
大家好,我是肆〇柒。本文分享的这篇工作来自通义实验室(Tongyi Lab, Alibaba Group)的最新研究成果——ReSum。他们提出了一种全新的推理范式,让大模型智能体在面对复杂问题时,能够像人类一样“停下来复盘、做笔记”,从而突破传统上下文长度限制,实现真正意义上的长程探索。这项工作不仅刷新了多个基准性能,更揭示了通往更高级智能体的关键路径。本篇是通义 Deepresearch 发布的系列研究之一。
当Web智能体能够主动搜索、浏览、提取并综合开放网络信息时,复杂知识密集型任务的解决似乎触手可及。然而,一个看似简单却影响深远的限制——上下文窗口——正阻碍着智能体向更复杂问题发起挑战。下面,我们就一起探索这项创新性的工作:ReSum,看看它如何通过精巧的"上下文总结"机制,为智能体解锁长程搜索智能的新境界。
ReAct —— 一个经典范式
ReAct(Reasoning and Acting)范式自2023年提出以来,已成为当前最主流的Agentic Workflow。它定义了简洁而强大的Thought-Action-Observation交互循环:LLM基于现有上下文生成推理步骤(Thought),执行可解析的工具调用(Action),并接收环境反馈(Observation)。这种范式使LLM能够有效调用搜索、浏览等工具解决复杂问题,奠定了现代Web智能体的基础。
在形式化定义中,一个包含T次迭代的完整轨迹可表示为:

然而,ReAct的简洁背后隐藏着一个矛盾:其"线性增长"的上下文管理策略与"指数复杂"的现实问题之间的不匹配。在ReAct中,每个交互步骤(Thought、Action、Observation)都被附加到对话历史中,随着探索深入,上下文长度线性增长。当面临需要大量工具调用的复杂查询时——例如"一位画家,其父亲死于心脏病,有一个姐姐和五个孩子,后来婚姻破裂又有三段关系,基于此人的文学作品叫什么?"这类涉及多实体、交织关系和高度不确定性的任务——智能体往往在找到答案前就耗尽了上下文预算。
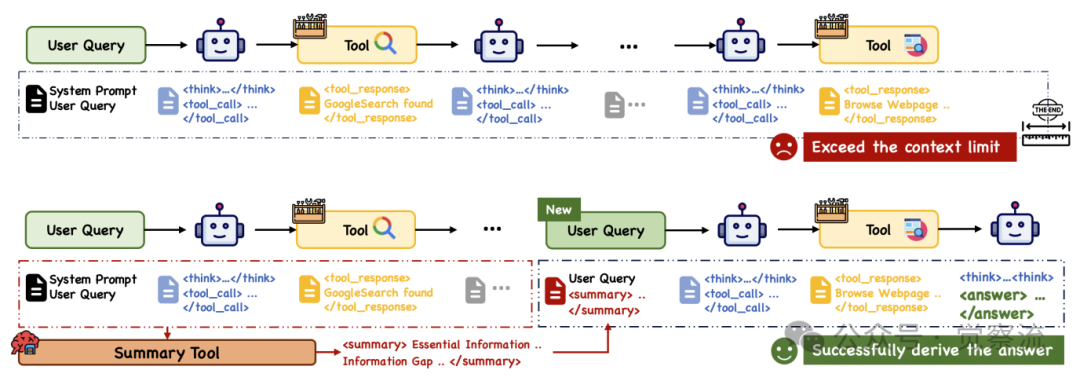
ReAct与ReSum范式对比
如上图所示,ReAct范式在多轮探索完成前就耗尽了上下文预算,而ReSum通过周期性调用总结工具压缩历史并从压缩摘要中恢复推理,实现了无限探索。对WebSailor-7B在BrowseComp-en基准上的行为分析进一步揭示了这一限制:
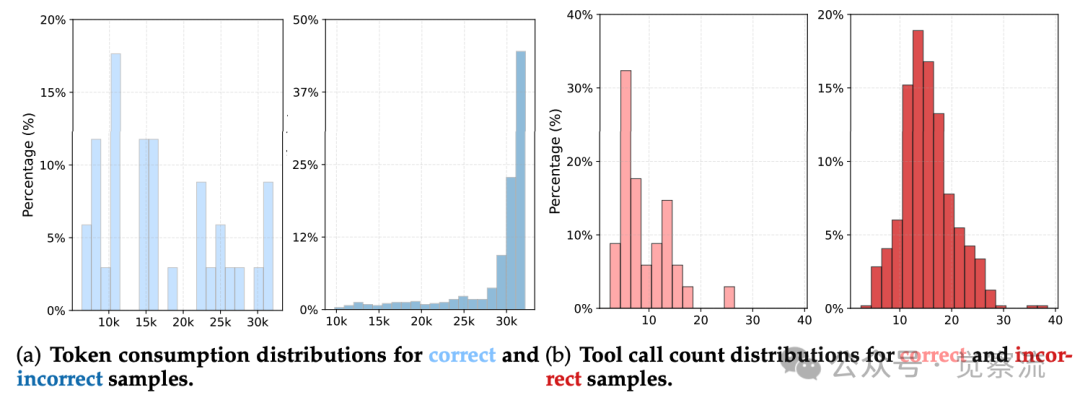
ReAct上下文限制对探索的约束
如上图所示,WebSailor-7B在BrowseComp-en上的行为分析显示,成功解决的案例通常在10次工具调用内完成,token消耗相对较低;而失败案例往往超过10次,甚至20次,导致token使用量急剧上升,超过32k限制。这一数据直观揭示了ReAct范式在面对复杂查询时的"硬性天花板"——当智能体需要超过32k token的上下文时,被迫提前终止,导致复杂问题无法解决。
现有解决方案如A-Mem和MemOS等外部记忆模块虽能结构化管理上下文,但增加了系统复杂度和计算开销,且与策略模型的集成不够紧密。相比之下,ReSum探索了一条更轻量、内聚的路径——将记忆管理内化为推理流程本身,无需额外组件即可实现上下文约束的突破。
ReSum的诞生——一种"内生压缩"的新范式
ReSum的核心哲学不是增加外部组件,而是优化内部工作流,将"记忆管理"作为推理过程的自然延伸。这一设计灵感源于人类认知:当解决复杂问题时,我们会不断"复盘"和"记笔记",提炼关键信息并重新组织思路。ReSum正是模拟了这一高级认知行为,使智能体具备"自我反思"能力。

ReSum 结合周期性上下文摘要的 Rollout 算法伪代码
ReSum的工作流程严格遵循上图算法,其核心在于"触发-总结-重置"的闭环:
轨迹初始化:轨迹始于用户查询q,初始化H₀=(q)。遵循ReAct范式,智能体交替进行内部推理和工具使用:(τₜ, aₜ)~πθ(·|Hₜ₋₁)。
上下文总结:当触发条件满足(如达到token预算),调用总结工具πₛᵤₘ将历史压缩为结构化摘要s~πₛᵤₘ(·|Hₜ),形成压缩状态q'=(q, s)并重置工作历史。
轨迹终止:通过周期性总结,ReSum动态维持上下文在模型窗口内,同时保留关键证据。虽然理论上允许无限探索,但实际部署中会设置资源预算(如工具调用次数限制)。
这种设计既保留了ReAct的简洁高效,又规避了其上下文限制,为长程探索开辟了新可能。正如论文所述:"ReSum实现了长程推理,同时最小化对ReAct的修改,避免了架构复杂性,确保了即插即用的兼容性。"这种设计不仅保留了ReAct的简洁高效,还使其能够无缝集成到现有agent生态系统中,无需重构整个系统即可获得长程推理能力。
ReSum的三大创新点彰显其范式价值:
- 状态压缩(State Compression):将历史对话转化为紧凑的推理状态,其中是结构化摘要,包含验证证据和信息缺口
- 重启能力(Restartability):从压缩状态继续推理,打破了上下文长度的硬性限制,理论上允许无限探索
- 最小侵入性(Minimal Intrusion):仅需在标准ReAct流程中插入可选的"总结-重置"环节,其余交互协议完全不变,使其能够"即插即用"地适配现有WebSailor、WebExplorer等主流Agent架构
假想一位侦探调查复杂案件:随着线索增多,他的笔记本逐渐写满。与其继续添加新页导致混乱,聪明的侦探会定期将关键线索整理到一张新纸上,丢弃冗余信息,然后基于这张"线索摘要"继续调查。ReSum正是模拟了这种高级认知行为——当思维过于庞杂时,提炼关键信息并重新组织思路,从而突破记忆限制。
这种"内生压缩"机制虽然优雅,但对总结工具提出了更高要求——它必须能够从嘈杂的交互历史中提取关键证据,而非简单压缩文本。这引出了ReSumTool的设计挑战,也是ReSum范式成功的关键所在。
专业化分工——ReSumTool作为"认知压缩器"
在ReSum范式中,总结工具的角色远非简单的摘要器,而是智能体的"认知伙伴",负责将原始感知升华为结构化知识。它必须执行逻辑推理、从嘈杂交互历史中提取可验证证据、识别信息缺口并提出下一步行动建议。通用摘要模型往往难以胜任这一任务——实验表明,小型模型在长对话中难以有效提取关键证据,而大型模型虽有优势但API成本和部署开销过高。
ReSumTool的提示工程经过精心设计,包含严格的信息处理规则:
- 仅提取对话中明确存在的相关信息
- 不做假设、猜测或超出明确陈述的推断
- 仅包含确定且明确的信息
- 以特定格式输出关键信息:<summary>• Essential Information:[组织相关信息]</summary>
- 明确要求"Strictly avoid fabricating, inferring, or exaggerating any information"
这种严格约束确保了摘要的忠实度和无幻觉,为后续推理提供了可靠基础。论文特别指出,研究团队"不明确要求摘要工具列出当前信息缺口并提供清晰的行动计划",以避免两种潜在问题:(1)摘要工具可能偏离其主要任务,过度关注信息缺口;(2)强制指定信息缺口可能导致智能体陷入重复自我验证的循环。
值得注意的是,这种设计避免了两种潜在问题:(1)摘要工具可能偏离其主要任务,过度关注信息缺口;(2)强制指定信息缺口可能导致智能体陷入重复自我验证的循环。实验证明,当需要时,摘要工具能够直观且智能地识别信息缺口并提出下一步计划。
为解决这一挑战,研究团队开发了ReSumTool-30B,通过目标导向的专门训练实现了"小模型办大事"的工程智慧。其开发过程基于以下关键洞察:
1. 选择Qwen3-30B-A3B-Thinking作为基础模型,在性能与部署效率间取得平衡
2. 使用SailorFog-QA这一挑战性基准收集⟨对话, 摘要⟩配对数据,确保数据质量
3. 通过监督微调将强大的总结能力蒸馏到较小模型中
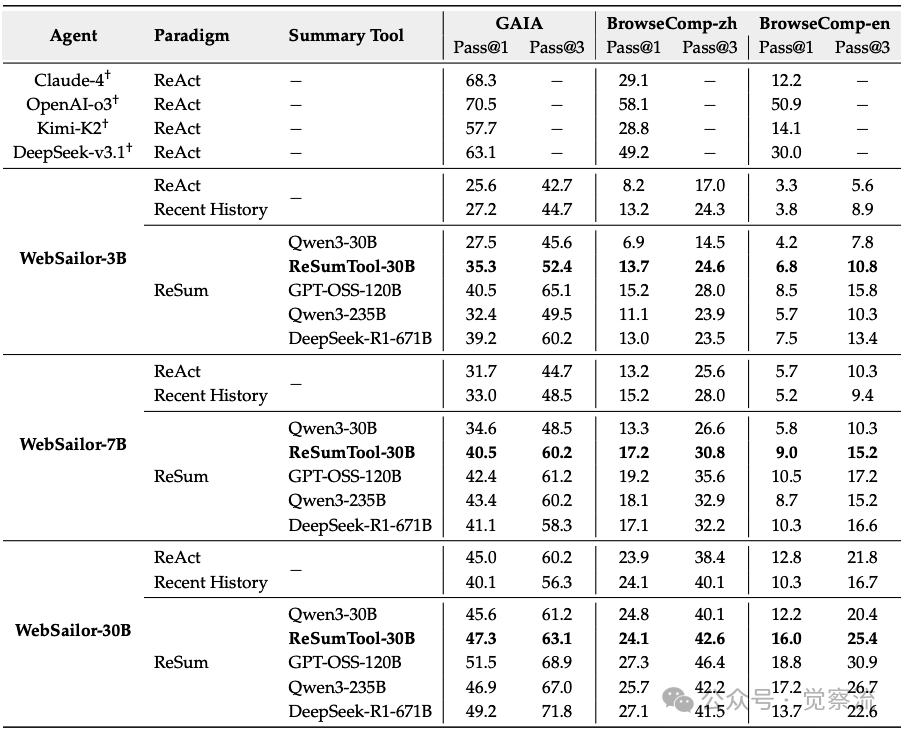
不同范式下训练免费设置的性能比较
如上表所示,ReSumTool-30B在多个基准测试中表现出色。从上表可见,ReSumTool-30B在WebSailor-3B上作为总结工具时,不仅在BrowseComp-zh上达到15.2% Pass@1,更在GAIA基准上实现40.5% Pass@1,远超其基础模型Qwen3-30B(27.5%)。这一差距凸显了专业化训练的价值——通过在任务特定数据上的精细调优,30B规模模型能够充分发挥其潜力,而不仅仅是依赖模型规模。
在BrowseComp-zh上,当作为WebSailor-3B的总结工具时,它实现了15.2%的Pass@1,显著超过Qwen3-235B(11.1%)和DeepSeek-R1-671B(13.0%)。这一结果证明,针对特定任务精细调优的30B规模模型,完全可以超越更大规模的通用模型。
协同进化——ReSum-GRPO自适应学习
ReSum范式创造了一种新型查询q'=(q,s),将原始用户查询q与摘要s结合。这种模式对标准智能体而言是分布外(OOD)数据,因为它们在训练中从未接触过基于摘要的推理。为使智能体掌握这一新范式,研究团队提出了ReSum-GRPO算法,通过强化学习实现范式适应。
与监督微调(SFT)相比,强化学习提供了更优雅的解决方案:SFT需要昂贵的专家级ReSum轨迹数据,且风险覆盖智能体的现有技能;而强化学习允许智能体通过自我进化适应新范式,同时保留其固有推理能力。
ReSum-GRPO的核心创新在于"轨迹分割"和"优势广播"机制:
- 轨迹分割:当总结发生时,ReSum自然将长轨迹分割为多个片段。例如,经历K次总结事件的轨迹被划分为K+1个片段,每个片段形成独立的训练片段
- 优势广播:从最终答案计算单一轨迹级奖励,并在组内归一化为优势值,然后广播到同一轨迹的所有片段
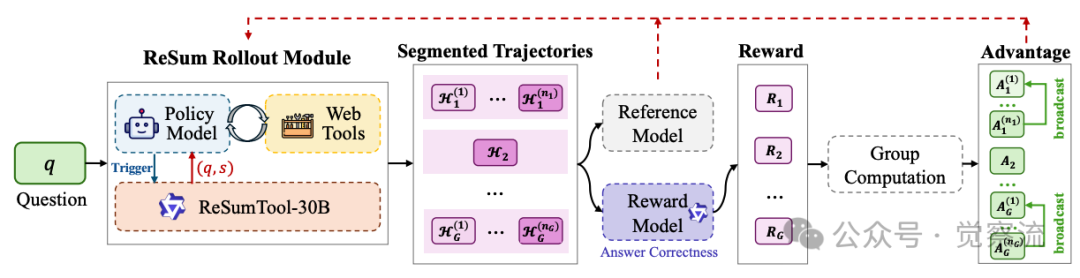
ReSum-GRPO工作机制示意图
如上图所示,ReSum-GRPO通过周期性总结长轨迹并从压缩状态重启,自然形成分段轨迹。系统从最终答案计算单一轨迹级奖励,然后在组内归一化为轨迹级优势值,并广播至同一rollout的所有片段。这种设计使智能体既能有效利用摘要状态进行推理,又能战略性收集有助于生成高质量摘要的信息。
ReSum-GRPO的核心在于其优化目标函数:

这种机制确保了每个决策节点都能接收与整体任务成败相关的反馈信号,有效引导智能体学会如何利用摘要状态继续推理,并主动收集有助于生成高质量摘要的信息。论文明确指出:"ReSum-GRPO不仅鼓励智能体有效利用摘要从压缩状态进行推理,还鼓励其战略性收集能生成高质量摘要的信息。"
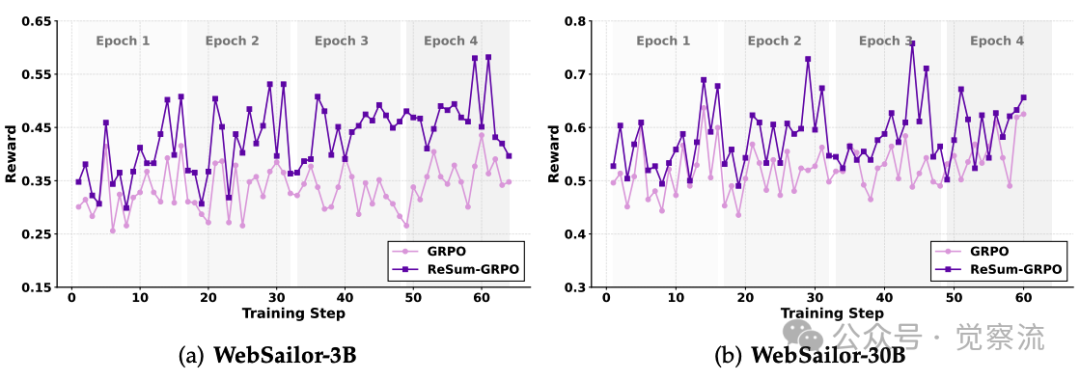
GRPO与ReSum-GRPO的训练动态比较
如上图所示,ReSum-GRPO在训练过程中始终获得比标准GRPO更高的奖励,表明其更有效地鼓励智能体熟悉这一推理模式。这种机制产生双重激励:(1) 有效利用摘要从压缩状态进行推理;(2) 战略性收集能生成高质量摘要的信息。
实证结果令人信服:WebSailor-3B经过ReSum-GRPO训练后,在BrowseComp-zh上的Pass@1从8.2%提升至20.5%。更重要的是,标准GRPO无法使智能体掌握基于摘要的推理——当应用于ReSum范式时,其性能无法显著超过ReSum-GRPO训练的对应体,证明了范式适应的必要性。
实证与启示——数据验证的范式优越性
ReSum的实证力量无需多言。在无需任何训练的情况下,ReSum范式即可为各类智能体带来平均4.5%的绝对性能提升。更令人振奋的是,经过ReSum-GRPO在仅1,000条样本上的轻量训练,WebResummer-30B(即经过ReSum-GRPO训练的WebSailor-30B)在BrowseComp-zh上达到33.3%的Pass@1,在BrowseComp-en上达到18.3%,已超越多个使用万级数据训练的强大开源竞品。
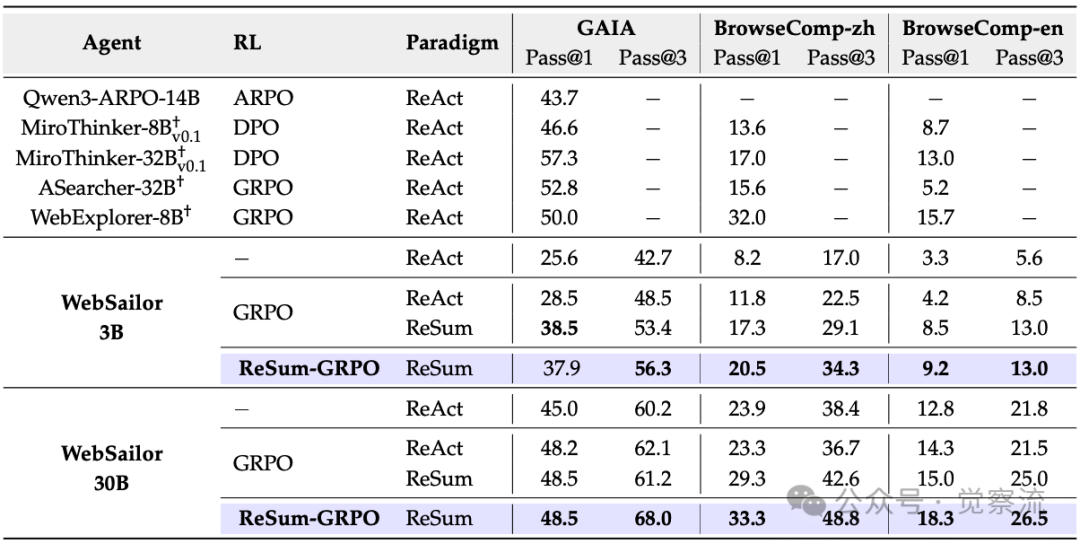
RL算法性能比较
如上表所示,WebSailor-3B经过ReSum-GRPO训练后,在BrowseComp-zh上的Pass@1从8.2%提升至20.5%,提升幅度达150%。相比之下,WebSailor-30B仅从23.9%提升至33.3%,提升幅度约40%。这一现象表明,ReSum对资源受限的小模型具有更大的相对价值——它使小模型能够突破固有局限,实现原本只有大模型才能完成的长程推理任务。
以BrowseComp-en上的一个实际案例为例,当智能体需要回答"跳蚤研究中50%个体的测量值"问题时,ReSum使智能体能够基于摘要状态继续推理。摘要明确指出"C. felis felis的测量值为15.5cm,而C. canis的值未完全提供"后,智能体精准地针对缺失信息进行搜索,最终成功找到13.2cm的答案。这一案例生动展示了ReSum如何使智能体保持对关键信息的追踪,避免在长程推理中迷失方向。
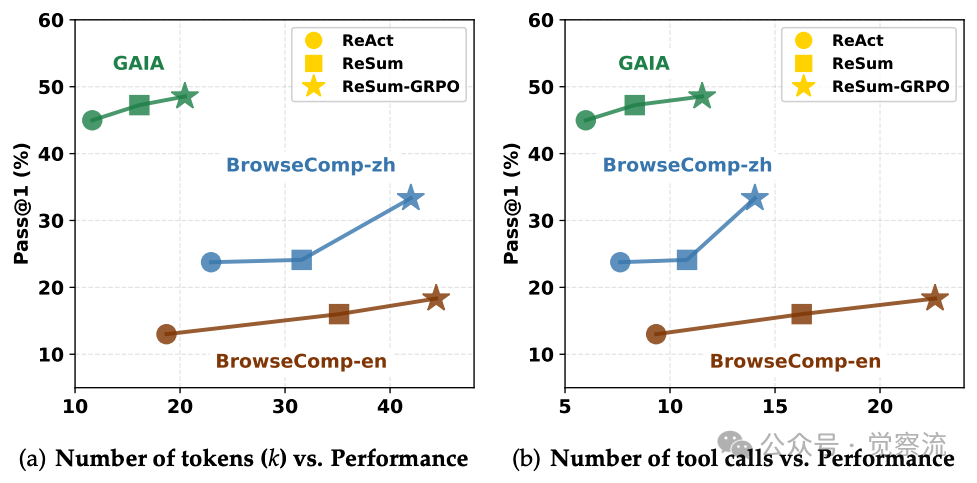
不同范式的资源消耗与性能比较
如上图所示,ReSum范式在合理增加资源消耗的情况下实现了显著的性能提升。在训练免费设置中,ReSum相比ReAct仅略微增加资源成本,但带来明显性能提升;经过ReSum-GRPO训练后,智能体更倾向于依赖摘要进行持续推理,虽然带来额外资源成本,但性能进一步提高。具体而言,ReSum范式通常消耗约2倍的token和工具调用次数,但带来的性能提升远超成本增加,特别是在解决复杂问题时。
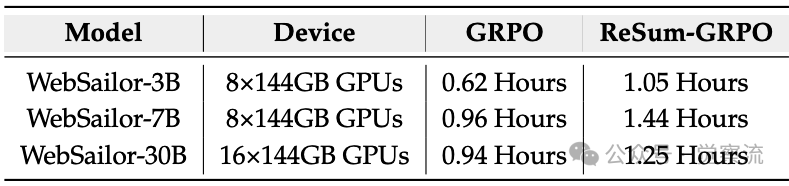
不同RL算法单步训练时间对比
如上表所示,ReSum-GRPO相比GRPO的训练时间增加幅度在33%至69%之间,具体取决于模型规模。WebSailor-3B从0.62小时增至1.05小时(+69%),WebSailor-7B从0.96小时增至1.44小时(+50%),WebSailor-30B从0.94小时增至1.25小时(+33%)。这种增量在获得"无限探索"能力的背景下是可接受的。
ReSum的普适性不仅体现在模型规模上,更体现在其对小模型的"赋能"效应。WebSailor-3B通过ReSum-GRPO训练后,在BrowseComp-zh上Pass@1从8.2%提升至20.5%,提升幅度达150%。相比之下,WebSailor-30B仅从23.9%提升至33.3%,提升幅度约40%。这一现象表明,ReSum对资源受限的小模型具有更大的相对价值——它使小模型能够突破固有局限,实现原本只有大模型才能完成的长程推理任务,有效缩小了小模型与大模型在复杂任务上的性能差距。
关于效率与性能的权衡,ReSum-GRPO的训练时间约为GRPO的1.5倍,这是为获得"无限探索"能力所必须付出的、可接受的代价。在推理阶段,ReSum仅增加约2倍的资源消耗,却能大幅提升解决复杂问题的能力,这种权衡在处理真正复杂的长程任务时显得尤为合理。
总结
ReSum不仅解锁了"长程搜索智能",更揭示了通向更高级智能体的关键路径:真正的智能体必须具备管理自身认知状态的能力。它表明,智能不仅是"反应",更应该是"反思"与"重构"。当智能体能够突破上下文限制,进行真正长程的探索与推理时,它们将能够解决更复杂、更贴近人类认知水平的问题。
ReSum不仅是一项技术改进,也是对智能体本质的重新思考。真正的智能体必须能够管理自身的认知状态,而不仅仅是对输入做出反应。正如人类在复杂问题解决过程中会不断"复盘"和"记笔记",ReSum使LLM智能体具备了类似的元认知能力。这种从"反应式工具"向"战略性思考者"的转变,正是通向AGI的关键一步——当智能体能够自主管理认知状态、持续反思与重构知识时,我们便离真正的"思考伙伴"更近了一步。
尽管ReSum取得了显著成效,其当前实现仍依赖于规则触发(如达到token预算),而非智能体自主判断何时需要总结。研究团队未来将聚焦于使智能体能够智能地自主发起总结调用,消除对基于规则的总结调用的依赖。研究将探索从规则触发(如token上限)到基于不确定性的自主触发的转变,让智能体学会判断何时需要总结,实现更高效的认知管理。
未来研究方向已在论文中清晰展现:
- 智能触发机制:从规则触发(如token上限)到基于不确定性的自主触发,让智能体学会判断何时需要总结,实现更高效的认知管理
- 摘要的可验证性:确保摘要的忠实度和无幻觉,这是保证推理可靠性的关键。论文中已通过严格提示工程(如"Strictly avoid fabricating, inferring, or exaggerating any information")来约束摘要质量
ReSum的高性能也预示着LLM智能体将从"反应式工具"向"战略性思考者"演进。当智能体能够突破上下文限制,进行真正长程的探索与推理时,它们将能够解决更复杂、更贴近人类认知水平的问题。
从ReAct到ReSum,提醒我们,在追求更大规模模型的同时,优化推理范式同样能带来质的飞跃。当智能体学会"总结过去、重启未来",它们离真正的自主智能又近了一步。


