit)后,激活值在经过量化前的分布可能会出现方差膨胀等问题,从而导致训练过程震荡甚至失败。
为了应对这一问题,BitDistill在每一个Transformer层中引入了一个名为SubLN(Sub-layer LayerNorm)的归一化模块。
具体来说,SubLN的插入位置有两个,一是在多头自注意力模块的输出投影之前,二是在前馈网络的输出投影之前。
这样的插入方式,不改变主干计算路径,仅在关键位置对信号做规范化调整,使得量化后模型具备更好的收敛性。
这种设计使得量化前的表示能够在进入下一计算阶段前被重新归一化,有效抑制激活尺度的发散,提升训练稳定性。
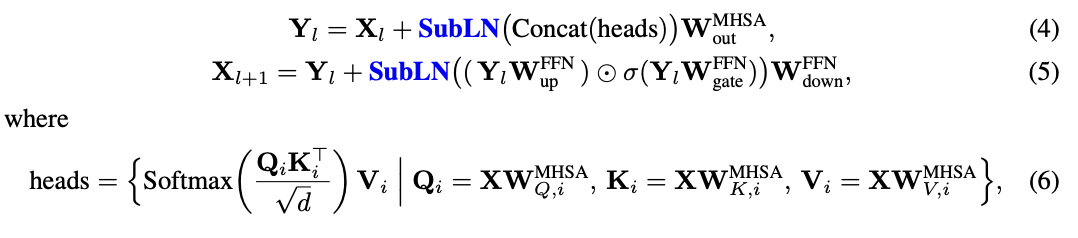
经过第一阶段的结构修改后,模型虽具备量化训练的能力,但如果直接将其用于特定任务的微调,尤其是在模型规模较大时,仍会遭遇显著的性能损失。
也就是说,随着模型参数增大,1.58-bit模型与其全精度版本之间的性能差距反而进一步扩大。
为了缓解这一问题,BitDistill设计了一个轻量级的继续预训练阶段。在此阶段中,模型会在少量通用语料上进行自回归语言建模训练,训练目标为最大化条件概率。
这一过程并不涉及特定任务数据,也不需精调标签,仅是让模型权重从全精度空间缓慢迁移到适合1.58-bit表示的分布上。
换句话说,这个阶段的本质是一种预适配训练,让模型“学会如何被量化”,避免在微调阶段才仓促适应低位宽带来的信息丢失。
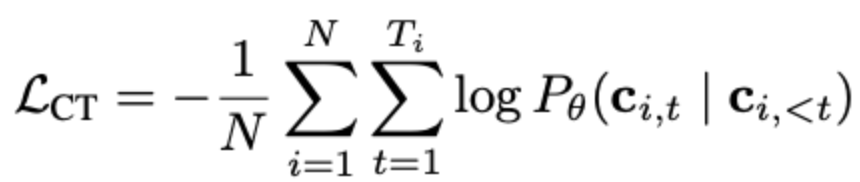
完成结构调整与继续预训练后,模型被正式引入到具体下游任务中进行1.58-bit量化训练。
为了弥补量化后模型在表达能力上的损失,BitDistill采用了一种双重蒸馏机制——Logits蒸馏与多头注意力蒸馏。
这一阶段的目的是从原始的全精度模型中提取关键行为模式,并引导低位宽模型在具体任务上学习这些模式,从而恢复性能。
Logits蒸馏是将全精度模型输出的类概率分布作为“软标签”,引导量化模型在预测分布上向其靠拢。具体做法是使用Kullback–Leibler散度(KL散度)来最小化两者输出分布之间的差异。
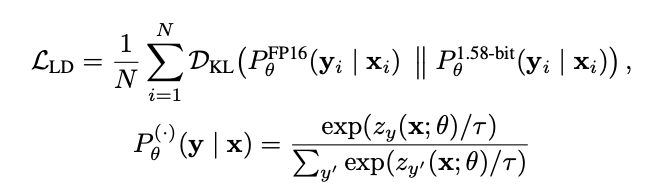
由于Transformer模型的性能很大程度依赖其注意力机制,BitDistill进一步从结构层面对注意力关系进行蒸馏。这种蒸馏不是对注意力权重做对齐,而是对Q、K、V向量构成的关系矩阵进行分布层面的模仿。
具体而言,对于选定的某一层(通常是模型后部的一层),分别从教师模型与学生模型中提取Q、K、V三组张量,并计算它们之间的点积相关性,形成关系分布矩阵。
然后通过KL散度使两者对齐,训练学生模型还原出与教师模型相似的结构依赖。
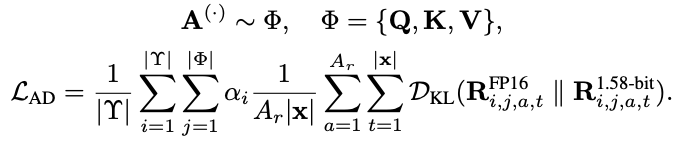
FP16无损量化至1.58bit
BitDistill展示出在多个下游任务中几乎等同于全精度模型的表现,同时显著降低了内存开销并提升了推理速度。作者在两个典型任务类型上进行了全面实验,分别是文本分类与文本摘要。
以Qwen3为基础模型,测试中的分类任务包括MNLI、QNLI与SST-2,摘要任务则采用CNN/DailyMail数据集作为标准。
分类任务中,BitDistill的1.58-bit模型在准确率与生成质量指标上与全精度微调模型(FP16-SFT)几乎一致,而显著优于直接对量化模型进行微调的BitNet-SFT。

在文本摘要任务中,BitDistill同样表现出高度保真的生成能力。
以ROUGE和BLEU等标准指标衡量,在CNN/DailyMail上,BitDistill所生成文本的BLEU为14.41,ROUGE-L为27.49,与FP16模型的13.98和27.72几乎等同,甚至在BLEU上略有超出。
相比之下,直接量化后的模型在BLEU与ROUGE上普遍下降2至3个百分点。

为了验证BitDistill在不同模型架构上的通用性,作者还将其应用于Gemma和Qwen2.5等其他预训练模型,结果BitDistill都能实现对全精度性能的高度还原。
进一步的实验表明,BitDistill在不同量化策略下也具备良好的兼容性。作者将其与常见的Block-Quant、GPTQ、AWQ等量化方法结合,在分类任务上依然能够稳定地恢复原始性能,证明该方法可作为一个独立于量化算法的上层蒸馏方案,适用于多种后量化优化场景。
One More Thing
BitStill的作者全部来自微软研究院,而且均为华人。
通讯作者为微软亚洲研究院副总裁、武汉大学校友韦福如博士。
他读博期间就曾在MSRA实习,毕业后到IBM工作,又于2010年重回微软,工作至今。

第一作者Xun Wu为清华计算机硕士,本科毕业于中南大学,2023年开始到微软研究院实习,毕业后正式入职。

其他作者名单如下:

论文地址:https://arxiv.org/abs/2510.13998


