
引言
在 RAG系列:基于 DeepSeek + Chroma + LangChain 开发一个简单 RAG 系统 中,我们搭建了一个基础版的 RAG 系统,实现了文档解析和切分 -> 文档向量化存储 -> 用户输入问题 -> 根据问题检索相关知识 -> 将检索到的知识和原问题重新组合成 prompt -> 最后 LLM 根据增强后的 prompt 给出答案。
构造一个基础版的 RAG 系统是非常简单的,借助 LangChain 等框架可快速搭建出完整流程,代码也不会很多,但基础版的问答效果往往比较差,无法直接在实际业务中应用。
在 RAG系列:一文让你由浅到深搞懂RAG实现 中,我们将 RAG 系统主要分为问题理解、检索召回以及答案生成这三个模块。
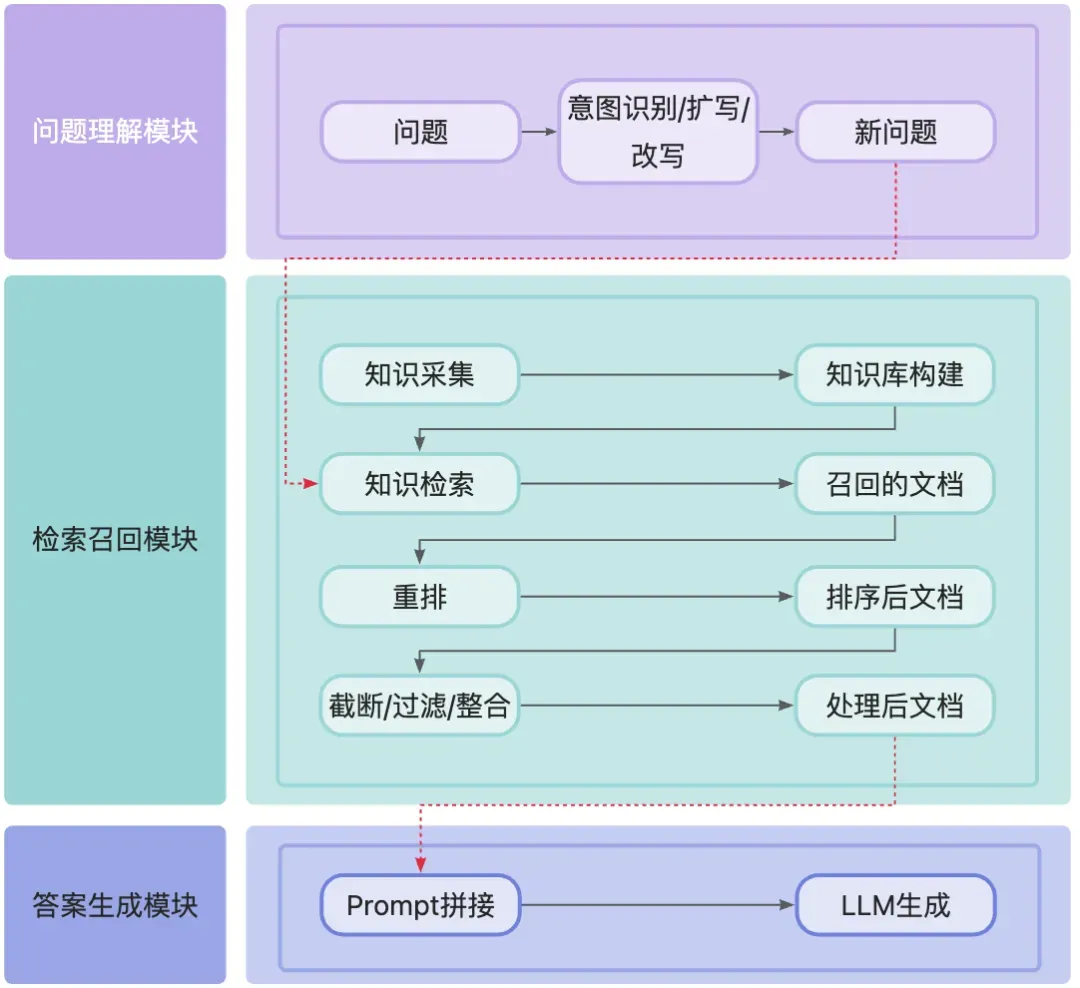
要做出一个问答效果更好的 RAG 系统,往往需要结合实际业务场景对这三个模块进行独立优化。
下面这张图是 OpenAI 介绍的 RAG 优化经验,这个准确率随不同的数据集会有不同,但基本上优化后的准确率比优化前有显著提升这个基本上是一致的。
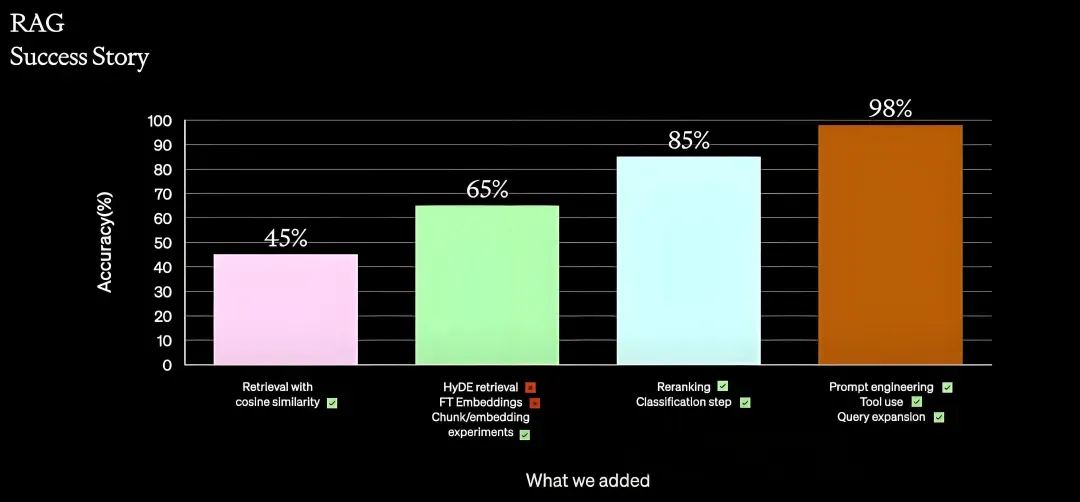
RAG 系统的问答效果是好还是坏是需要经过评估的,而评估就需要高质量的 QA 测试数据集,所谓的 QA 测试数据集,就是一份包含“问题-回答”的测试数据集合。部分系统(如客服系统)是有这方面数据的,但绝大多数情况下是没有的,这时就需要首先构造一批问答数据,这是后续对每一步优化进行验证的基础。
本文将会使用多鲸教育研究院所发布的《2024少儿编程教育行业发展趋势报告》作为文档来构造 QA 测试数据集 ,后续也会围绕针对这个文档的问答效果优化展开。
本文使用通过 ollama 部署 qwen2.5:14b 模型来对《2024少儿编程教育行业发展趋势报告》这个文档进行 QA 测试数据集的构造和质检。
QA 测试数据集构造包含如下3个步骤:
- 文档解析与切分:这部分就是对文档进行解析和切分;
- 文档片段 QA 构造:这部分就是让 LLM 根据文档片段构造 QA;
- QA 质量打分:这部分就是让 LLM 再次对构造的 QA 进行质量评估。
QA 测试数据集已经构造好放在代码库里,大家可以直接使用:
https://github.com/laixiangran/ai-learn/blob/main/src/app/data/qa\_test.xlsx
本文的代码地址:
https://github.com/laixiangran/ai-learn/blob/main/src/app/rag/02\_qa\_extraction/route.ts
下面分步骤讲解下代码实现:
文档解析和切分
这一步做了一个巧妙的设计,就是将每个文档生成一个 uuid,这个 uuid 后续会作为元数据存到向量数据库中,也会和 QA 测试数据集绑定在一起,这样后续在验证检索效果的时候,就可以知道这个问题是否检索到正确的哪个文档。
复制// 文件解析
const loader = newPDFLoader(
'src/app/data/2024少儿编程教育行业发展趋势报告.pdf',
{
splitPages: false,
}
);
const docs = await loader.load();
// 文件切分
const textSplitter = newRecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 50,
});
const texts = await textSplitter.splitDocuments(docs);
texts.forEach((text) => {
// 给每个文档生成uuid
text.metadata.uuid = uuidv4();
});
// 文档持久化
const baseTextPath = 'src/app/data/doc_base.xlsx';
awaitsaveToExcel(
texts.map((text) => {
return {
doc: JSON.stringify(text),
};
}),
baseTextPath
);LLM 进行 QA 构造
这一步通过 LLM 进行 QA 构造,然后将构造好的 QA 与原始文档和原始文档 uuid 进行绑定。
复制// 读取切分后的文档
const baseTextData = awaitreadFromExcel(baseTextPath);
baseTextData.forEach((text) => {
text.doc = JSON.parse(text.doc);
});
// QA 数据集抽取
const allData = [];
const errorData = [];
const baseQaPath = `src/app/data/qa_base.xlsx`;
const errorTextPath = `src/app/data/doc_error.xlsx`;
// 本地资源有限,因此单个处理完再处理下一个
while (baseTextData.length > 0) {
const baseText = baseTextData[0];
try {
const { pageContent: document, metadata } = baseText.doc;
const prompt = `
我会给你一段文本,你需要阅读这段文本,分别针对这段文本生成8个问题、用户回答这个问题的上下文,和基于上下文对问题的回答。
说明:
1. 问题要与这段文本相关,不要询问类似“这个问题的答案在哪一章”这样的问题;
2. 上下文必须与原始文本的内容保持一致,不要进行缩写、扩写、改写、摘要、替换词语等;
3. 答案请保持完整且简洁,无须重复问题。答案要能够独立回答问题,而不是引用现有的章节、页码等;
4. 返回结果以JSON形式组织,格式为[{"question": "...", "context": ..., "answer": "..."}, ...];
5. 如果当前文本主要是目录,或者是一些人名、地址、电子邮箱等没有办法生成有意义的问题时,可以返回[]。
文本:
${document}
回答:
`;
const ollamaLLM = initOllamaLLM();
const res = await ollamaLLM.invoke(prompt);
const regex = newRegExp('\\[(.*?)\\]', 's');
const match = res.content.match(regex);
if (match) {
const data = JSON.parse(`[${match[1]}]`);
data.forEach((item) => {
item.doc = document; // 保留原始文档
item.uuid = metadata.uuid; // 保留原始文档 uuid
});
allData.push(data);
// 保存QA数据集
awaitsaveToExcel(allData.flat(), baseQaPath);
baseTextData.shift();
}
} catch (error) {
console.log('error', error);
errorData.push({ doc: JSON.stringify(baseText.doc) });
awaitsaveToExcel(errorData, errorTextPath);
baseTextData.shift();
}
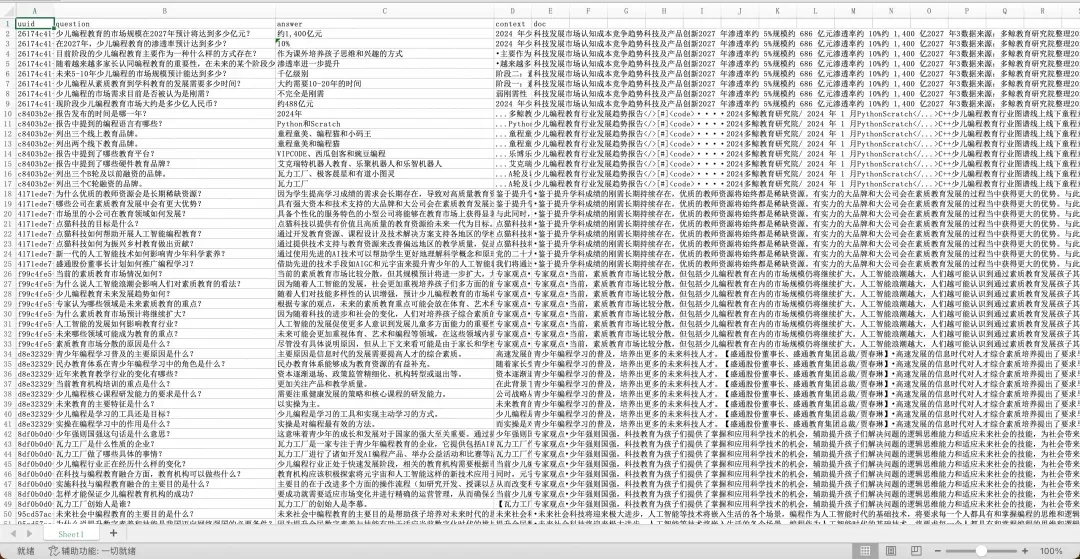
}QA 构造样例如下:
LLM 进行 QA 质检
这一步通过 LLM 进行 QA 质量检查,给每个问题和答案进行打分(1-5分),并给出打分的理由。
复制// QA 数据集质量检查
const checkQaPath = 'src/app/data/qa_grade.xlsx';
const baseQaData = awaitreadFromExcel(baseQaPath);
const allQas = [];
while (baseQaData.length > 0) {
const baseQa = baseQaData[0];
const prompt = `
你是一个优秀的教师,你的任务是根据问题和参考答案来进行打分。
说明:
1. 你需要根据所出的问题以及参考答案进行打分,并给出打分理由,分值是一个int类型的值,取值范围为1-5;
2. 好的问题,应该是询问事实、观点等,而不是类似于“这一段描述了什么”;
3. 好的答案,应该能够直接回答问题,而不是给出在原文中的引用,例如“在第3页中”等;
4. 结果请以JSON形式组织,格式为如下:{"score": ..., "reason": ...}。
问题:
${baseQa.question}
参考答案:
${baseQa.answer}
请打分:
`;
const ollamaLLM = initOllamaLLM();
const res = await ollamaLLM.invoke(prompt);
const regex = newRegExp('\\{(.*?)\\}', 's');
const match = res.content.match(regex);
if (match) {
const data = JSON.parse(`{${match[1]}}`);
// 保存QA数据集
allQas.push({ ...baseQa, ...data });
awaitsaveToExcel(allQas, checkQaPath);
}
baseQaData.shift();
}QA 质检样例如下:

QA 测试数据集构造
这一步从大于 3 分的记录中随机挑选 100 条数据作为后续的 QA 测试数据集。
复制// 筛选出分数大于3的记录并分为测试数据集和训练集
const data = awaitreadFromExcel(checkQaPath);
const testData = [];
const trainData = [];
data.forEach((item, i: number) => {
if (item.score > 3) {
if (i % 2 === 0 && testData.length < 100) {
testData.push(item);
} else {
trainData.push(item);
}
}
});
saveToExcel(testData, 'src/app/data/qa_test.xlsx');
saveToExcel(trainData, 'src/app/data/qa_train.xlsx');QA 测试数据集样例如下:

至此,QA 测试数据集就构造完成,后续 RAG 系统的全链路效果以及各个模块的优化效果,都将基于这个 QA 测试数据集进行。


