人工智能领域迎来一项重大突破。AIbase从社交媒体获悉,字节跳动于近日宣布开源其全新多模态生成模型Liquid,该模型以创新的统一编码方式和单一大语言模型(LLM)架构,实现了视觉理解与生成任务的无缝整合。这一发布不仅展示了字节在多模态AI上的技术雄心,也为全球开发者提供了强大的开源工具。以下是AIbase对Liquid模型的深度解析,探索其技术创新、核心发现及行业影响。

Liquid模型亮相:统一多模态生成新范式
Liquid是一个基于自回归生成的多模态模型,其核心创新在于将图像和文本编码到同一个离散token空间,并通过单一LLM同时处理视觉理解和生成任务。AIbase了解到,Liquid摒弃了传统多模态模型对外部预训练视觉嵌入(如CLIP)的依赖,采用VQVAE(向量量化变分自编码器)将图像转为离散编码,与文本token共享特征空间。这种设计显著简化了模型架构,提升了训练效率。
社交媒体反馈显示,开发者对Liquid的统一生成能力高度评价。无论是生成高质量图像、理解复杂视觉场景,还是处理长文本任务,Liquid均展现了卓越性能。AIbase认为,Liquid的开源发布(托管于GitHub和Hugging Face)将加速多模态AI的社区创新。
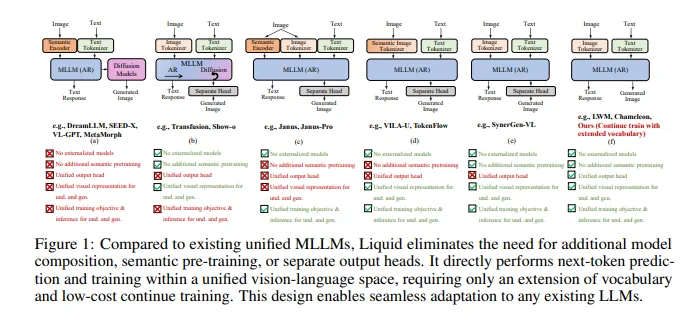
核心技术:单一LLM驱动多模态任务
Liquid的架构设计围绕以下关键技术点展开:
统一token空间:通过VQVAE将图像编码为离散token,与文本token在同一特征空间内训练,使模型能够无缝切换视觉和语言任务,无需额外的扩散模块。
单一LLM架构:基于现有LLM(如Qwen2.5、Gemma2)扩展词汇表,Liquid通过混合训练(60M多模态数据)同时优化视觉生成、视觉理解和语言能力,节省了100倍的训练成本。
多模态互促:Liquid发现,视觉生成和理解任务可在统一token空间内相互增强,消除了早期模型中的任务干扰问题。
AIbase分析,Liquid的自回归生成方式使其在生成高分辨率图像(FID5.47,MJHQ-30K)时优于SD v2.1和SD-XL,同时在GenAI-Bench测试中超越其他自回归多模态模型,展现了其对复杂提示的语义对齐能力。
突破性发现:规模化消除性能折衷
Liquid的核心研究发现颠覆了多模态训练的传统认知。论文指出,在小规模模型中,视觉和语言任务的联合训练可能导致语言能力下降。然而,Liquid首次揭示了多模态训练的规模法则:随着模型规模从0.5B增至32B,视觉和语言任务的性能折衷逐渐消失,甚至出现相互促进效应。
AIbase从社交媒体获悉,这一发现引发了开发者热议。例如,Liquid-7B在视觉生成(VQAscore优于Chameleon)和语言任务(媲美LLaMA2)中均表现出色,验证了规模化训练的潜力。AIbase认为,这一法则为未来超大规模多模态模型的设计提供了重要指导。
性能与开源生态:开发者的新利器
Liquid的性能表现令人瞩目。AIbase整理了其在关键基准测试中的成果:
视觉生成:在MJHQ-30K测试中,Liquid-7B的FID值为5.47,优于SD-XL和Chameleon,生成的图像在细节和语义一致性上表现出色。
视觉理解:在GenAI-Bench的复杂视觉-语言推理任务中,Liquid超越其他自回归模型,接近扩散模型的性能。
语言能力:得益于高质量混合训练,Liquid在文本任务中保持与主流LLM(如LLaMA2)相当的水平。
Liquid的开源策略进一步放大了其影响力。AIbase了解到,Liquid提供从0.5B到32B的多种模型规模,开发者只需基本的transformers库即可运行推理或评估,无需复杂环境依赖。社交媒体上,开发者已开始基于Liquid开发创意应用,如文本驱动的艺术生成和多模态问答系统。
行业影响:重塑多模态AI格局
Liquid的发布巩固了字节跳动在多模态AI领域的全球竞争力。AIbase观察到,相较于OpenAI的Chameleon(需从头训练)或谷歌的Gemini(依赖外部视觉编码器),Liquid以更低的训练成本和更高的灵活性提供了可比性能。其开源模式和低成本API(输入每百万token0.2美元,输出1.1美元)使其对中小企业和独立开发者极具吸引力。
对于行业,Liquid的统一生成范式为短视频创作、虚拟助手和教育内容生成等场景开辟了新可能。例如,营销团队可利用Liquid快速生成品牌风格的视频素材,教育机构可创建交互式多模态课程。AIbase预计,Liquid的开源生态将催生更多基于其架构的定制模型,推动多模态AI的普及。
挑战与展望:迈向更广应用
尽管Liquid表现出色,AIbase注意到社交媒体上用户提到的一些挑战。例如,小规模模型的性能折衷仍需优化,复杂场景的生成可能出现细节失真。AIbase建议开发者结合高质量数据集和精细提示词以提升输出效果。此外,模型的数据隐私和伦理使用需进一步明确,尤其在生成敏感内容时。
展望未来,字节跳动计划扩展Liquid的模态支持(如音频、视频),并探索分布式训练以进一步降低成本。AIbase预计,随着社区贡献的增加,Liquid或将在多模态代理和实时交互领域实现更大突破。
论文地址:https://arxiv.org/pdf/2412.04332


