一、研究背景
任务定义
这篇论文研究的核心问题是:小型语言模型(SLMs,参数量在1-12B之间)是否能够在智能体系统(Agentic Systems)中替代大型语言模型(LLMs)。
智能体系统指的是那些需要调用外部工具、生成结构化输出、执行函数调用的AI应用场景,比如:
- 检索增强生成(RAG)
- API调用和工具使用
- 代码生成和执行
- 结构化数据提取
研究动机
长期以来,业界有个默认共识:"模型越大越好"。但这篇论文挑战了这个观点,提出了一个颠覆性的发现:
在智能体场景下,小模型不仅够用,而且往往更优秀。原因有三:
- 成本优势惊人:在保证任务成功率的前提下,SLMs的成本比LLMs低10-100倍
- 速度更快:推理延迟显著降低,p95延迟从4.8秒降到1.6秒
- 能耗更低:边缘设备部署友好,能源消耗大幅下降
更关键的是,智能体任务的瓶颈往往不是"世界知识"或"推理深度",而是I/O协调、工具调用的准确性、输出格式的严格遵守。在这些方面,小模型配合约束解码(Constrained Decoding)反而更可靠。
核心贡献
论文提出了一套完整的SLM智能体工程实践体系:
- 系统化分类:整理了当前最适合智能体的SLM家族(Phi-4、Qwen-2.5、Gemma-2、Llama-3.2等)
- 架构设计:提出了"SLM为主、LLM兜底"的不确定性感知路由架构
- 工程指标:定义了关键评估指标,包括CPS(Cost per Successful task)、可执行率、Schema有效性等
- 部署方案:给出了LoRA/QLoRA微调、INT4量化、蓝绿发布的实战playbook
二、相关工作梳理
1. 工具使用与函数调用的演进
Toolformer (2023) 开创性地证明了中等规模模型可以通过自我标注学习API调用,不需要大规模人工标注。
Gorilla (2023) 和 Berkeley Function-Calling Leaderboard (BFCL) 进一步明确:函数调用的准确性更依赖于参数正确性和Schema严格遵守,而非参数量。
StableToolBench (2024-2025) 引入了虚拟API服务器,解决了基准测试漂移问题,让模型评估更稳定可靠。
核心洞察:工具调用是"结构化任务",不是"开放生成任务"。小模型+严格约束 > 大模型自由发挥。
2. 结构化生成技术
现代推理引擎(vLLM、SGLang、TensorRT-LLM)都集成了约束解码技术:
- Outlines 和 XGrammar:在解码过程中根据JSON Schema或上下文无关文法(CFG)剪枝token搜索空间
- 性能提升:在负载下可实现~5×的TPOT(Time Per Output Token)加速
- 保证可解析性:生成的输出100%符合格式要求
3. 小模型训练与适配
LoRA/QLoRA:低秩适配技术让小模型微调成本降低一个数量级
- LoRA:只训练低秩矩阵,保持主模型冻结
- QLoRA:在4-bit量化基础上训练,GPU显存需求大幅降低
蒸馏配方(DeepSeek-R1-Distill、Phi-4-Mini-Reasoning):
- 思维链(CoT)SFT
- 偏好数据DPO(Direct Preference Optimization)
- 可验证奖励的短周期强化学习
三、核心方法
1. SLM代表模型盘点
论文整理了当前最适合智能体的SLM家族:
模型 | 参数量 | 上下文 | 亮点 |
Phi-4-Mini | 3.8B | 64K | 数学/编码强,推理速度快,边缘部署优秀 |
Qwen-2.5 | 0.5B-72B | 128K+ | 工具使用和格式保真度优秀 |
Gemma-2 | 2B/9B/27B | 128K | 轻量开源,编码推理强 |
Llama-3.2 | 1B/3B | 128K | 设备端专注,量化友好 |
Ministral | 3B/8B | 32K-128K | 函数调用优秀,注意力机制高效 |
Mistral-NeMo | 12B | 128K | 多语言,单GPU友好 |
DeepSeek-R1-Distill | 1.5B-70B | 32K-128K | 推理蒸馏,编码任务强 |
2. 函数调用的形式化定义
论文给出了一个严格的工程定义:

在实践中,SLMs配合强制Schema和预执行验证,能在低得多的延迟/成本下达到高ExecRate。
设计建议:
- 将格式保真度作为一等公民KPI
- 使用流式JSON + 增量验证器,快速失败
- 在CI中对Schema进行模糊测试
- 记录失败轨迹用于适配器微调
3. 不确定性感知路由架构
这是论文的核心贡献之一。系统设计如下:
复制关键机制:
- 能力注册表:为每个SLM打标签(如"擅长提取"、"擅长工具调用")
- 不确定性估计:通过logprob、自洽性等代理指标评估
- 验证器先行:小模型先尝试修复,失败才升级LLM
- 预算约束:结合成本、延迟预算动态选择模型
4. 模型成本:CPS指标
论文定义了关键指标**Cost per Successful task (CPS)**:

实验结果惊人:在约束解码+温度0下,SLMs的CPS比纯LLM基线低10-30倍!
四、实验效果
1. 消融实验:哪些因素最重要?
配置 | Schema约束 | 量化 | valid@1 | ExecRate | p95延迟 | CPS |
LLM基线 | ❌ | FP16 | 92.1% | 89.4% | 4.8s | 1.00× |
SLM-8B | ✅ | INT8 | 98.7% | 97.9% | 1.6s | 0.11× |
SLM-8B(无Schema) | ❌ | INT8 | 94.3% | 90.8% | 1.5s | 0.23× |
SLM-12B | ✅ | INT4 | 99.1% | 98.5% | 1.9s | 0.14× |
级联(SLM→LLM) | ✅ | INT8 | 99.0% | 98.6% | 2.1s | 0.18× |
关键发现:
- Schema约束是杀手锏:有无Schema约束,CPS相差一倍(0.11× vs 0.23×)
- 量化几乎无损:INT4/INT8对格式任务影响很小
- 级联架构平衡最好:准确性接近纯LLM,成本仅1/6
2. 成本-性能对比可视化
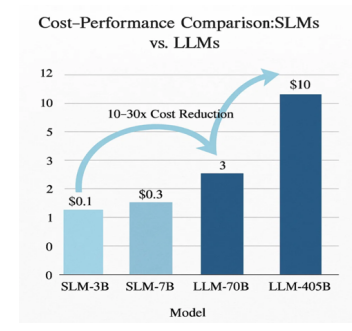 图片
图片
图中清晰展示:
- SLM-3B成本,成本0.3
- LLM-70B成本,成本10
- 实现10-30倍成本降低
3. 三个典型场景实测
场景A - 数据提取/模板化
- 模型:3-9B SLM + JSON Schema
- 结果:>99%格式有效性,仅在验证失败时调用LLM
场景B - RAG + 工具编排
- 模型:7-12B SLM(Ministral 8B、Mistral-NeMo 12B、Qwen-2.5-7B)
- 结果:可靠编排搜索和计算,仅当不确定性超过阈值τ时升级
场景C - 数学/编码推理
- 模型:Phi-4-Mini-Reasoning (3.8B)、DeepSeek-R1-Distill-7B
- 结果:快速单元测试和局部代码生成优秀,仅跨文件重构时调用大模型
五、论文总结
核心观点
- 范式转变:智能体的未来不是"越大越好",而是"小模型为主、大模型兜底"的异构架构
- 约束是关键:结构化生成场景下,约束解码 + Schema验证 > 大模型自由发挥
- 成本革命:在保证可靠性的前提下,成本可降低10-100倍
- 工程实践成熟:LoRA微调、INT4量化、路由架构已有成熟方案
局限性
- 基准漂移:结果可能无法跨API/版本迁移
- 过拟合风险:窄轨迹训练可能损害泛化能力
- 验证器依赖:过度依赖验证器可能掩盖推理错误
- 路由校准难:误判会导致错误的SLM/LLM升级决策
- 安全面扩大:工具使用引入新的安全风险
未来方向
- 执行驱动的标准化评估(包含成本/延迟/能耗)
- 更好的路由校准和选择性弃权
- Schema与验证器协同设计
- 从失败日志持续LoRA微调
- 更强的工具安全(沙箱、白名单、注入防御)
六、观点和讨论
1. 这篇论文为什么重要?
打破了AI领域的"军备竞赛"心态。过去几年,大家都在卷参数量、卷上下文长度、卷训练数据。但这篇论文用硬数据证明:在90%的实际应用场景中,你不需要405B的模型,3-12B就够了,而且更好。
这对产业的意义是革命性的:
- 创业公司:不再需要天价GPU集群,用消费级硬件就能部署可靠的智能体
- 大厂:可以把计算资源集中在真正需要大模型的场景(如开放域推理)
- 边缘设备:手机、IoT设备可以运行本地智能体,保护隐私、降低延迟
2. 最值得学习的工程思想
**"约束即可靠性"**(Constraints as Reliability)
传统观点认为约束会限制模型能力,但论文证明:在结构化任务中,约束反而是可靠性的保证。
类比一下:
- 让大模型自由生成JSON → 就像让一个博士生手写代码,容易出错
- 用CFG约束小模型生成 → 就像让程序员用IDE自动补全,反而更准
这个思想可以推广到很多场景:
- SQL生成:用SQL语法树约束,而非让模型"猜"
- API调用:用OpenAPI Schema约束,而非让模型"理解"文档
- 代码生成:用AST约束,而非让模型"背"语法
3. 还可以优化的方向
(1) 动态Schema学习
当前方法需要预先定义Schema,能否让系统从执行日志中自动学习和优化Schema?比如:
- 监控哪些参数组合总是失败
- 自动收紧Schema约束
- 生成更有针对性的验证规则
(2) 多SLM协作
论文主要讨论单个SLM + LLM兜底,能否设计SLM团队协作机制?比如:
- SLM-A专注提取,SLM-B专注验证,SLM-C专注修复
- 通过投票或辩论提高可靠性
- 成本仍比调用LLM低
(3) 主动学习路由
当前路由依赖预定义阈值(τu, τv),能否让路由器自适应学习?比如:
- 根据历史成功率动态调整阈值
- 识别"边界样本"主动标注
- 用强化学习优化成本-准确率权衡
(4) 跨模态SLM智能体
论文主要讨论文本SLM,但Llama-3.2-Vision等已支持多模态。未来方向:
- 图像提取 + 文本工具调用的端到端SLM
- 语音识别 + 结构化响应的语音助手SLM
- 传感器数据 + 工控指令的边缘SLM
4. 对实际应用的启示
不要一上来就上大模型! 正确的开发流程应该是:
- 先测小模型 → 80%场景可能3-7B就够了
- 加约束解码 → Schema/CFG约束能让小模型媲美大模型
- 加验证器 → 便宜的小模型验证器比人工检查高效
- 记录失败 → 失败样本是最好的微调数据
- 兜底LLM → 只在真正需要时调用大模型
这套流程的ROI(投资回报率)远高于"默认用GPT-4"。
5. 一个有趣的哲学问题
智能是"知道很多"还是"做得可靠"?
大模型的优势是"知道很多"(世界知识、长尾任务),但智能体的核心价值是"做得可靠"(准确调用工具、严格遵守格式)。
这篇论文其实在暗示:在产品化AI中,可靠性 > 通用性。
用户不在乎你的模型能背多少维基百科,用户在乎:
- 调用支付API不会出错
- 生成的SQL不会把数据库搞崩
- 提取的结构化数据100%可解析
从这个角度看,SLM为主的架构不是"妥协",而是正确的工程选择。
最后的思考
这篇核心观点是:用小型语言模型处理大部分常规任务,只在必要时调用大型模型,可以大幅降低成本、提升效率。这种思路引发了不少共鸣和延伸思考。
核心设计思路:效率与成本的平衡
论文提出,智能体的日常工作主要是调用工具和生成结构化输出,并不需要庞大的知识库。因此,完全可以让一个轻巧的小型模型作为默认工作主力,并为其配备一个“路由器”。当小型模型对任务不确定时,路由器才将任务“升级”交给大型模型处理。这种分工,据称能将常见工具类任务的成本降低10到30倍。
同时,系统要求所有输出都必须遵循严格的JSON格式规范,并由验证器进行检查。这种做法不仅提高了结果的准确性,还减少了因格式错误导致的重复尝试。
社区的反响与共识
许多人认为这个方向非常务实。有人称赞这是“正确的架构形态”,特别适合处理大量枯燥但重要的实际工作。这种设计能显著降低延迟和能耗,对于追求稳定性和效率的生产系统尤其具有吸引力。
大家普遍认为,这标志着一个重要的架构转变:AI领域的竞争优势,可能从“谁训练出最大的模型”转向“谁能设计出最智能的路由和验证层”。工程实现能力变得比算力预算更重要,这可能会改变整个行业的竞争格局。
深入探讨与不同视角
当然,也有一些更深层的讨论。有人提醒,“路由器本身也是一种开销”,其决策阈值需要精心设计和调优。另有观点指出,当前大多数智能体结构还比较浅层,无法胜任需要数十个步骤、持续数天的复杂任务。要解决真正复杂的问题,可能需要一场“架构革命”,例如将规划、执行与记忆存储分离开来。
关于模型规模,也出现了有趣的思考:小型和大型模型的界限究竟是什么?一个更根本的问题是,我们是否应该重新思考“大”和“小”的定义?也许未来会出现更动态的模型使用方式,比如让一个小型基础模型在需要时动态“获取”外部记忆或参数,临时扩展能力,而不是固化地增大模型体积。
这篇论文最大的贡献不是技术细节,而是思维方式的转变:
"不要问'我的模型够不够大',而要问'我的任务需要多大的模型'。"


