编辑 | 萝卜皮
破译基因及其基因组背景之间的关系,是理解和设计生物系统的基础。机器学习在从大量蛋白质序列数据集中学习序列-结构-功能范式背后的潜在关系方面表现出潜力。
哈佛大学和麻省理工学院(MIT)的研究人员在数百万个宏基因组框架上训练基因组语言模型(gLM),从而分析基因之间潜在的功能和调控关系。
gLM 能够学习「上下文」化的蛋白质嵌入,捕获基因组上下文以及蛋白质序列本身,并编码具有生物学意义和功能相关的信息(例如酶功能、分类学)。
该研究以「Genomic language model predicts protein co-regulation and function」为题,于 2024 年 4 月 3 日发布在《Nature Communications》。

进化过程在蛋白质的序列、结构和功能之间建立了复杂的联系,这些联系对于解释基因组数据至关重要。虽然在基于神经网络(NN)的蛋白质结构预测方法和蛋白质语言模型(pLM)在无监督学习方面取得了进展,但这些模型通常忽略了蛋白质在基因组中的相互关系和背景。
特别是在细菌和古细菌中,水平基因转移(HGT)等进化事件对基因组的组织和多样性产生了显著影响。因此,需要一种能够捕捉基因、基因组背景和基因功能之间进化联系的方法。现有的基因组信息建模尝试主要关注基因功能的预测,而忽略了基因在多维空间中的连续性。
最近的研究如 GenSLM 之类的方法尝试通过预训练和微调来学习基因组规模信息,但目前还没有一种方法能够综合预训练——不同生物谱系、丰富连续的基因表示以及处理包含多个基因的长片段——三方面内容,来学习不同生物学谱系的基因组背景信息。
为了缩小基因组背景和基因序列结构功能之间的差距,哈佛大学和 MIT 的研究人员开发了一种基因组语言模型(gLM)来学习基因的背景表示。gLM 利用 pLM 嵌入作为输入,对基因产物的关系属性和结构信息进行编码。
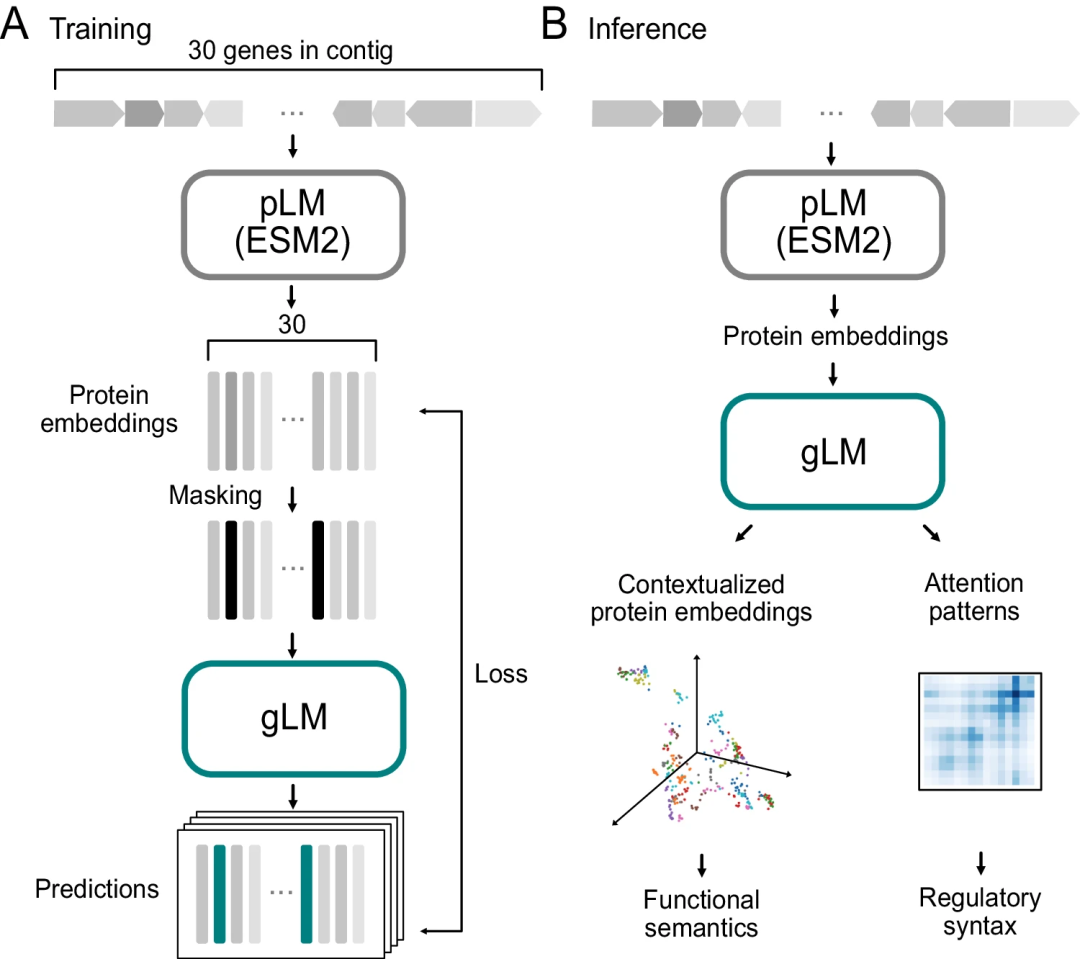
图示:gLM 训练和推理示意图。(来源:论文)
通过无监督训练,模型学习了语言的语义和语法,并在掩码语言建模中通过预测被遮蔽的单词来提高性能。特别是,该模型基于 19 层 Transformer 架构,并通过掩码语言建模目标使用数百万个未标记的宏基因组序列进行训练;模型学习根据基因组上下文预测掩码基因,允许在给定上下文中对最多四个不同的预测选项及其概率进行估计。
性能评估采用伪精度指标,并重点关注 E.coli K-12 基因组,通过从训练集中排除与其高度相似的子片段。验证结果显示,gLM 达到 71.9% 的伪精度和 59.2% 的绝对精度,表明其能够学习有意义的置信度指标,其中 75.8% 的高置信度预测正确。与使用相同任务和数据集训练的双向 LSTM 模型(伪精度为28%,绝对精度为15%)相比,gLM 的性能显著提高。
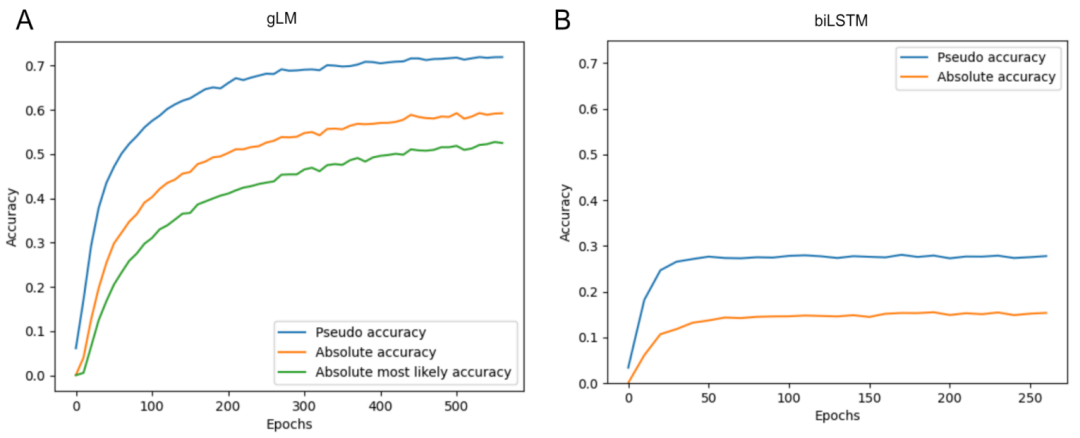
图示:gLM (A) 和 biLSTM 基线 (B) 的验证精度曲线。(来源:论文)
同时,研究人员强调了使用预训练蛋白质语言模型(pLM)表征的重要性,当将其替换为单热氨基酸表征时,模型性能降至随机预测水平(伪精度为3%,绝对精度为0.02%)。
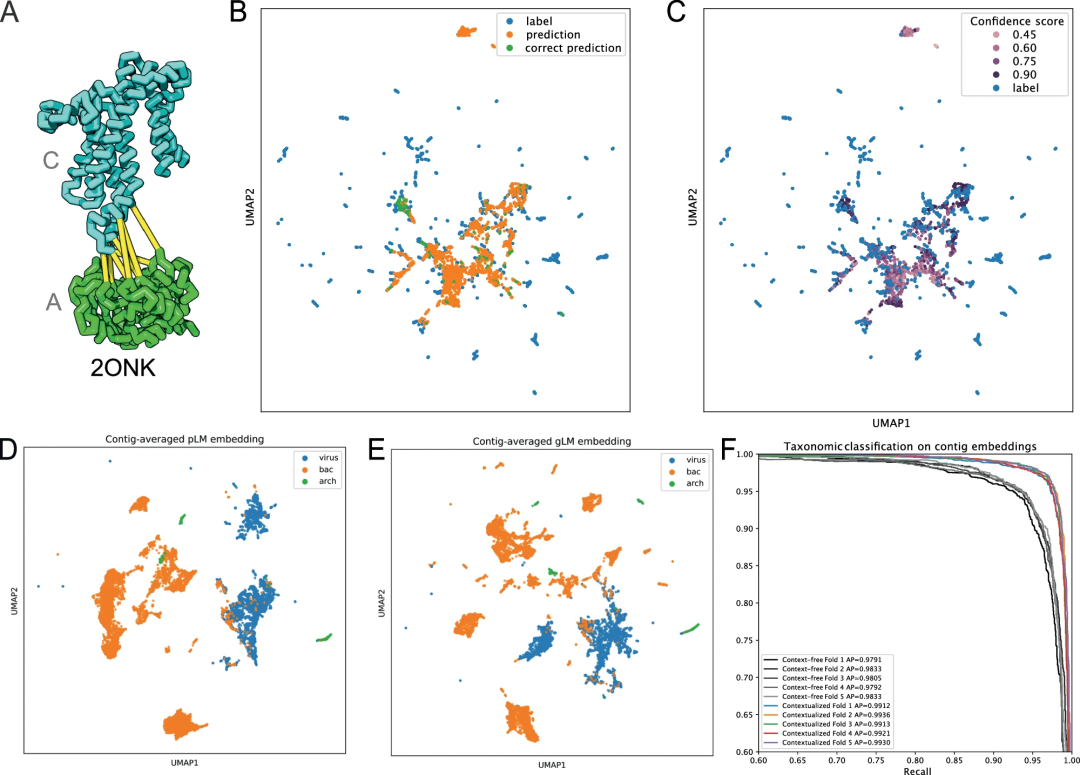
图示:gLM 预测蛋白质-蛋白质相互作用的同源性。(来源:论文)
总体而言,gLM 为研究基础生物学提供了一个有潜力的方式,研究人员还提出了未来的几个优化方向:
首先,Transformer 架构在高效扩展方面已被证明是成功的;在自然语言和蛋白质语言处理中,增加模型中的参数数量以及训练数据集的大小已被证明可以大大提高性能和通用性。该团队的模型由约 1B 个参数组成,与最先进的 pLM 相比,这些参数至少要小一个数量级。通过进一步的超参数调整和缩放,模型将有更好的性能。
其次,目前该模型使用 pLM 嵌入来表示输入中的蛋白质。这些嵌入是通过对整个蛋白质序列的氨基酸残基水平隐藏状态进行平均池生成的,因此残基特异性信息和同义突变效应可能被掩盖。该模型的未来迭代可以使用原始残基水平或密码子水平嵌入作为输入,以允许对蛋白质之间的残基到残基共同进化相互作用以及同义突变对基因功能的影响进行建模。
第三,重建掩蔽蛋白质嵌入的任务需要对可能嵌入的分布进行建模;该方法使用固定数量的预测来近似该分布。未来的工作可以通过使用生成方法(例如扩散或 GAN 模型)来改进这一点。这可以为未见过的数据集提供更好的预测准确性和更大的通用性。
第四,添加非蛋白质模式(例如非编码调控元件)作为 gLM 的输入也可以极大地改善 gLM 对生物序列数据的表示,并且可以学习以其他模式为条件的蛋白质功能和调控。
第五,该模型主要是在细菌、古菌和病毒基因组上进行训练,因此,该方法如何适用于真核基因组,特别是那些具有广泛基因间区域的真核基因组,仍有待进一步探索。
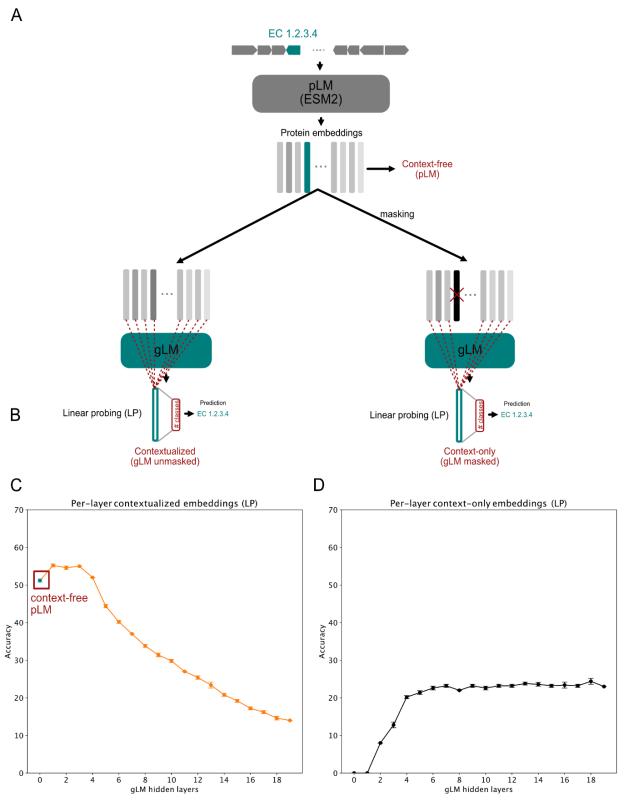
图示:对上下文无关、仅上下文和上下文化基因嵌入的线性探测。(来源:论文)
研究人员也指出了应用 gLM 推进生物学研究的未来方向:
1、基于特征的迁移学习,用于预测蛋白质功能(例如基因本体论[GO]术语),特别是那些具有有限序列和结构同源性的蛋白质功能。
2、针对蛋白质-蛋白质-相互作用组预测任务微调 gLM。
3、使用 gLM 特征对基因组上下文进行编码,作为改进和上下文化的蛋白质结构预测的附加输入。
总之,基因组语言模型是一个强大的工具,可以从完整的宏基因组序列中公正地浓缩重要的生物信息。再加上长读长测序的进步,研究人员认为输入数据的质量、数量和多样性将大幅提高。基因组语言建模提供了一条弥合原子结构和有机体功能之间差距的途径,从而使科学家更接近生物系统建模,并最终精确地操纵生物学(例如基因组编辑、合成生物学)。
论文链接:https://www.nature.com/articles/s41467-024-46947-9