
译者 | 核子可乐
审校 | 重楼
检索增强生成(RAG)是一种将语言模型与外部知识源结合的AI系统构建方法。简单来说,AI会先搜索与用户查询相关的文档(如文章或网页),然后利用这些文档生成更准确的答案。这种方法因能帮助大语言模型(LLM)扎根真实数据、减少虚构信息而受到推崇。
直观上,人们往往认为AI检索的文档越多,答案就越准确。然而最新研究表明,在向AI提供信息时,有时"少即是多"反而才是正解。
更少文档,更优答案
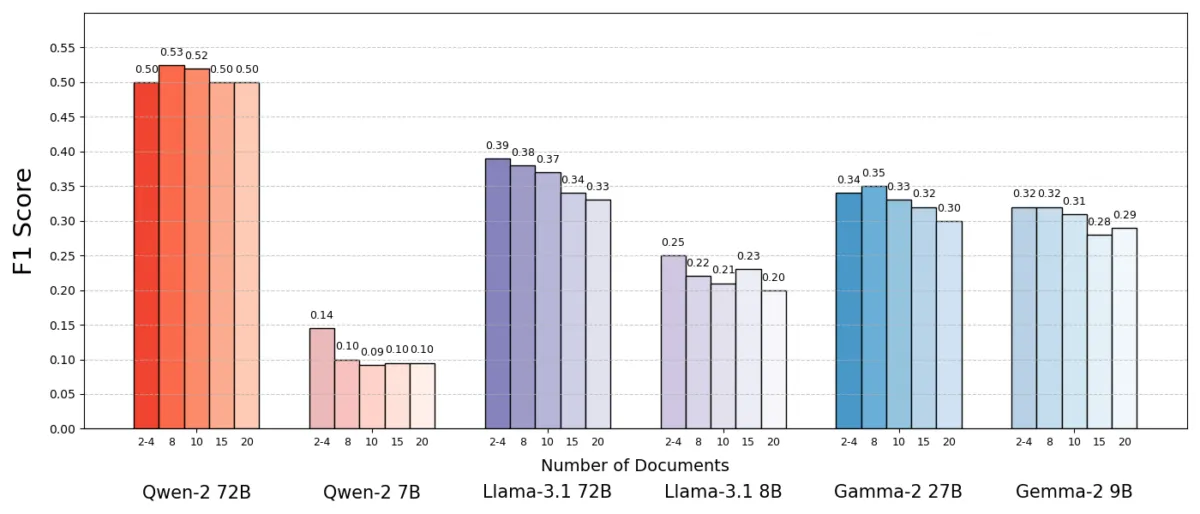
耶路撒冷希伯来大学的研究团队探索了文档数量对RAG系统性能的影响。关键实验设计在于保持总文本量恒定——当减少文档数量时,研究者会扩展剩余文档的篇幅,使总长度与多文档方案保持一致。这种设计确保性能差异仅归因于文档数量,而非输入长度。
研究人员使用包含常识问题的MuSiQue数据集,每个问题原本配有20段维基百科文本(其中仅少数包含答案,其余为干扰项)。通过从20段精简到仅保留2-4段核心相关文档,并补充额外上下文保持总长度一致,他们创造了AI需要处理的文档更少但总阅读量相同的场景。
实验结果令人惊讶:在多数情况下,当AI仅获得少量文档时,答案准确性反而更高。某些情况下,使用少数支持文档的系统准确率(F1得分)比使用全量文档提升多达10%。这种反直觉的改进在多个开源语言模型(包括Meta的Llama变体等)中均有体现,表明该现象并非特定于某个模型。
例外情况出现在Qwen-2模型上,它在处理多文档时未出现性能下降,但几乎所有被测模型在文档减少后整体表现更优。换言之,在核心相关文档之外增加更多参考资料,更多时候会损害而非提升性能。
为什么结果与直觉感受相反?传统上,RAG系统默认信息越多则AI得出的答案越准确——毕竟若前几份文档未包含答案,添加更多文档应该会有所帮助。
但此项研究反转了这一假设。哪怕是在文本总长度保持不变的前提下,文档数量越多则会令AI越是疲于应对。似乎在超过某个临界点后,每个额外文档引入的信号更多、导致模型混乱,并最终削弱了它提取正确答案的能力。
为何RAG中“少即是多”?
这种"少即是多"的结果可通过AI语言模型的信息处理方式解释。当AI仅获得最相关文档时,其处理的上下文更聚焦且无干扰,类似于学生只拿到关键学习材料。
研究中,模型在仅保留支持文档(移除无关材料)时表现显著提升。剩余内容不仅更简短且更纯净——仅包含直接指向答案的事实。需要处理的文档减少后,模型能更专注地分析关键信息,降低分心或混淆的可能性。
相反,当检索大量文档时,AI需要筛选相关与无关的杂糅内容。这些额外文档往往是"相似但无关"——可能与查询拥有相同的主题或关键词,但实际不包含答案。此类内容可能误导模型:AI可能徒劳地在无关文档间建立联系,或更糟的是错误融合多源信息,增加生成虚构信息的风险——即答案看似合理却无事实依据。
本质上,向模型输入过多文档会稀释有效信息并引入矛盾细节,使AI更难判断事实。
有趣的是,研究人员发现如果额外文档明显无关(如随机无关文本),模型更善于忽略它们。真正的问题源于看似相关的干扰信息:当所有检索文本主题相似时,AI会假设都需要使用,却难以辨别重要细节。这与研究中观察到的现象一致——随机干扰项造成的混淆小于真实干扰项。AI能过滤明显谬误,但微妙偏离主题的信息更具迷惑性——它们以相关性为伪装,导致答案偏离。通过仅保留必要文档,可从源头避免这类陷阱。
这一发现还拥有实际效益:检索和处理更少文档能降低RAG系统的计算开销。每份文档都需要分析(嵌入、阅读和注意力分配),消耗时间和计算资源。减少冗余文档可提升系统效率——更快且更低成本地找到答案。

重新审视RAG:未来方向
这项关于"质胜于量"的新证据,对依赖外部知识的AI系统未来具有重要影响。这表明RAG系统设计者应优先进行智能过滤和文档排序,而非追求数量。与其检索100段可能包含答案的文本,不如仅获取少数高度相关的文档。
研究团队强调,检索方法需要"在信息供给的相关性与多样性之间取得平衡"。即需覆盖足够主题以回答问题,但避免核心事实被无关文本淹没。
未来,研究人员可能探索帮助AI模型更优雅处理多文档的技术。一个方向是开发更优质的检索系统或重排器,识别真正有价值的文档并剔除冲突源。另一个角度是改进语言模型本身:既然Qwen-2模型能在多文档中保持准确性,分析其训练或结构特点,可为提升其他模型健壮性提供线索。未来的大型语言模型或许能内置机制,识别不同来源的信息一致性或矛盾性,并据此调整关注重点,最终在利用丰富信息源的同时避免混淆——实现信息广度与焦点清晰的兼顾。
换句话说,随着AI系统上下文窗口扩大(即单次读取更多文本的能力),简单填充更多数据并非万能解药。更大的上下文不等于更好的理解。本研究表明,即使AI能读取50页文本,输入50页混杂信息也可能效果不佳。模型仍受益于精选相关内容,而非无差别信息堆砌。事实上,在巨型上下文窗口时代,智能检索可能愈发关键——确保额外容量用于吸收有价值的知识,而非噪音。
《更多文档,相同长度(More Documents, Same Length)》论文的发现,促使我们重新审视AI研究中的假设。有时,向AI提供全部数据的效果并不如预期。通过聚焦最相关信息,我们不仅能提升AI答案的准确性,还能让系统更高效、更值得信赖。这个反直觉的结论具有令人兴奋的启示:未来的RAG系统可能通过精心选择更少但更优的文档,变得更加智能且精简。
原文标题:Less Is More: Why Retrieving Fewer Documents Can Improve AI Answers,作者:Alex McFarland


