分割

藏在国民APP里的黑科技:美图CVPR 2025五大新突破!
2025年,计算机视觉领域三大顶级会议之一的CVPR(国际计算机视觉与模式识别会议)投稿量再次刷新纪录,超过13000篇工作进入评审流程,录用比例仅为22.1%,相较去年再次下降1.5%。 美图旗下美图影像研究院(MT Lab)联合清华大学、新加坡国立大学、北京理工大学、北京交通大学等知名高校发布的5篇论文入选CVPR 2025,均聚焦于图像编辑领域,分布在生成式AI、交互式分割、3D重建三个方面。 在研发方面的突破代表美图在核心视觉领域竞争力的持续提升,AI助推下美图产品力持续提升,也带动了更高的用户粘性和付费意愿,深度结合前沿技术与探索可落地的实用价值,成为美图成功在影像与设计领域打造AI产品的重要驱动力。
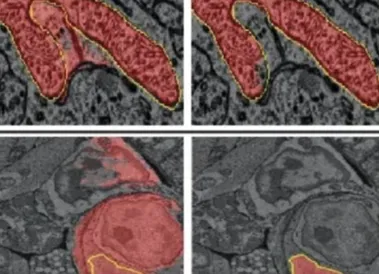
Nature子刊 | 光镜电镜通用,Meta「分割一切」模型用到显微镜图像上了
编辑丨coisini识别显微镜图像中的对象,例如光学显微镜(LM)下的细胞和细胞核是生物学图像分析中的关键任务之一。 由于显微镜成像方式的多样性和不同维度(二维 / 三维,时间维度)的存在,这些识别任务具有挑战性,目前需要采用不同的方法来解决。 基于深度学习的方法在过去几年中显著改善了 LM 下的细胞和细胞核分割,电子显微镜(EM)下的细胞、神经元和细胞器分割。

Meta SAM 2 登场:首个能在图片和视频中实时分割对象的统一开源 AI 模型
感谢Meta 公司发布 Meta Segment Anything Model 2(SAM2),SAM 2 能分割任何目标,能在一个视频中实时追踪所有镜头 —— 解锁新的视频编辑能力并在混合现实中提供新的体验。Meta 公司今天发布新闻稿,介绍了全新的 Meta Segment Anything Model 2(SAM 2)模型,先支持分割视频和图像中的对象。开源Meta 公司宣布将以 Apache 2.0 许可发布 SAM 2,因此任何人都可以使用它来构建自己的体验。Meta 还将以 CC BY 4.0 许可共享

美图影像研究院(MT Lab)斩获3项国际人工智能顶会大奖
5月30日,国际人工智能顶会CVPR 2024举办的第3届野外像素级视频理解挑战赛(The 3rd Pixel-level Video Understanding in the Wild, PVUW。下文简称PVUW)公布赛事结果,美图影像研究院(MT Lab)再获殊荣,斩获视频语义分割(VSS)、复杂场景视频目标分割(MOSE)双赛道亚军,视频全景分割挑战赛(VPS)赛道季军,这也是美图影像研究院(MT Lab)第3次在CVPR大会上摘得奖项,共获得了1金3银3铜的杰出成绩。作为全球范围内计算机视觉领域的顶级会议
涵盖文本、定位和分割任务,智源、港中文联合提出首个多功能3D医学多模态大模型
作者 | 香港中文大学白帆编辑 | ScienceAI近日,香港中文大学和智源联合提出的 M3D 系列工作,包括 M3D-Data, M3D-LaMed 和 M3D-Bench,从数据集、模型和测评全方面推动 3D 医学图像分析的发展。(1)M3D-Data 是目前最大的 3D 医学图像数据集,包括 M3D-Cap (120K 3D 图文对), M3D-VQA (510K 问答对),M3D-Seg(150K 3D Mask),M3D-RefSeg (3K 推理分割)共四个子数据集。(2)M3D-LaMed 是目前最

ICLR2024 | Harvard FairSeg: 第一个研究分割算法公平性的大型医疗分割数据集
作者 | 田宇编辑 | 白菜叶近年来,人工智能模型的公平性问题受到了越来越多的关注,尤其是在医学领域,因为医学模型的公平性对人们的健康和生命至关重要。高质量的医学公平性数据集对促进公平学习研究非常必要。现有的医学公平性数据集都是针对分类任务的,而没有可用于医学分割的公平性数据集,但是医学分割与分类一样都是非常重要的医学 AI 任务,在某些场景分割甚至优于分类,因为它能够提供待临床医生评估的器官异常的详细空间信息。在最新的研究中,哈佛大学(Harvard University)的Harvard-Ophthalmolo

CVPR23 Highlight | 多模态新任务、新数据集:NTU提出广义引用分割问题GRES
引用表达分割(Referring Expression Segmentation,简称引用分割或RES)是一个基础的视觉语言多模态任务。给定一张图像和一个描述该图像中某个对象的自然语言表达式,RES旨在找到该目标对象并将其分割。现有的引用分割数据集和方法通常仅支持单目标表达式,即一个表达式指代一个目标对象。而对于多目标和无目标表达式的情况,则没有考虑在内。严重限制了引用分割的实际应用。基于这个问题,来自新加坡南洋理工大学的研究者们定义了一个名为广义引用分割(Generalized Referring Expression Segmentation,GRES)的新任务,将经典的引用分割扩展到允许表达式指代任意数量的目标对象。同时,文章还构建了第一个大规模的GRES数据集gRefCOCO,其同时包含多目标、无目标和单目标表达式。

ICML 2021 | 基于装配的视频无监督部件分割
本文是第三十八届国际机器学习会议(ICML 2021)入选论文《基于装配的视频无监督部件分割(Unsupervised Co-part Segmentation through Assembly)》的解读。
该论文由北京大学陈宝权-刘利斌研究团队与山东大学、北京电影学院未来影像高精尖创新中心合作,提出了一种无监督的图像部件分割方法,创新性地采用了将部件分割过程和部件装配过程相结合的自监督学习思路,利用视频中的运动信息来提取潜在的部件特征,从而实现对物体部件的有意义的分割。

技术博客丨动手实践系列:CV语义分割!
作者:游璐颖,福州大学,Datawhale成员 图像分割是计算机视觉中除了分类和检测外的另一项基本任务,它意味着要将图片根据内容分割成不同的块。相比图像分类和检测,分割是一项更精细的工作,因为需要对每个像素点分类。如下图的街景分割,由于对每个像素点都分类,物体的轮廓是精准勾勒的,而不是像检测那样给出边界框。图像分割可以分为以下三个子领域:语义分割、实例分割、全景分割。 由对比图可发现,语义分割是从像素层次来识别图像,为图像中的每个像素制定类别标记,目前广泛应用于医学图像和无人驾驶等;实例分割相对更具有挑战性,不仅需

海内外71支劲旅角逐青光眼AI,视杯盘分割任务体素科技团队斩获第一
MICCAI(Medical Image Computing and Computer Assisted Intervention)始于1998年的麻省理工学院,意在探索医学影像、计算机辅助介入以及两者融合的价值。20逾年的发展,MICCAI已成为医学影像分析行业的顶级学术会议。百度组织的眼科医学影像分析研讨会OMIA (Ophthalmic Medical Image Analysis)是眼科影像领域的重点研讨会之一,至今已举办八届。2021MICCAI之上,OMIA将议点聚焦于青光眼之上,举办了GAMMA挑战赛

优秀!2021年谷歌博士生奖研金陆续揭晓,同济校友王鑫龙、南大校友李昀入选
在近日公布的谷歌2021博士生奖研金部分名单中,来自阿德莱德大学、新南威尔士大学、昆士兰科技大学和悉尼大学的四位博士生获得该殊荣。

CVPR 2021 | 创新奇智首次提出零样本实例分割,助力解决工业场景数据瓶颈难题
对于数据发现、数据粗筛、辅助标注、模型基本能力探索等方面有巨大的提升。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉