模型训练
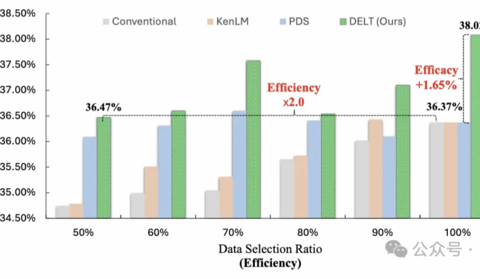
调整训练数据出场顺序大模型就能变聪明!无需扩大模型/数据规模
模型训练重点在于数据的数量与质量? 其实还有一个关键因素——. 数据的出场顺序。

基于 DeepSeek GRPO 的 1.5B Rust 代码生成模型训练实战
群组相对策略优化(Group Relative Policy Optimization,GRPO)已被证明是一种有效的算法,可用于训练大语言模型(LLMs),使其具备推理能力并在基准测试中持续提升性能表现。 DeepSeek-R1 展示了如何通过监督式微调(Supervised Fine-Tuning)与 GRPO 技术的结合,引导模型达到与 OpenAI 的 o1 等顶尖模型相竞争的水平。 为了进一步探索其实践应用,我们尝试将这些技术应用于现实场景中。

如何避免交叉验证中的数据泄露?
大家好,我是小寒在机器学习中,交叉验证(Cross-Validation)是一种常用的模型评估技术,目的是通过将数据集分割为多个子集,反复训练和验证模型,以便更好地估计模型的性能。 然而,在交叉验证过程中,数据泄露(Data Leakage) 是一个非常严重的问题,它会导致模型的评估结果过于乐观,进而使得模型在实际应用中表现不佳。 什么是数据泄露数据泄露是指在模型训练过程中,模型不恰当地接触到了与验证集或测试集相关的信息,导致模型的训练过程中“提前知道”了本应该不在训练数据中的信息。

将偏好学习引入模型训练,北大李戈团队新框架,可显著提升代码准确性与执行效率
代码模型SFT对齐后,缺少进一步偏好学习的问题有解了。 北大李戈教授团队与字节合作,在模型训练过程中引入偏好学习,提出了一个全新的代码生成优化框架——CodeDPO。 在部分模型上,相比于单独使用SFT,CodeDPO能够将模型的HumanEval得分再多提升10个百分点,最高增幅接近1/3。

月薪10K+的AI训练师,工作内容是什么?
爆肝2W字! 用奶奶都能看懂的文字带你了解AIGC的前世今生大家好,我是言川。 阅读文章 .

优设专访忠忠:从设计师到SD模型训练师的跨界之路

超详细!写给设计师的LoRa模型训练SOP
写在前面:
在推进 AIGC 技术在我们业务中的应用过程中,我发现许多同事,特别是设计师和跨部门协作的团队,对 LoRA 模型在图像生成中的真正价值理解还不够深入。我们似乎更多地停留在"别人在做,我也要做"的从众心态,而没有真正认识到 LoRA 模型的战略意义和变革潜力。
这种认知差距可能会导致我们在实践中走一些弯路,无法充分发挥 LoRA 模型的优势,也难以实现 AIGC 技术在业务中的最大化赋能。因此,我针对 LoRA 模型训练流程进行了系统梳理和优化,希望能给大家一些启发,帮助我们更好地理解和应用这一强大的工
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉