
大家好,我是肆〇柒。今天,我想和大家聊一下,我看到关于自适应思考的另外一片论文,它介绍了Thinkless 框架,并且还有开源仓库。今天我们要了解的 Thinkless 这个框架,由新加坡国立大学的研究人员提出,它能够巧妙地解决当前推理语言模型(LLM)在处理简单问题时过度推理、浪费资源的难题。
以往,推理语言模型如同一位不知疲倦的学者,无论面对的是复杂深奥的数学定理,还是简单如孩童般的算术问题,它都会一丝不苟地展开 lengthy 的推理过程。然而,这种“过度勤奋”却带来了计算资源的巨大浪费。每一次冗余的推理都是对效率的无情吞噬,让本可以迅速给出的简洁答案,也变得拖沓而冗长。
这种现象引发了 Thinkless 研究人员的思考:如何让 LLM 拥有自主决策推理深度的智慧,在效率与性能之间找到精妙的平衡?新加坡国立大学的研究人员给出了他们的答案——Thinkless 框架。这一思路不仅让模型学会了“聪明偷懒”,更在效率与性能之间找到了平衡。
研究背景与动机:推理模型的“效率困局”
推理语言模型通过链式思考,一步步攻克难题,展现出惊人的能力。然而,这种“万能钥匙”式的推理方式却隐藏着效率危机。当我们回顾模型的推理过程时,会发现一种“一刀切”的思维惯性:无论问题难易,都启动复杂推理机制。
这种惯性带来的后果是显而易见的。在简单的加减法问题上,模型依然会生成冗长的推理链条,每一步都详尽到近乎繁琐,导致 token 生成数量激增。这不仅让内存占用如同吹气球般膨胀,更让计算成本节节攀升,仿佛在用大象的力气去搬动蚂蚁的食物。
Thinkless 框架的提出,正是为了打破这一困局。它可以赋予 LLM 一种“情境感知”的能力,使其能够像经验丰富的工匠一样,根据手头任务的复杂度和自身技艺的精湛程度,灵活地选择最合适的工具。
Thinkless框架:让LLM“聪明偷懒”的核心
双控制Token:简洁与深度的抉择之门
Thinkless 框架的核心创新之一在于引入了两个 special Token:<short> 和 <think>。这两个Token就好比是模型手中的两把钥匙,分别对应着简洁回答和详细推理的大门。
在实际操作中,当模型面对一个输入查询时,它首先会快速评估问题的复杂程度。如果问题像是简单的加减法运算,模型会毫不犹豫地选择 <short> Token,直接给出简洁明了的答案,无需多余赘述。而当问题变成复杂的多元方程求解时,<think> Token会被激活,模型随即开启深度推理模式,步步为营,直至找到问题的解决之道。
DeGRPO算法:精准调控的“智慧大脑”
Decoupled Group Relative Policy Optimization(DeGRPO)算法是 Thinkless 框架的智慧核心,它巧妙地将混合推理目标分解为两大关键任务:模式选择和答案准确性提高。
在传统的强化学习方法中,模型往往陷入一种“失衡”的困境。长链推理由于 token 数量多,会主导学习信号,使得短链推理难以获得足够的优化权重,最终导致模型在训练初期就迅速偏向长链推理,失去了多样性。而 DeGRPO 算法通过独立地对控制Token和响应Token进行归一化处理,引入一个长度无关的权重系数 α,确保了两种推理模式在优化过程中的平等对话。
数学公式层面,算法首先定义了一个简单的奖励函数 r(a, y∗, c),对不同推理模式下的正确和错误答案赋予不同的奖励值。例如,对于短链正确答案给予最高奖励 1.0,而长链正确答案则给予略低的奖励 1.0−γ,以此体现对短链答案的偏好。
在优化目标方面,DeGRPO 将原始的 GRPO 框架进行扩展。对于每一个查询样本,算法从当前策略中抽取一批样本,计算每个 token 级别的优势函数。通过巧妙地分离控制Token和响应Token的贡献,使得模式选择和答案准确性提高这两个目标能够独立地贡献于整体优化过程,从而避免了传统方法中由于序列长度差异导致的梯度不平衡问题。
下图展示了 Thinkless 框架如何通过两个 special Token <think> 和 <short>,结合 DeGRPO 算法,实现对推理模式的动态选择。这一过程不仅提高了模型的效率,还保证了答案的准确性。
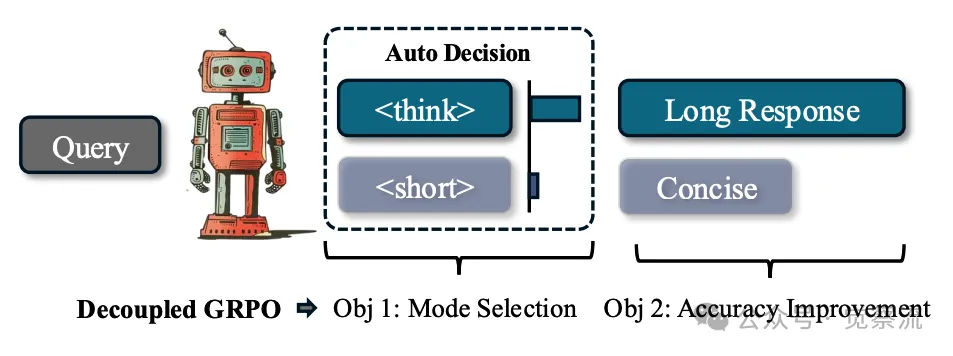
Thinkless 学习了一种混合型 LLM,能够自适应地在思考推理模式和非思考推理模式之间进行选择,这一选择过程由两个 special tokens:<think> 和 <short> 来引导。方法的核心是 Decoupled Group Relative Policy Optimization,它将模式选择在控制 token 上的分解与在响应 token 上的准确性提升进行了平衡
实验设计与结果:Thinkless的“实力验证之旅”
实验环境搭建
在实验设置方面,研究人员精心选择了 DeepSeek-R1-Distill-Qwen-1.5B 作为基础模型,搭配 DeepScaleR 数据集进行强化学习训练。训练硬件配置为 4 块 H100 GPU,最大上下文长度在预训练热身阶段设为 16K,强化学习阶段扩展至 24K。优化器选用 AdamW,学习率设定为 1×10−6,批次大小为 128,每个查询采样 8 个响应,确保了实验的严谨性和可重复性。
对比实验的“高光时刻”
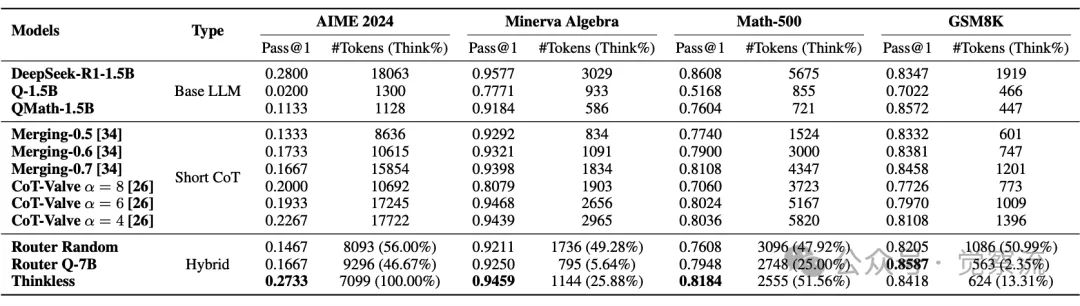
在与基线模型的对比中,Thinkless 显示出了压倒性的优势。以 Minerva Algebra 数据集为例,基线模型 DeepSeek-R1-1.5B 在追求高准确率的同时,token 使用量高达 18063,而 Thinkless 仅使用了 7099 个 token,token 使用量减少了近 60%,准确率却依然保持在 94.59%,几乎与基线模型持平。
与其他技术的对比同样令人瞩目。模型融合方法虽然能在一定程度上减少 token 使用量,但在不同数据集上的表现波动较大,难以兼顾效率与性能。CoT-Valve 技术虽然提供了可调节的推理长度,但需要针对每个数据集手动调整参数,缺乏自适应性。而基于路由器的方法则受限于独立模型对目标模型能力的有限理解,无法做出精准的推理模式决策。
关键结论的“硬核数据”
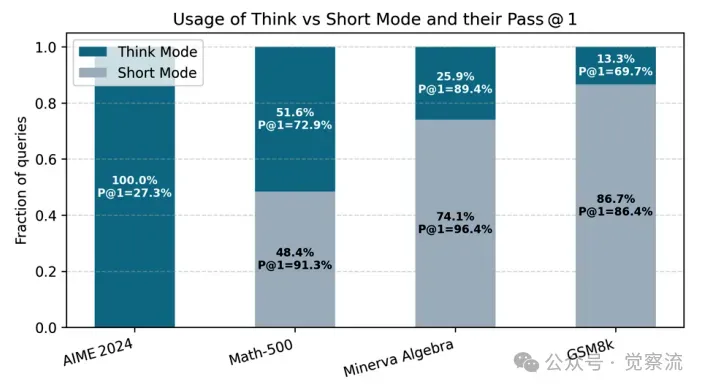
在多个基准测试中,Thinkless 的表现堪称惊艳。在 Minerva Algebra 数据集上,长链推理使用比例仅为 25.88%,token 使用量大幅减少,准确率却高达 94.59%;在 AIME 2024 数据集中,面对复杂问题,Thinkless 依然能保持 27.33% 的准确率,且推理模式使用比例高达 100%,展现了强大的适应能力;在 GSM8K 数据集上,长链推理使用比例仅为 13.31%,准确率却达到了 84.18%。
为了更直观地呈现 Thinkless 的优势,我们绘制了如下对比柱状图和折线图。这些图表展示了 Thinkless 在减少长链推理使用频率和保持高准确率方面的显著优势。
混合推理的实证结果。对于混合算法,研究人员还报告了在评估过程中以思考模式执行的查询所占的比例。
训练动态与策略分析:深度剖析模型的“学习成长之路”
训练过程的“可视化奇观”
在强化学习训练过程中,研究人员发现了一个有趣的现象:传统 GRPO 方法常常会遭遇模式崩溃问题。模型在训练初期会迅速偏向长链推理,导致短链推理几乎消失,仿佛模型被一种“长链偏好症”所困扰。然而,DeGRPO 算法的引入彻底改变了这一局面。
下图展示了传统 GRPO 和 DeGRPO 算法在训练过程中的模式选择变化曲线。从图中可以看出,传统 GRPO 的长链推理样本数量在训练初期迅速上升,而后又急剧下降,最终趋于稳定,呈现出一种“过山车”式的不稳定趋势。
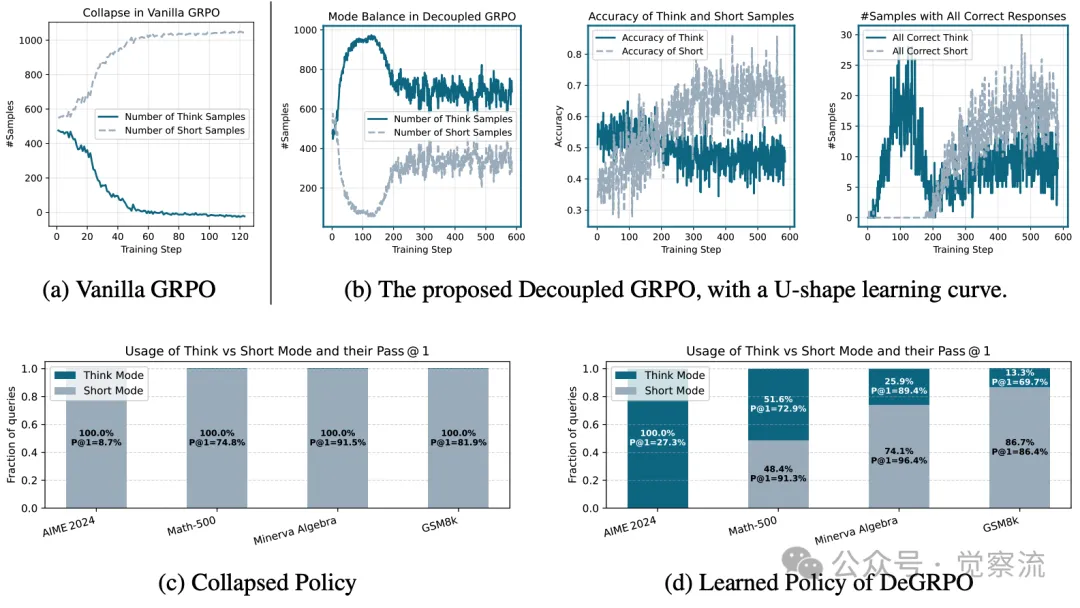
训练策略对比:普通GRPO与解耦GRPO
而 DeGRPO 算法则展现出了独特的 U 型学习曲线。在训练初期,由于长链推理的准确率相对较高,模型会倾向于选择长链推理。但随着训练的深入,短链推理的准确率逐渐提升,模型开始更多地探索短链推理的可能性,短链推理样本数量逐渐增加,最终在训练后期达到一个相对平衡的状态。
控制Token权重的“微妙影响”
控制Token权重 α 在模型学习过程中扮演着至关重要的角色。当 α 值较大时,模型对模式选择的学习速度会显著加快。这意味着在训练初期,模型会更早地学会如何在短链和长链推理之间做出选择,从而更早地出现全正确的短链样本。
然而,过大的 α 值也并非全然无弊。它可能导致模型过早地将一些样本分配给长链推理模式,而忽视了这些样本在短链推理下可能达到的高准确率。这种情况下,模型的决策会变得过于“急功近利”,没有充分考虑到长期的优化潜力。
相反,一个适中的 α 值能够实现模式选择和答案准确性提高的平衡学习。模型会在训练过程中逐步探索两种推理模式的优劣,根据问题的复杂度和自身能力动态调整策略,最终达到一种“智慧”的决策状态。
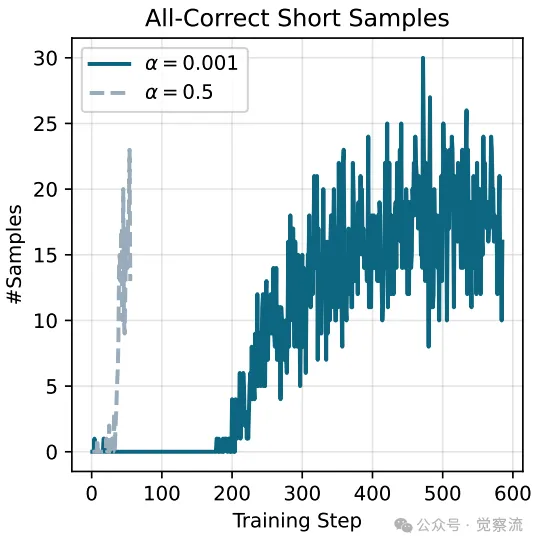
一个较大的token损失系数α加速了推理行为的转变,导致all-correct short-mode samples(全正确短模式样本)的迅速出现
梯度变化与参数更新的“幕后故事”
在不同训练阶段,模型的梯度变化情况和参数更新频率也呈现出独特的规律。在训练初期,由于长链推理样本占据主导地位,长链推理相关的参数更新较为频繁,梯度变化也较大。此时,模型主要在学习如何通过长链推理解决复杂问题,提升整体准确率。
随着训练的进行,短链推理的准确率逐渐提升,短链推理相关的参数更新开始增加,梯度变化也逐渐趋于稳定。这一阶段,模型开始更多地关注如何在保证准确率的前提下减少 token 使用量,提高推理效率。
研究人员详细记录了控制Token权重 α 在不同训练阶段的具体调整策略。例如,在训练初期,给予推理模型较高的权重,使其能够充分传授长链推理的精髓。随着训练的深入,逐渐增加指令遵循模型的权重,使目标模型能够更好地掌握简洁回答的技巧。
通过这种精心设计的训练策略,模型在不同阶段都能够获得最有效的学习信号,从而实现高效的推理模式选择和答案准确性提高。
预训练与蒸馏细节:构建混合推理模型的“基石工程”
知识蒸馏:打造“双面专家”
在预训练热身阶段,知识蒸馏方法被巧妙地运用,为 Thinkless 框架奠定了坚实的基础。研究人员利用两个预训练专家模型:推理模型和指令遵循模型,分别擅长长链推理和简洁回答。这两个模型如同两位经验丰富的导师,共同指导目标模型的学习。
在蒸馏过程中,目标模型需要同时学习两位导师的专长。为了实现这一目标,研究人员精心设计了配对数据集的生成方法。他们从海量问题中筛选出具有代表性的样本,根据问题的复杂度和领域相关性进行分类。对于简单问题,主要参考指令遵循模型的简洁回答;而对于复杂问题,则借鉴推理模型的长链推理过程。
为了平衡两位导师的影响力,研究人员采用了巧妙的权重分配策略。在训练初期,给予推理模型较高的权重,使其能够充分传授长链推理的精髓。随着训练的深入,逐渐增加指令遵循模型的权重,使目标模型能够更好地掌握简洁回答的技巧。
通过这种精心设计的蒸馏过程,目标模型不仅能够生成高质量的长链和短链回答,还能够根据输入问题的复杂度灵活调整回答风格,为后续的强化学习阶段打下了坚实的基础。
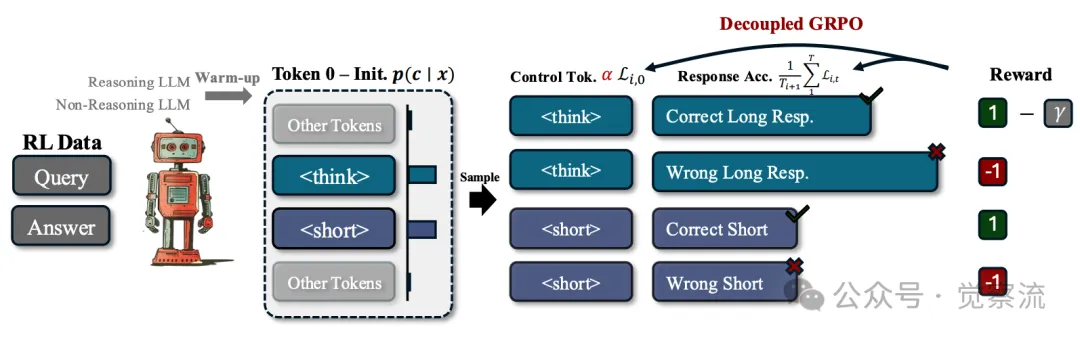
ThinkLess训练了一个混合模型,该模型能够根据任务复杂性和模型容量自适应地选择推理模式。这一过程始于蒸馏,使模型能够遵循控制token(<think>或<short>)来进行引导式推理。随后,通过使用解耦的GRPO进行强化学习,将训练分解为两个目标:优化控制token以实现有效的模式选择,以及精炼回答以提高答案的准确性
数据集效果的“边际递减之谜”
在实验中,研究人员对比了不同规模和领域的蒸馏数据集对模型性能的影响。从 OpenR1-97K 到 OpenThoughts-114K,再到 OpenThoughts-1M,数据集的规模和领域覆盖范围逐渐扩大。结果显示,较大的数据集确实能够带来更好的性能提升,但当数据集规模超过一定阈值后,边际收益开始递减。
OpenR1-97K 数据集虽然规模较小,但其数学领域的专业性使得目标模型能够快速掌握简洁回答的技巧。然而,在面对复杂问题时,模型的长链推理能力稍显不足。
OpenThoughts-114K 数据集在规模和领域覆盖上都有所扩展,目标模型在长链推理和简洁回答方面的表现都有了显著提升。但当数据集进一步扩展到 OpenThoughts-1M 时,虽然模型的长链推理准确率略有提高,但简洁回答的性能提升却并不明显。
这一现象表明,在构建混合推理模型时,数据集的规模并非越大越好。关键在于数据的质量和多样性,以及如何根据模型的特点和任务需求进行合理选择。未来的研究可以进一步探索如何优化数据集的构建方法,提高数据的利用效率,从而实现更高效的混合推理模型训练。
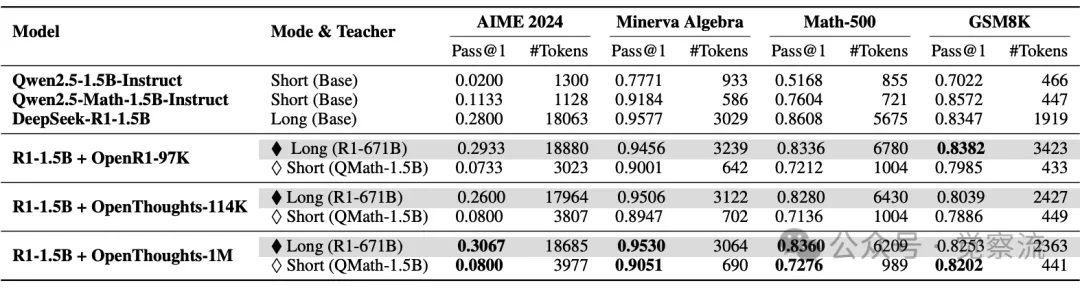
在热身阶段,不同的SFT数据集的有效性。由于这些模型尚未通过强化学习进行优化,因此手动插入控制token <think>和<short>以引出所需的响应模式
案例研究:Thinkless的“实战演练”
MATH-500数据集的概率分布“全景图”
在 MATH-500 数据集中,研究人员展示了 Thinkless 模型对不同难度问题选择 <think> Token的概率分布。从概率分布图中可以看出,模型能够根据问题的复杂度做出精准的判断。
例如,对于简单的算术问题“7 加 2 等于多少”,模型选择 <short> Token的概率极高,几乎接近 100%。这是因为这类问题无需复杂的推理过程,直接给出答案即可。而对于复杂的代数问题,如“求解一元二次方程的根”,模型选择 <think> Token的概率则高达 90%。

在MATH-500中模型发出“<think>”的概率分布。具有最高、中等和最低概率的样本已被突出显示。思考得分接近0的示例主要涉及简单的计算,而概率为1.0的查询则更多依赖于理解和逻辑推理
具体案例
案例1:Minerva Algebra数据集中的简单算术问题
在 Minerva Algebra 数据集中,研究人员选取了一个简单算术问题:“The arithmetic mean of 7, 2, x and 10 is 9. What is the value of x?”。模型迅速识别出问题的简单性,选择了 <short> Token进行简洁回答。
推理过程如下:
1. 问题理解:模型首先理解题目要求求解一个简单的算术平均数问题。
2. 简洁回答:模型直接给出答案:“The value of x is 10.”
通过这个案例,我们可以看到 Thinkless 模型在面对简单问题时的高效性。它无需冗长的推理过程,直接给出简洁明了的答案,大大提高了推理效率。
案例2:AIME 2024数据集中的复杂数学问题
在 AIME 2024 数据集中,研究人员选取了一个复杂数学问题:“Let S be the set of points (a,b) with 0 ≤ a, b ≤ 1 such that the equation x⁴ + a x³ - b x² + a x + 1 = 0 has at least one real root. Determine the area of the graph of S.”。模型识别出问题的复杂性,选择了 <think> Token进行详细推理。
推理过程如下:
1. 问题理解:模型首先理解题目要求求解一个复杂的代数方程的实根问题,并确定相关点集的面积。
2. 详细推理:模型逐步展开推理过程,从方程的性质入手,分析实根存在的条件,逐步推导出点集的边界条件。
3. 最终答案:经过一系列复杂的推理步骤,模型最终给出答案:“The area of the graph of S is 0.5.”
通过这个案例,我们可以看到 Thinkless 模型在面对复杂问题时的强大推理能力。它能够像一位经验丰富的数学家一样,逐步剖析问题,最终给出准确的答案。
案例3:GSM8K数据集中的中等难度问题
在 GSM8K 数据集中,研究人员选取了一个中等难度的问题:“How many r's are in the word 'strawberry'”。模型在不同训练阶段对该问题的推理方式变化如下:
- 训练初期:模型倾向于选择 <think> Token,进行详细的推理过程,逐步分析单词的每个字母,最终得出答案。
- 训练中期:随着短链推理准确率的提升,模型开始更多地选择 <short> Token,直接给出答案:“There are 2 r's in the word 'strawberry'.'
- 训练后期:模型已经能够根据问题的复杂度灵活选择推理模式,对于这类中等难度的问题,它会根据实际情况在短链和长链推理之间做出最优选择。
通过这个案例,我们可以看到 Thinkless 模型在训练过程中的动态学习能力。它能够根据问题的难度和自身能力的变化,不断调整推理策略,最终达到高效且准确的推理效果。
开源仓库实操
安装指南
在开始使用 Thinkless 框架之前,确保你的环境已经正确配置。以下是详细的安装步骤:
conda create -n thinkless pythnotallow==3.10 conda activate thinkless git clone https://github.com/VainF/Thinkless.git cd Thinkless pip install -r requirements.txt
快速开始代码
以下是一个完整的推理代码示例,展示了如何加载模型、设置控制Token以及生成答案:
from transformers import AutoModelForCausalLM, AutoTokenizer model_name = "Vinnnf/Thinkless-1.5B-RL-DeepScaleR" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) prompt = "The arithmetic mean of 7, 2, x and 10 is 9. What is the value of x?" inputs = tokenizer(prompt, return_tensors="pt") outputs = model.generate(**inputs, max_new_tokens=16384, temperature=0.6) answer = tokenizer.decode(outputs[0], skip_special_tokens=True) print(answer)
模型调用示例
在实际应用中,你可以根据问题类型动态选择推理模式。以下是一个示例函数:
def infer(question, use_think_mode=False):
if use_think_mode:
prompt = "<think>" + question
else:
prompt = "<short>" + question
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=16384, temperature=0.6)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return answer参数优化建议
根据业务需求调整 α 值和控制Token。例如,如果对效率有较高要求,可以适当降低 α 值,促使模型更多地选择短链推理模式。
总结一下
Thinkless 框架通过巧妙的双控制Token与DeGRPO算法结合,该框架赋予了模型自主选择推理深度的能力,使其能够在效率与性能之间实现动态平衡。在一系列严苛的实验验证下,Thinkless 展现出了卓越的效率提升能力,大幅减少了长链推理的使用频率,有效降低了系统资源消耗,同时在复杂问题上依然保持着出色的准确率表现。
这一创新思路不仅体现了研究人员对LLM推理模式的深刻洞察,更彰显了其在算法设计上的巧妙构思。从引入能够精准引导模型推理行为的special Token,到通过DeGRPO算法巧妙平衡模式选择与答案准确性优化目标,每一个设计细节都旨在让模型在面对不同复杂度的任务时,能够做出最为恰当的推理策略决策。
另外,尽管Thinkless框架已经在提升推理效率和保持高性能方面取得了显著成就,但AI领域的探索永无止境。研究人员计划继续优化模型的初始性能,深入挖掘更高效的混合模型构建策略,例如借助先进的模型融合技术或轻量级微调方法。此外,将Thinkless框架扩展应用于更广泛的领域和数据集,如自然语言处理和图像识别等,也将是未来研究的重要方向。这不仅能够进一步验证该框架的普适性和鲁棒性,也将为AI技术在更多实际场景中的应用提供强有力的支持。


