强化学习(RL)+ 真实搜索引擎,可以有效提升大模型检索-推理能力。
但问题来了:
一方面,搜索引擎返回的文档质量难以预测,给训练过程带来了噪音和不稳定性。
另一方面,RL 训练需要频繁部署,会产生大量 API 开销,严重限制可扩展性。
现在,来自阿里通义实验室的解决方案公开了:开源 ZeroSearch,提供了一种无需与真实搜索引擎交互的强化学习框架。
实验表明,ZeroSearch 仅需 3B 参数的 LLM 作为检索模块,即可有效提升搜索能力,节省了高昂 API 成本。

ZeroSearch 让 LLM“自给自足”实现搜索进化
研究团队用模拟搜索环境 + 渐进式抗噪训练,让 LLM 不再依赖昂贵搜索引擎 API。
轻量微调:把 LLM 变成“搜索引擎模拟器”
用少量标注数据微调 LLM,使其能按指令生成两种文档 —— 有用结果和噪声干扰。

通过收集与真实搜索引擎交互的数据,ZeroSearch 对 LLM 进行轻量级监督微调。
在这个过程中,模型学会生成与真实搜索引擎风格相似的文档,同时能够根据提示词生成相关或噪声文档。
这种能力使得模型在训练过程中能够动态调整文档质量,从而更好地模拟真实检索场景。
课程化抗噪训练:像打游戏升级一样练模型
训练初期返回高质文档,后期逐渐混入噪声(噪声比例按指数曲线上升)。
ZeroSearch 引入了课程式学习机制,逐步降低生成文档的质量,使模型从简单的检索场景逐步过渡到更具挑战性的任务。
这种策略不仅提升了模型的推理能力,还显著增强了训练的稳定性和效果。
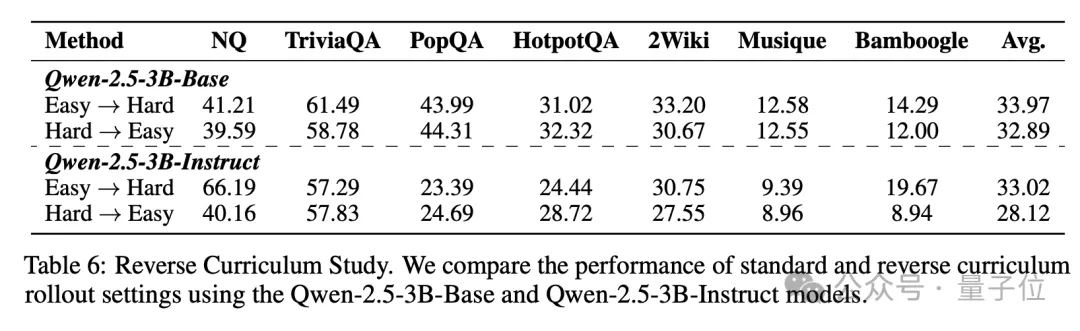
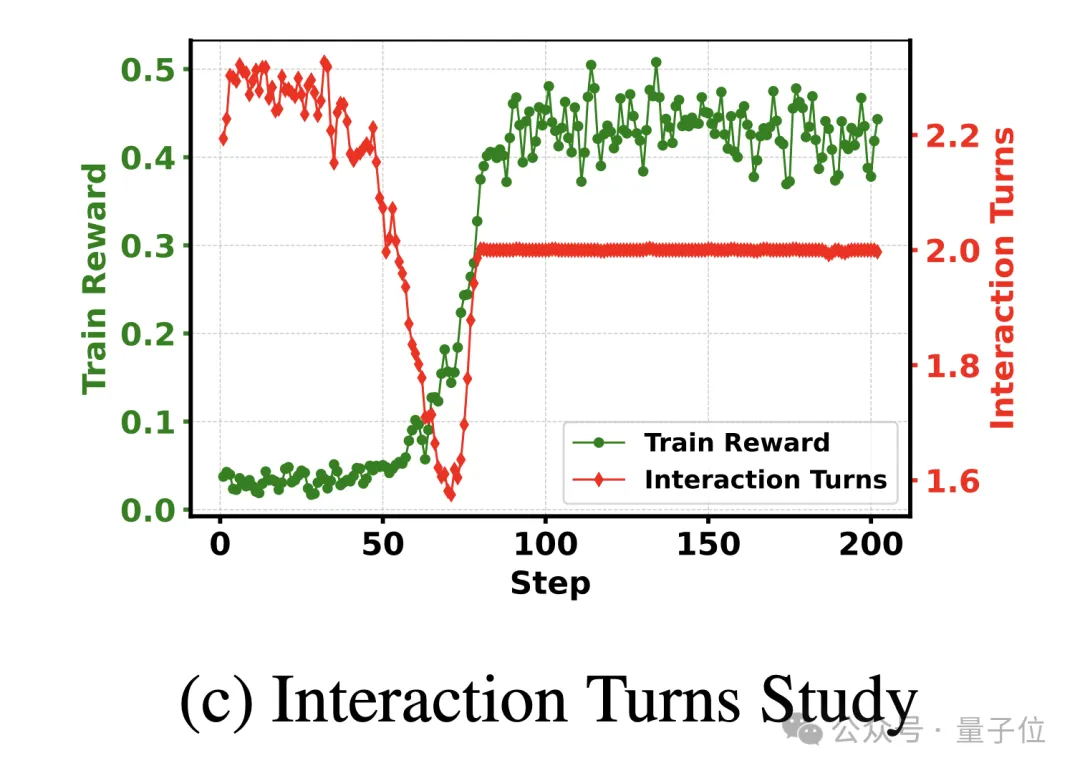
随着训练的进行,模型逐渐适应更复杂的检索任务,最终能够在高质量和低质量文档中找到平衡。
强化学习闭环:自产自销的搜索生态
ZeroSearch 通过模拟搜索引擎,完全消除了与真实搜索引擎交互的 API 费用,使得大规模强化学习训练变得更加经济可行。
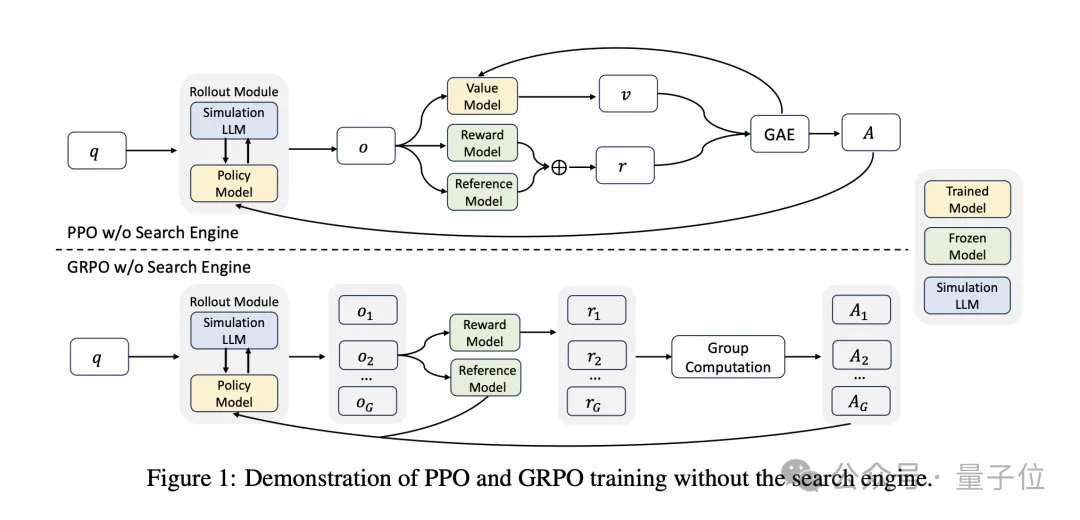
并且,ZeroSearch 兼容多种强化学习算法,包括 PPO(Proximal Policy Optimization)和 GRPO(Group Relative Policy Optimization)。
这些算法为模型提供了不同的优化策略,使得 ZeroSearch 能够在不同的模型和任务中表现出色。
实验表明,GRPO 在训练稳定性方面表现更好,而 PPO 则在某些任务中提供了更高的灵活性。
实验结果及结论
ZeroSearch 的零 API 成本优势不仅体现在经济上,还体现在训练的灵活性和可扩展性上。
ZeroSearch vs. 现有方法
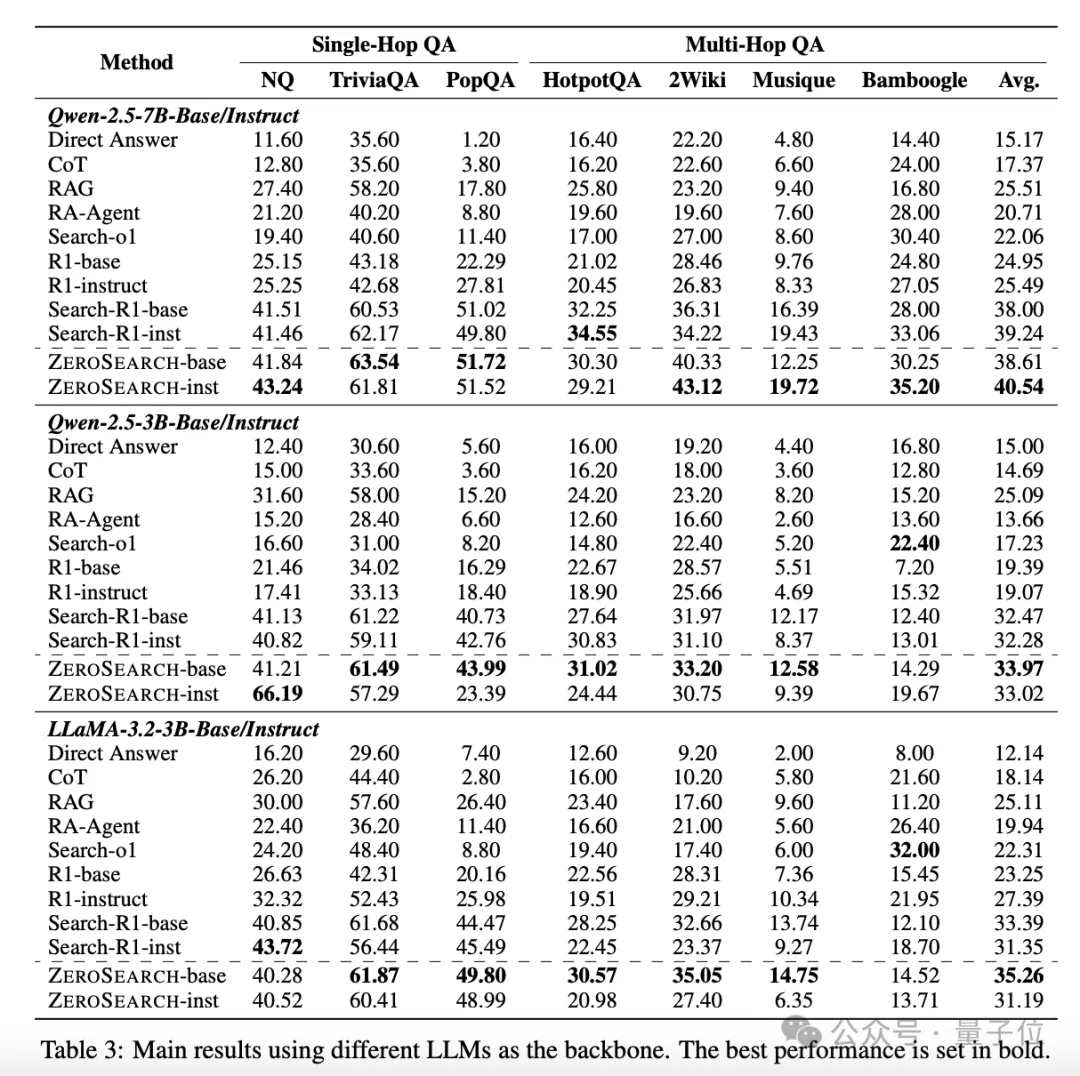
在图中,我们可以清晰地看到 ZeroSearch 在多个问答数据集上的表现。
无论是单跳(Single-Hop)还是多跳(Multi-Hop)问答任务,ZeroSearch 都显著优于现有的基线方法,包括直接提示、RAG 和 Search-R1 等。
这表明 ZeroSearch 不仅在简单任务中表现出色,还能在复杂的多跳问答任务中发挥强大的检索能力。
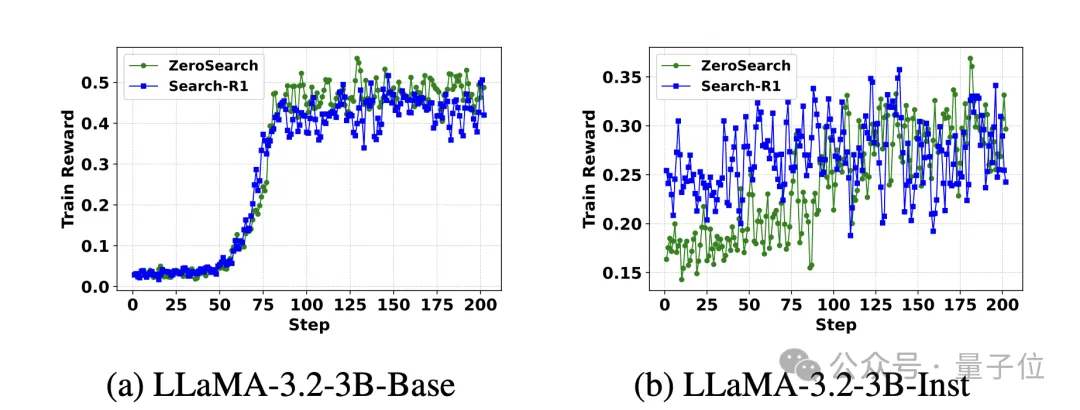
上图展示了 ZeroSearch 和 Search-R1(使用真实搜索引擎)在 LLaMA-3.2-3B 模型上的奖励曲线对比。
ZeroSearch 的学习曲线更加平滑且最终性能优于 Search-R1,表明其在训练过程中的稳定性和优越性。
不同模型规模的性能
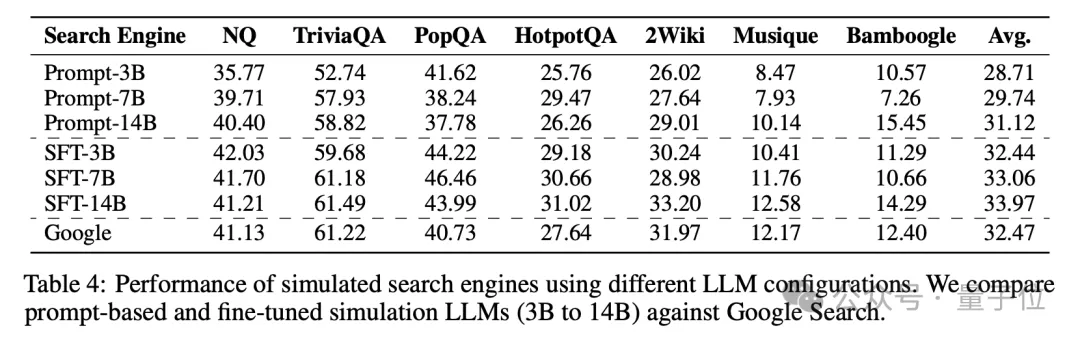
可以看到使用 7B 参数的检索模块就能达到与谷歌搜索相当的性能,而 14B 参数的检索模块甚至能够超越谷歌搜索。
这表明 ZeroSearch 不仅适用于小型模型,还能在大型模型中发挥更大的潜力,为 LLM 的检索能力提升提供了广阔的空间。
强化学习算法的兼容性
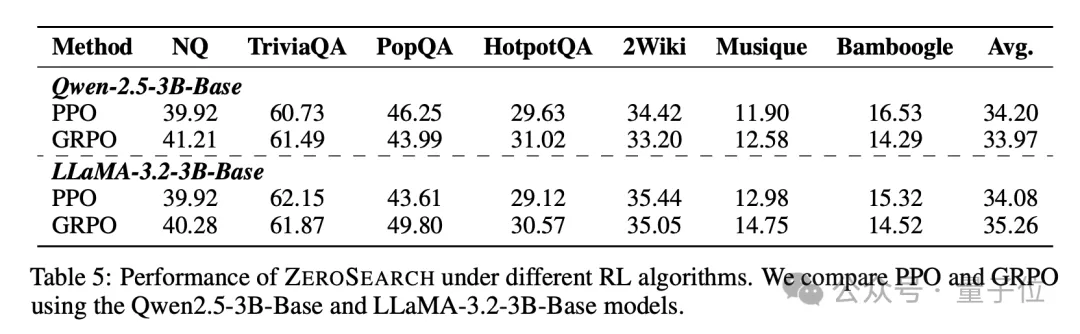
比较了在 Qwen-2.5-3B 和 LLaMA-3.2-3B 模型上,使用 PPO 和 GRPO 算法的 ZeroSearch 性能,可以看到 ZeroSearch 与 PPO 和 GRPO 两种强化学习算法的兼容性。
实验结果表明,GRPO 在训练稳定性方面表现更好,而 PPO 则在某些任务中提供了更高的灵活性。
这表明 ZeroSearch 能够适应不同的强化学习算法,为研究人员提供了更多的选择。
通过模拟搜索引擎,ZeroSearch 完全消除了 API 成本,同时通过课程式学习策略逐步提升模型的推理能力。
论文第一作者孙浩目前是北京大学智能学院四年级博士研究生,研究方向聚焦于检索增强的大语言模型与智能体,师从张岩教授。
论文链接:
https://arxiv.org/abs/2505.04588
项目主页:
https://alibaba-nlp.github.io/ ZeroSearch
本文来自微信公众号:量子位(ID:QbitAI),作者:闻乐