
近期,Qwen3模型的一个重大转变,让整个行业都在重新思考一个根本问题:推理大模型到底应该什么时候思考,什么时候直接给答案?
这已不再是技术问题,也是关乎AI产品体验的核心议题...
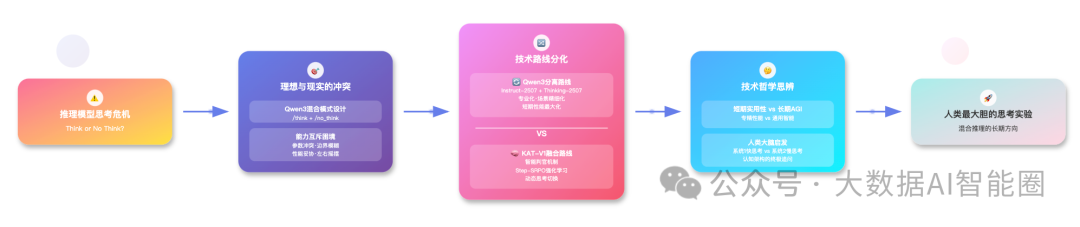
Qwen3的"分家"背后:理想很丰满,现实很骨感
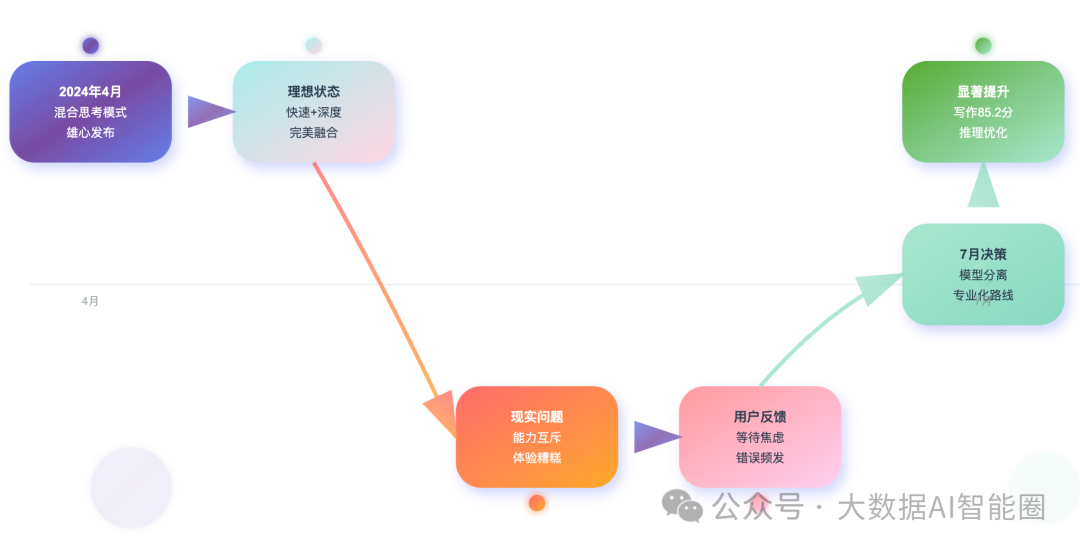
回到今年4月,Qwen3刚发布时,阿里团队雄心勃勃地推出了"混合思考模式"。
听起来很美好:一个模型既能快速响应简单问题,又能深度思考复杂任务。
用户只需要通过/think和/no_think指令,就能让模型在"学霸模式"和"闪答模式"之间自由切换。
当时我们都觉得这是个绝妙的设计。毕竟,谁不想要一个既快又准的AI助手呢?但是,技术的理想往往会被现实狠狠打脸。
仅仅3个月后,Qwen3团队做了一个让人意外的决定:把思考模型和非思考模型彻底分开,分别发布了Qwen3-235B-A22B-Instruct-2507和Qwen3-235B-A22B-Thinking-2507。
这个"分家"动作背后,藏着什么样的技术无奈?
问题的核心在于"能力互斥"。好比一个人很难同时做到既是马拉松冠军又是短跑冠军一样,让同一个模型既要快速反应又要深度思考,本身就是个矛盾的需求。
在SFT(监督微调)阶段,思考数据和非思考数据的比例调配成了一个玄学问题。数据边界模糊,导致模型在两种能力上都被妥协了。
更要命的是用户体验。我们在GitHub上看到不少开发者吐槽:混合模式下,简单的"今天天气怎么样"也要等模型思考半天;而复杂的数学证明题,模型又经常选择"闪答"模式,结果错得离谱。这种不可预测性,让产品经理们头疼不已。
分离后的效果立竿见影。
非思考版本在写作任务上达到了85.2分,思考版本在逻辑推理、数学等任务上也有显著提升。这个结果告诉我们一个残酷的真相:在当前技术水平下,专业化比通用化更靠谱。
KAT-V1的"智能判官":让AI自己决定要不要动脑子
虽然Qwen3选择了分离路线,但技术圈从来不缺乏"不信邪"的团队。
快手的KAT-V1项目就是个典型例子,他们要解决的核心问题是:能不能让模型自己判断什么时候该思考,什么时候该直接答?
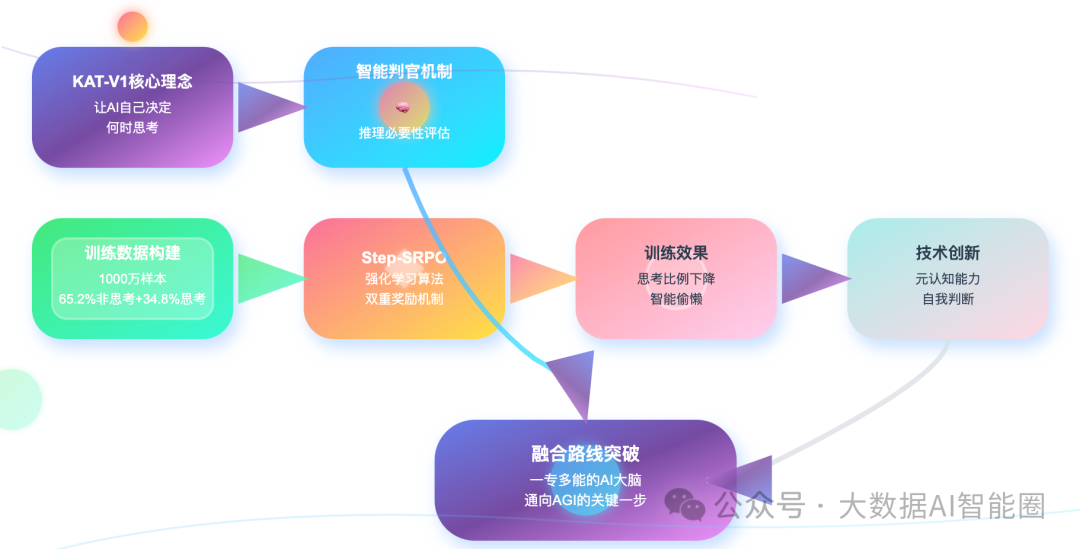
KAT-V1的方案听起来很有意思。他们给模型加了一个"智能判官"功能,让模型在回答问题前先进行"推理必要性评估"。直接给AI装了个大脑开关,遇到"1+1等于几"这种问题,直接跳过思考环节;碰到"证明哥德巴赫猜想"这种难题,立马切换到深度思考模式。
技术实现上,KAT-V1用了一套相当精巧的训练策略。
他们构建了1000万个样本的训练数据,其中65.2%是非思考数据,34.8%是思考数据。更关键的是,他们给每个样本都加了"判断标签",告诉模型这道题到底需不需要深度思考。
但光有数据还不够,KAT-V1的核心创新在于Step-SRPO强化学习算法。
这个算法设计了双重奖励机制:判断奖励负责评估模型是否正确选择了思考模式,答案奖励负责评估最终回答的质量。通过这种方式,模型逐渐学会了什么时候该"动脑子",什么时候该"凭直觉"。
有个有趣的现象:在训练过程中,模型开启思考模式的比例不断下降。
这说明什么?AI正在学会"偷懒"——它发现很多问题其实不需要复杂推理就能解决。这种"智能偷懒"恰恰体现了效率优化的本质。
思考的边界:技术路线背后的哲学思辨
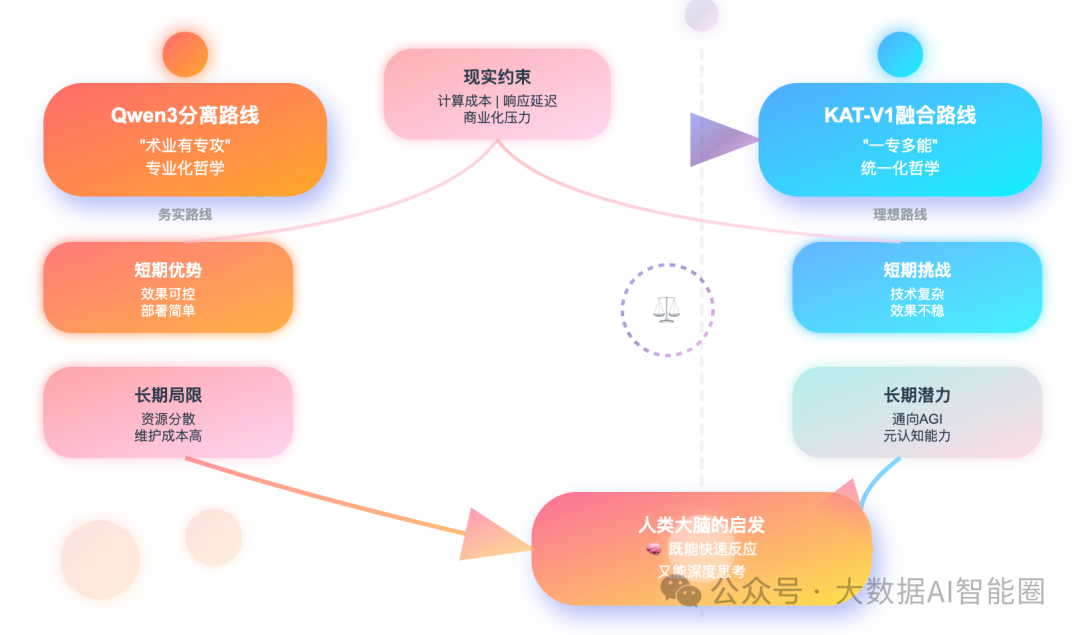
Qwen3的分离路线和KAT-V1的融合路线,代表了两种不同的技术哲学。
前者认为"术业有专攻",后者坚持"一专多能"。哪种路线更有前景?
从短期来看,分离路线确实更实用。就像我们在实际业务中,往往会针对不同场景部署不同的模型:客服场景用快速响应模型,研发场景用深度推理模型。这种做法简单粗暴,但效果可控。
但从长期来看,融合路线可能更符合AI发展的终极目标。毕竟,人类大脑就是一个既能快速反应又能深度思考的系统。我们在日常对话中能够瞬间切换思维模式,这种能力如果能在AI中实现,将是一个巨大的突破。
KAT-V1的尝试虽然还不够完美,但它指出了一个重要方向:让AI具备"元认知"能力,能够对自己的思考过程进行思考。
这种递归式的智能,可能是通向AGI的关键一步。
当然,现实总是比理想复杂。在实际应用中,我们还面临着计算成本、响应延迟、用户体验等多重约束。
一个"完美"的思考切换机制,如果导致成本翻倍或延迟增加,对商业化产品来说就是灾难。
技术的演进从来不是线性的。今天的分离可能是为了明天更好的融合,今天的妥协可能是为了明天的突破。
无论是Qwen3的务实选择,还是KAT-V1的理想主义尝试,都在为这个行业积累宝贵的经验和数据。
结语
在这个AI快速发展的时代,我们既要保持对技术前沿的敏感,也要对现实约束有清醒的认识。
推理大模型的思考机制还在不断演进,而我们作为这个历史进程的参与者和见证者,最重要的是保持开放的心态和批判的思维。
让AI学会思考,本身就是人类最大胆的思考实验?


