Mixtral 8X7B

Mixtral 8x7B论文终于来了:架构细节、参数量首次曝光
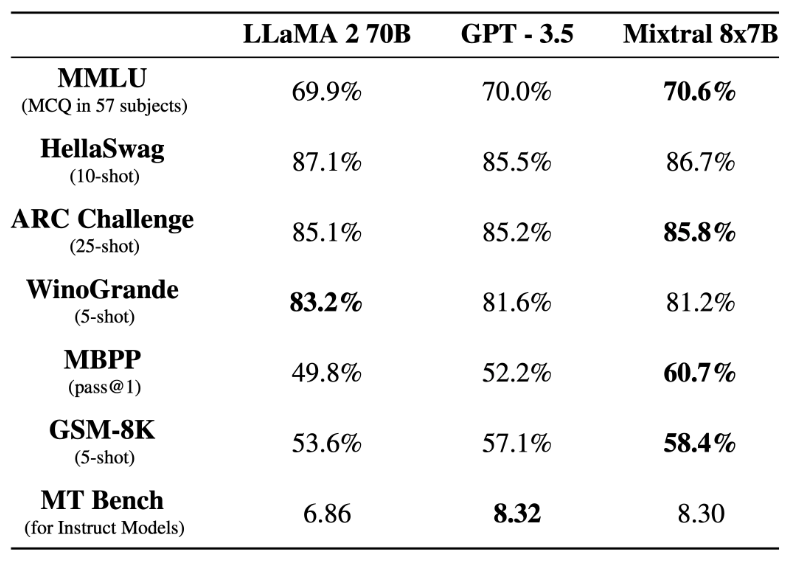
Mixtral 8x7B 在大多数基准测试中都优于 Llama 2 70B 和 GPT-3.5。前段时间,那个爆火整个开源社区的 Mixtral 8x7B MoE 模型论文放出了。此前,由于 OpenAI 团队一直对 GPT-4 的参数量和训练细节守口如瓶。Mistral 8x7B 的放出,无疑给广大开发者提供了一种「非常接近 GPT-4」的开源选项。要知道,很早之前就有人爆料,OpenAI 也是采用了「混合专家模型」(Mixture of Experts,MoE)的构架来搭建 GPT-4。随着论文的放出,一些研究
8x7B MoE与Flash Attention 2结合,不到10行代码实现快速推理
感兴趣的小伙伴,可以跟着操作过程试一试。前段时间,Mistral AI 公布的 Mixtral 8x7B 模型爆火整个开源社区,其架构与 GPT-4 非常相似,很多人将其形容为 GPT-4 的「缩小版」。我们都知道,OpenAI 团队一直对 GPT-4 的参数量和训练细节守口如瓶。Mistral 8x7B 的放出,无疑给广大开发者提供了一种「非常接近 GPT-4」的开源选项。在基准测试中,Mistral 8x7B 的表现优于 Llama 2 70B,在大多数标准基准测试上与 GPT-3.5 不相上下,甚至略胜一筹。

成立仅半年,Mistral估值暴涨七倍,开源重塑AI战局
机器之能报道编辑:Sia烧钱的闭源,逆袭的开源。当 LLaMA 被泄露出去、任何人都可以下载时,开源的命运齿轮已经开始转动,并在 Mistral AI 最新一轮融资中达到高潮。七个月前,来自 Meta 和谷歌的研究人员在巴黎成立了 Mistral AI 。短短六个月,这家拥有22名员工的初创企业在最近 A 轮融资中筹集了 4.15 亿美元,估值从 2.6 亿美元狂飙到 20 亿美元,涨了七倍多。同时,公司也低调发布了大模型 Mixtral 8X7B。Mixtral 8x7B 采用了一种独特的架构方法——专家混合 (
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉