科技媒体 marktechpost 昨日(4 月 23 日)发布博文,报道称英伟达为应对图像和视频中特定区域的详细描述难题,最新推出了 Describe Anything 3B(DAM-3B)AI 模型。
视觉-语言模型(VLMs)在生成整体图像描述时表现出色,但对特定区域的细致描述往往力不从心,尤其在视频中需考虑时间动态,挑战更大。
英伟达推出的 Describe Anything 3B(DAM-3B)直面这一难题,支持用户通过点、边界框、涂鸦或掩码指定目标区域,生成精准且贴合上下文的描述文本。DAM-3B 和 DAM-3B-Video 分别适用于静态图像和动态视频,模型已在 Hugging Face 平台公开。
独特架构与高效设计
DAM-3B 的核心创新在于“焦点提示”和“局部视觉骨干网络”。
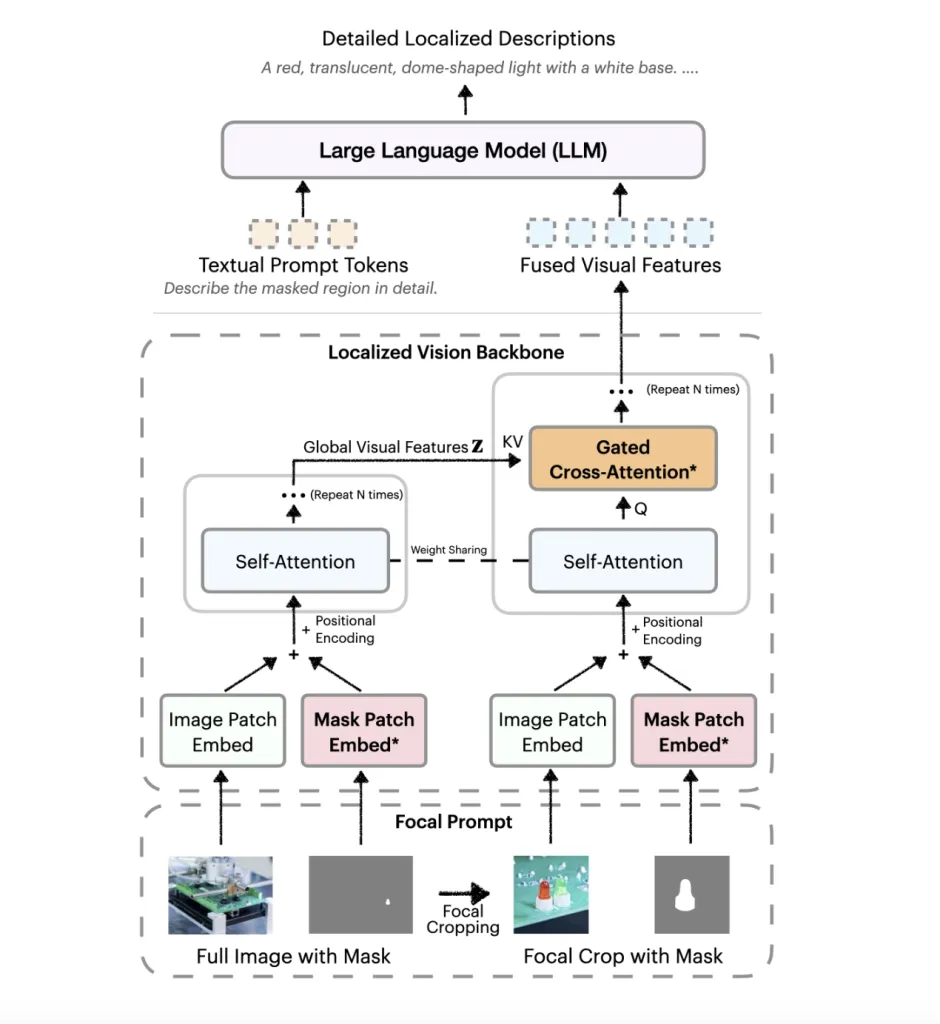
焦点提示技术融合了全图信息与目标区域的高分辨率裁剪,确保细节不失真,同时保留整体背景。
局部视觉骨干网络则通过嵌入图像和掩码输入,运用门控交叉注意力机制,将全局与局部特征巧妙融合,再传输至大语言模型生成描述。
DAM-3B-Video 进一步扩展至视频领域,通过逐帧编码区域掩码并整合时间信息,即便面对遮挡或运动也能生成准确描述。
数据与评估双管齐下
为解决训练数据匮乏问题,NVIDIA 开发了 DLC-SDP 半监督数据生成策略,利用分割数据集和未标注的网络图像,构建了包含 150 万局部描述样本的训练语料库。

通过自训练方法优化描述质量,确保输出文本的高精准度,团队同时推出 DLC-Bench 评估基准,以属性级正确性而非僵硬的参考文本对比衡量描述质量。
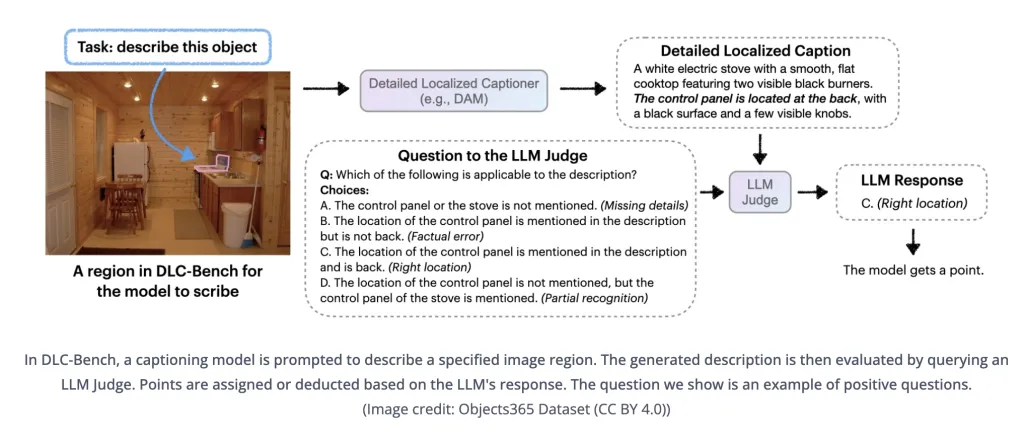
DAM-3B 在包括 LVIS、Flickr30k Entities 等七项基准测试中领先,平均准确率达 67.3%,超越 GPT-4o 和 VideoRefer 等模型。
DAM-3B 不仅填补了局部描述领域的技术空白,其上下文感知架构和高质量数据策略还为无障碍工具、机器人技术及视频内容分析等领域开辟了新可能。
AI在线附上参考地址
Describe Anything: Detailed Localized Image and Video Captioning
Hugging Face
项目页面


