编辑丨%
在语言领域,GPT 这样的「大模型」只需一次训练,就处理翻译、写作、问答等不同任务。那在物理世界,能不能也有一台「通用物理引擎」,一次训练后就能推演流体、热传递、甚至冲击波?
这个难题困扰着物理学家。目前的物理模拟往往是「专用工具箱」:求流体用一套方法,做热对流要换另一套。每个体系都要重建模型、调参和算力,成本高、迁移性差。实验的流畅性往往饱受摧残。
所以,弗吉尼亚大学(University of Virginia)与亚琛工业大学(RWTH Aachen University)的团队提出了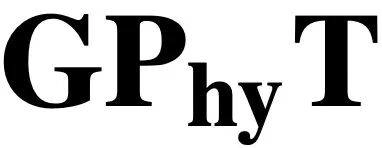 (General Physics Transformer)。该 Transformer 经过 1.8 TB 的多物理体系模拟数据训练,覆盖流体–固体相互作用、冲击波、热对流、多相流等领域。不是针对单一系统,而是作为「物理领域的大模型」——一次训练,广泛适用。
(General Physics Transformer)。该 Transformer 经过 1.8 TB 的多物理体系模拟数据训练,覆盖流体–固体相互作用、冲击波、热对流、多相流等领域。不是针对单一系统,而是作为「物理领域的大模型」——一次训练,广泛适用。
该研究以「Towards a Physics Foundation Model」为题,其预印本发布在 arxiv。

论文链接:https://arxiv.org/abs/2509.13805
通用物理 Transformer
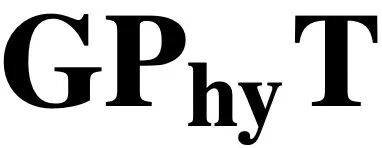 基于 Transformer,加入了时空注意力机制,并结合数值积分器。模型先学习状态的时间导数,再用数值方法外推出未来状态。可以将
基于 Transformer,加入了时空注意力机制,并结合数值积分器。模型先学习状态的时间导数,再用数值方法外推出未来状态。可以将  视为神经网络和物理引擎的混合体。
视为神经网络和物理引擎的混合体。
它接收一段发生过程的历史(例如几个模拟帧),从中找出变化的规则,然后应用一个简单的更新步骤来预测接下来会发生什么。就像教一个 Transformer 通过基本的微积分提示来玩物理帧预测游戏。
研究团队表示,该通用模型主要为解决三个关键问题:
1.一个单一的大型 Transformer,能否在没有任何显式的物理描述特征的情况下,有效地模拟广泛的异质物理系统(例如不可压缩流动、冲击波、对流);
2.这个基础模型能否仅通过从输入中推断动力学,实现零样本泛化到新的、未见的物理条件(例如新的边界条件、全新的物理学知识);
3. 能否在扩展的自回归滚动预测过程中保持物理一致性和稳定性。
能否在扩展的自回归滚动预测过程中保持物理一致性和稳定性。
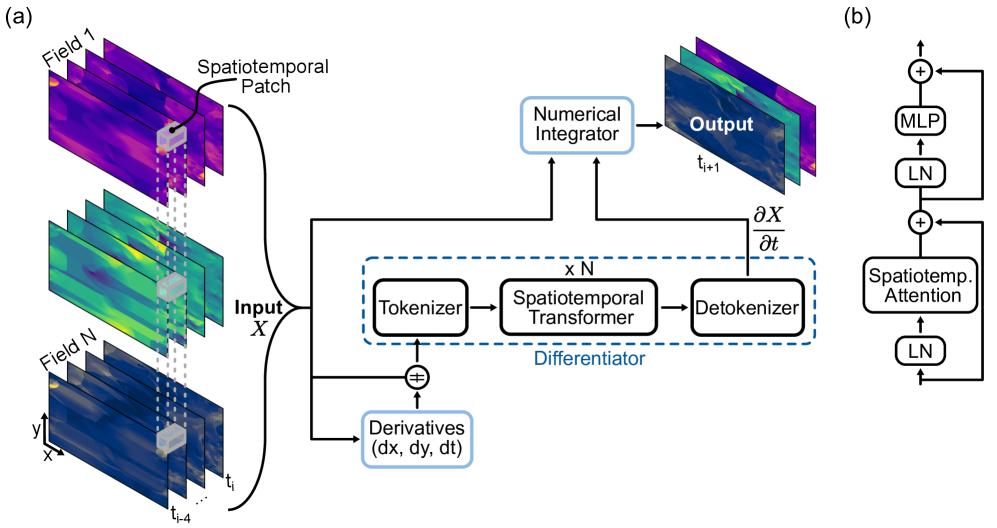
图 1: 的一般架构。
的一般架构。
为了达到训练目的,研究团队并未局限于一种流体或系统,而是汇集了涵盖许多不同场景的 1.8 TB 模拟数据:平静流动、湍流流动、热对流等。除此之外变量 Δt 子采样和归一化数据集都鼓励跨尺度的上下文推理。
多场景适用
在所有测试集的单步预测中, 在相似参数数量下,与 UNet 相比,中值均方误差(MSE)降低了约 5 倍,与 FNO 相比降低了约 29 倍。
在相似参数数量下,与 UNet 相比,中值均方误差(MSE)降低了约 5 倍,与 FNO 相比降低了约 29 倍。
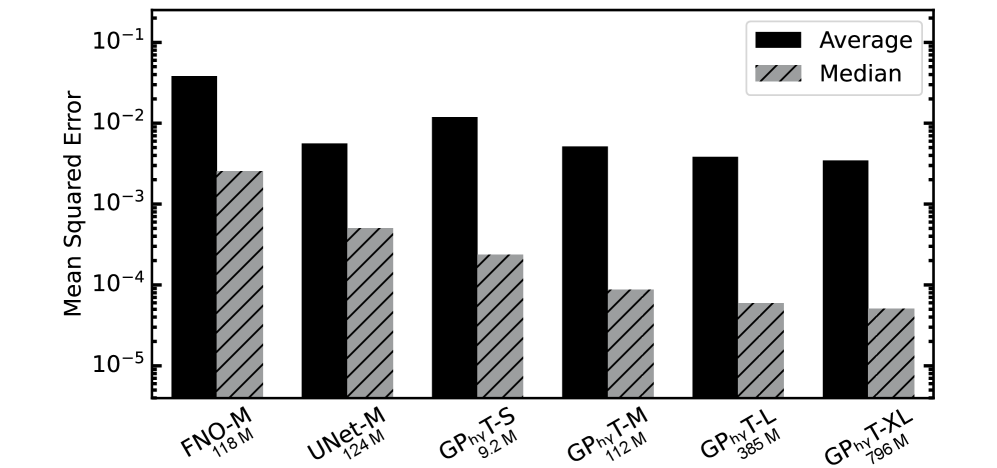
图 2:所有测试集中每个模型的平均和中位数均方误差(MSE)。
更令人兴奋的是,该模型实现了通过上下文学习实现零样本泛化,对完全未见的物理系统进行预测。这意味着你可以给它一个它从未训练过的全新情况,比如它从未见过的边界条件,甚至是超音速流动,它仍然能够产生物理上合理的预测结果。
经测试,该模型在 50 步自回归预测中仍能保持物理一致性,避免了快速发散。扩展到分布外系统进一步揭示了模型的泛化机制。随着预测的累积,细节逐渐消失,但大规模行为(如全局流动结构)的可靠性比预期要持久得多。
迈向物理 GPT 的第一步
团队已经证明,单个基于 Transformer 的模型可以有效地学习和预测各种物理系统的动力学,而无需显式的物理特定特征,这标志着向真正的物理基础模型迈出了重要一步。这项工作展示了物理基础模型的可能性:训练一次,就能在多个场景下运行,节省大量算力和开发成本。
当然,当前版本仍有局限:只限二维数据,涵盖的领域主要是流体和热传递,长时预测精度也比不上高保真数值方法。
但作为雏形,它释放了一个重要信号:物理模拟也许正在迎来「GPT时刻」。未来,一个真正的通用物理大模型,可能成为科研与工程的公共引擎。
相关链接:https://x.com/omarsar0/status/1968681177189077366