图片

AI 在用 | 花半小时,你也能主演《龙猫》
机器之能报道编辑:Cardinal以大模型、AIGC为代表的人工智能浪潮已经在悄然改变着我们生活及工作方式,但绝大部分人依然不知道该如何使用。因此,我们推出了「AI在用」专栏,通过直观、有趣且简洁的人工智能使用案例,来具体介绍AI使用方法,并激发大家思考。 我们也欢迎读者投稿亲自实践的创新型用例。把自己变成一个动漫演员,很难吗?就像这样:视频链接: lowfi boy:)视频链接:::视频链接::视频链接: AIGC 工具,再花上半小时,你能成为任何动漫世界的主角。过程有多复杂?和炒一盘西红柿炒鸡蛋差不多:)先

AI生图、扩图、去水印……全免费!「Sora 平替」Viva 玩了把大的
机器之能报道编辑:山茶花通通免费!AI功能「大杂烩」Viva,抢了美图秀秀的饭碗。话接上回。(查看详情请移步:「Sora 平替」来了!一键生成 5 秒视频,还免费,我们实测:很顶!)国内的美图秀秀有 AI 视觉设计「大杂烩」之称,只要是市面上比较火的图片处理功能,都能在美图秀秀上找到身影。而 Viva 堪称国外版「美图秀秀」,除了视频生成功能外,还有文生图、图生文、智能抠图、AI 扩图等,而且是把免费进行到底!文生图:Midjourney 被「偷家」Viva 野心不小,既想和 Sora 一较高下,又要抢 Midjo

ICLR 2024 Spotlight | NoiseDiffusion: 矫正扩散模型噪声,提高插值图片质量
作者 | Pengfei Zheng单位 | USTC, HKBU TMLR Group最近生成式AI的迅猛发展为文本到图像生成、视频生成等令人瞩目的领域注入了强大的动力,这些技术的核心在于扩散模型的应用。扩散模型首先通过定义一个不断加噪声的前向过程来将图片逐步变为高斯噪声,再通过逆向过程将高斯噪声逐步去噪变为清晰图片以得到采样。其中扩散常微分模型可以被用于生成的图片的插值,这在生成视频以及一些广告创意上有着极大的应用潜力。然而,我们注意到,当这种方法应用于自然图片时,插值出的图片效果往往不尽如人意。通常情况下,扩
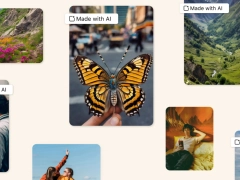
应对隐私 / 版权问题,5 月起 Meta Threads / Instagram 等平台将标记“疑似由 AI 生成的内容”
感谢AI 兴起产生的各种隐私 / 版权问题如今已成为科技行业许多人越来越关注的重点,而 Meta 公司今日发布新闻稿,宣布将在 5 月起在自家 Instagram、Threads 及 Facebook 平台为 AI 内容添加“水印标记”。Meta 在新闻稿中声称,这些变化来自公司内部监督委员会的建议、公共调查的结果和“学术界、民间社会组织和其他方面”的建议。IT之家注意到,Meta 公司将使用算法及真人检测“可能由 AI 生成的内容“,而用户也可以自行在图片中注释”相关图片由 AI 生成”,此类消息将作为水印添加至

OpenAI 为 DALL-E 3 引入编辑功能:进一步精细化调整已生成图片
OpenAI 公司近日发布公告,宣布为 DALL-E 3 引入全新的编辑界面,在基于用户文本生成图片之后,可以继续根据用户描述精细化调整已生成的图片。DALL-E 编辑器提供两种主要编辑方法:基于选择区域的编辑:在 DALL-E 3 生成图片之后,用户可以选中已生成图片中的特定区域,然后再在聊天界面,输入提示词要求 DALL-E 3 进行微调。对话式编辑:在 DALL-E 3 生成图片之后,用户无需选择特定区域,在聊天窗口中直接描述自己的编辑内容,这种方法适用于编辑调整整个图像。OpenAI 表示通过引入该编辑器,
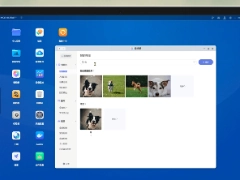
极空间 NAS 上线“AI 实验室”功能:自然语言搜图、以图搜图、文字识别
极空间 NAS 官方宣布,全新 AI 功能 ——【AI 实验室】已正式上线,功能包括:自然语言搜索、相似图片搜索和图片文字识别。据介绍,【AI 实验室】可以帮助用户快速找出极相册中需要的图片,IT之家附内容如下:自然语言搜索智能搜图,开启后,可以使用自然语言搜索图片。点击智能 AI,开启智能搜图,在搜索框中输入文字“狗”,通过 AI 计算后,稍等片刻,就会把极相册中带“狗”的照片展示出来。相似图片搜索以图搜图,开启后,可以通过一张照片找到相似内容或是风格的其他图片。点击智能 AI,开启以图搜图,在极相册中找到一张你
夸克大模型应用为先加持夸克网盘深挖相册使用场景
2024年将是大模型应用落地的爆发年,这已经成为业界共识。夸克大模型自去年11月份发布以来,结合自身业务小步快跑,在夸克App上已经落地了多个应用。最近,夸克网盘结合春节场景和大模型技术,升级几项图片处理智能工具。夸克网盘即将上线的“春节图片故事”,是为用户春节期间拍摄上传的图片自动智能筛选生成合辑。该功能除了基于时间、地点两个维度筛选,还会基于人物智能筛选,并剔除掉过亮或过暗等不符合要求的图片。夸克网盘还会利用AI算法为图片合辑智能生成文案,比如鲜花影集的文案是“花与美妙人间”。此前,AI技术还被应用在夸克网盘相

一张图,就能「接着舞」,SHERF可泛化可驱动人体神经辐射场的新方法
输入的一张任意相机角度 3D 人体图片,Ta 就能动啦!

ICML 2021 | 基于装配的视频无监督部件分割
本文是第三十八届国际机器学习会议(ICML 2021)入选论文《基于装配的视频无监督部件分割(Unsupervised Co-part Segmentation through Assembly)》的解读。
该论文由北京大学陈宝权-刘利斌研究团队与山东大学、北京电影学院未来影像高精尖创新中心合作,提出了一种无监督的图像部件分割方法,创新性地采用了将部件分割过程和部件装配过程相结合的自监督学习思路,利用视频中的运动信息来提取潜在的部件特征,从而实现对物体部件的有意义的分割。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉