OpenAI o3的多轮视觉推理,有开源平替版了。
并且,与先前局限于1-2轮对话的视觉语言模型(VLM)不同,它在训练限制轮数只有6轮的情况下,测试阶段能将思考轮数扩展到数十轮。
 图片
图片
这个模型叫Mini-o3,它无需消耗大量训练周期资源,通过恰当的数据、初始化方法和强化学习微调,即可实现长周期视觉搜索能力。由字节、香港大学团队联合开发。
 图片
图片
跨越数十个步骤的深度推理
最近的多模态大模型虽然能通过”图像工具+强化学习”处理视觉问题,但现有开源方案存在很大的短板:
比如推理方式单调、交互轮次受限、遇到需要反复试错的复杂任务就束手无策。
而Mini-o3突破了上述局限——它能够进行长达数十个步骤的深度多轮推理,在高难度视觉搜索任务中达到了当前最佳水平。
 图片
图片
这得益于它的三个关键设计:
- 第一,研究团队构建了视觉探测数据集VisualProbe,包含数千个专为探索式推理设计的视觉搜索难题;
- 第二,开发了迭代式数据收集流程,让模型能学会深度优先搜索、试错探索、目标维持等多样化推理策略;
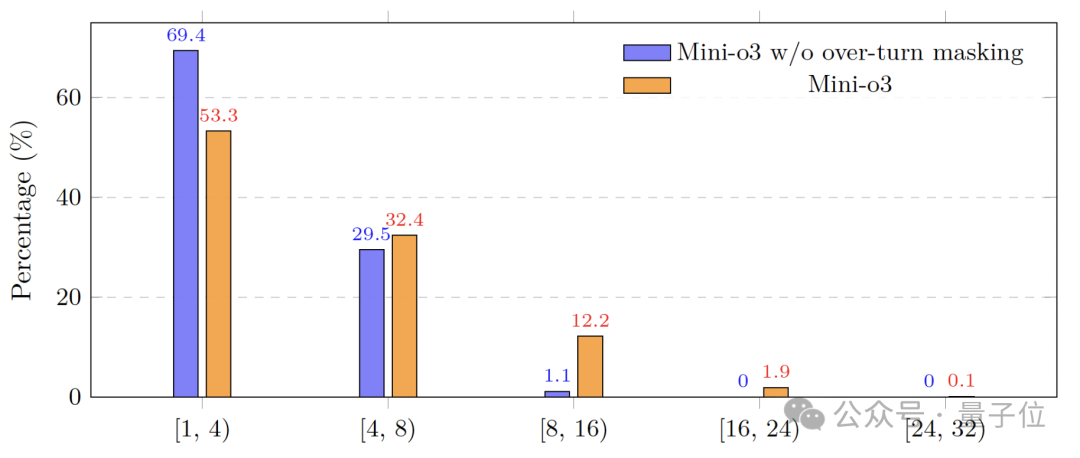
- 第三,提出超轮次掩码策略,在强化学习中避免对达到最大交互轮次的响应进行惩罚,从而平衡训练效率与测试时的扩展性。
 图片
图片
训练Mini-o3包括以下两个阶段:
阶段一:冷启动监督微调 (SFT)
为了处理复杂的探索性任务,研究团队采用冷启动SFT来激活多轮工具使用能力。
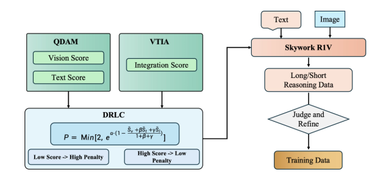
冷启动数据收集流程如下图所示。
 图片
图片
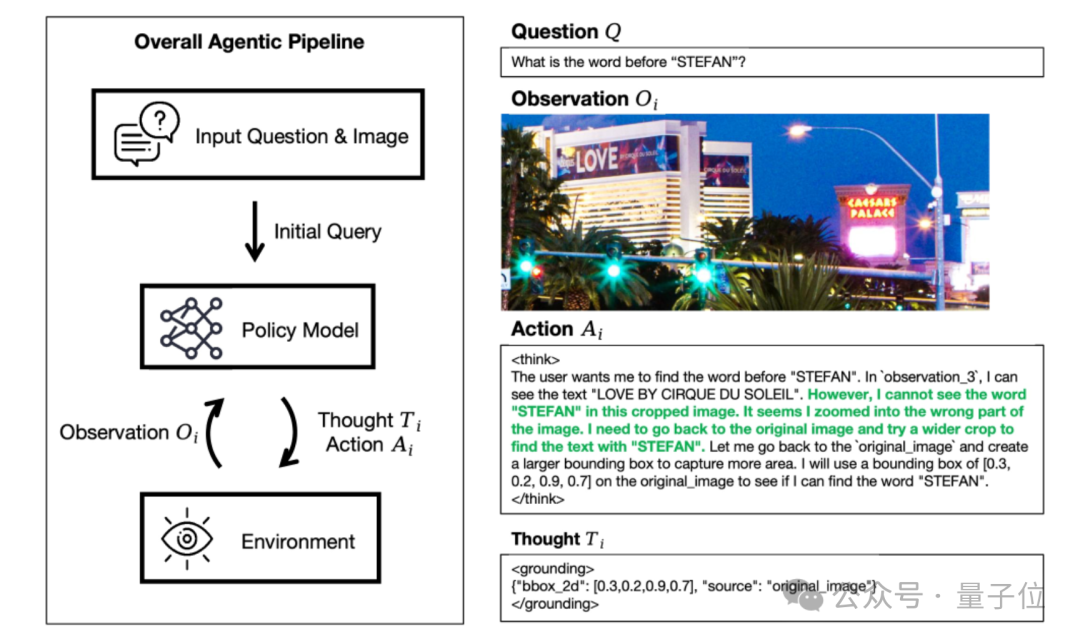
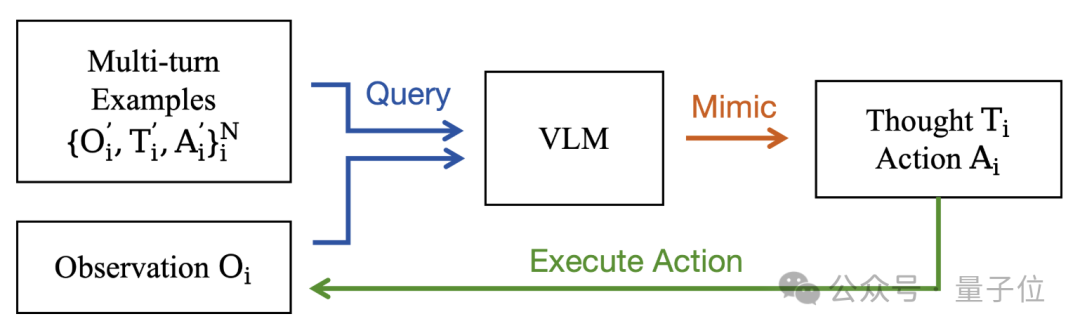
为生成高质量、多样化的多轮推理轨迹,研究团队选取少量人工构建的示范样本,通过上下文学习方式提示现有VLM进行模仿。
该模型被要求逐轮迭代生成“思考-行动”对,直到输出最终答案或达到预设轮次上限。
研究团队仅保留最终答案正确的轨迹,通过这套流程从6个示范样本中收集了约6000条冷启动推理轨迹。
阶段二:强化学习 (RL)
首先,降低最大像素限制。基础模型的上下文长度被限制在3.2万token,当默认图像预算约为1200万像素时,可允许的交互轮次会因上下文限制而大幅减少,这阻碍了模型在困难任务上进行试错探索。
为提高单次任务中的可行交互轮次,研究团队将每张图像的最大像素限制降至200万(必要时可进一步降低)。
这一简单调整使得相同上下文容量内可容纳更多交互轮次,从而提升长周期问题的解决率。
其次,加入超轮次掩码机制。
在原始GRPO设置中,每个问题【q】会被输入策略模型以生成一组输出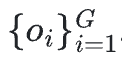 。系统随后根据回答正确性计算奖励值【r】。
。系统随后根据回答正确性计算奖励值【r】。
研究团队通过奖励归一化计算优势值【A】,并在小批量数据上使用GRPO优化目标更新策略。
在该策略的实现中,未加入KL散度或熵正则化项。形式化优化目标表示为: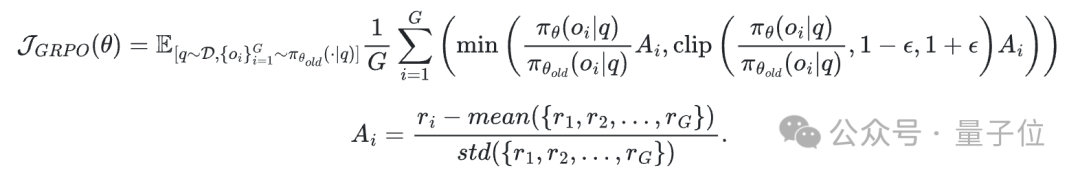
需要注意的是,当响应达到最大交互轮次或超出上下文长度限制时,奖励值会被设为【0】,此类情况下无法产生有效答案,会导致归一化后产生负优势值。
这类响应在整个训练过程中应该受到惩罚和抑制,但又存在两个明显问题:
 图片
图片
首先,超长响应的正确性本质上是未知的——直接的惩罚会给回报信号注入标签噪声,可能导致训练过程不稳定;
其次,为了控制训练成本,训练时的轮次限制必须保持在较低水平(通常不到10轮),这就导致超长回答频繁出现(训练初期甚至超过20%)。
在这种情况下,简单粗暴的惩罚会使模型过早给出答案,大幅减少交互回合数。使得高难度任务难以处理,并严重限制了测试时扩展的潜力。
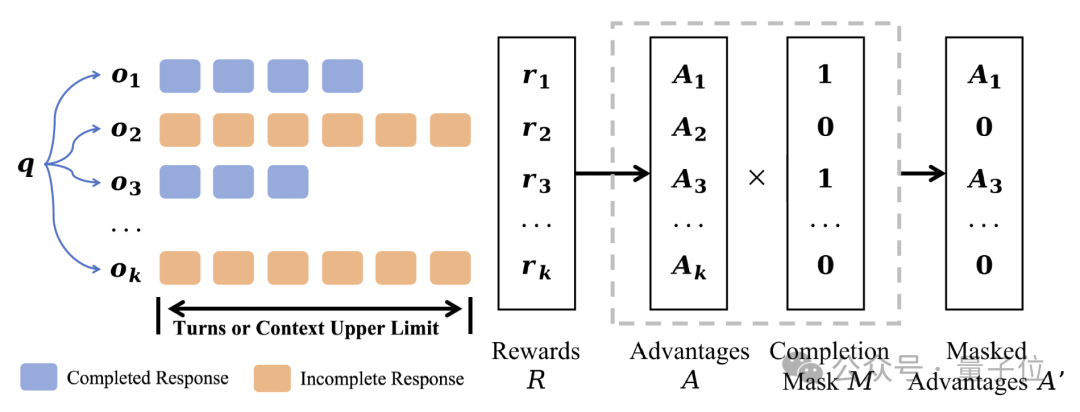 图片
图片
为了防止模型陷入“尽早给出答案”的策略,研究团队提出了一种超轮次掩码技术,目标是不惩罚超长回复。整体流程如上图所示。
具体来说,除了在标准GRPO中定义的奖励【r】和优势【A】之外,研究团队引入了一个完成掩码【M】,用于指示回复是否成功终止。然后计算掩码后的优势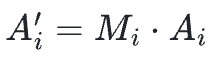 ,使得超长轨迹不会贡献负向学习信号。
,使得超长轨迹不会贡献负向学习信号。
基于标准GRPO的改进目标总结如下,公式中的变化用红色标出。

由于某些响应不完整,研究团队通过完成的生成数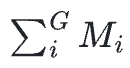 来归一化目标,而不是通过总生成数【G】。
来归一化目标,而不是通过总生成数【G】。
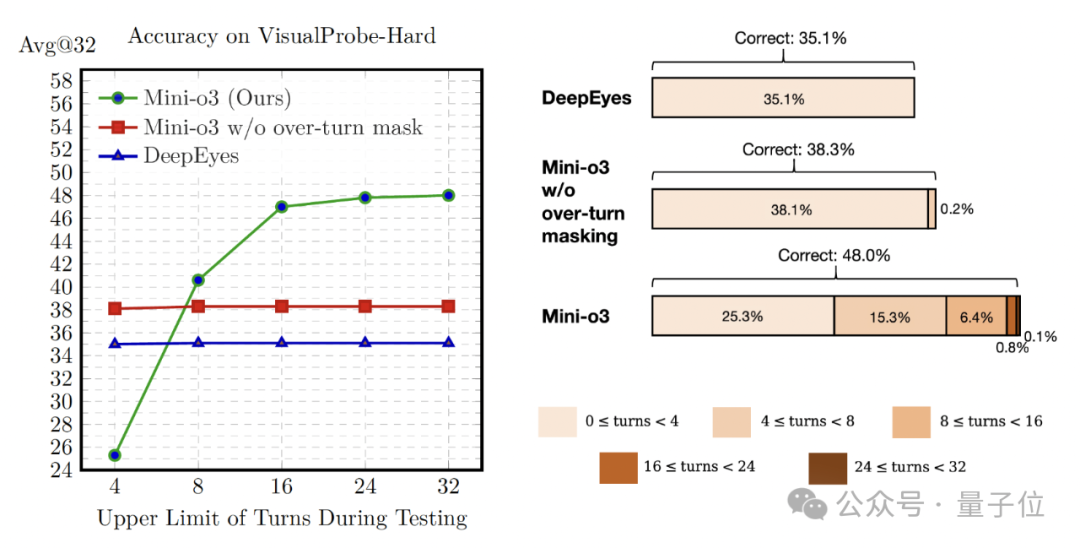
值得注意的是,尽管训练时设置了较小的轮次上限,但测试时的推理轨迹能延伸至数十轮,且准确率持续提升。
超轮次掩码技术对于实现测试时交互轮次扩展的优势至关重要。
 图片
图片
此外,由于构建高难度实例对促进RL中的反思性试错推理至关重要,研究团队还创建了一个具有挑战性的视觉搜索数据集——VisualProbe。
该数据集包含4,000个训练用视觉问答对和500个测试用问答对,涵盖简单、中等、困难三个难度级别。
与现有视觉搜索基准相比,VisualProbe的突出特点是:
- 小目标
- 众多干扰物体
- 高分辨率图像
这些特性使得任务大大更具挑战性,并自然地要求迭代探索和试错。
无需消耗大量训练周期资源
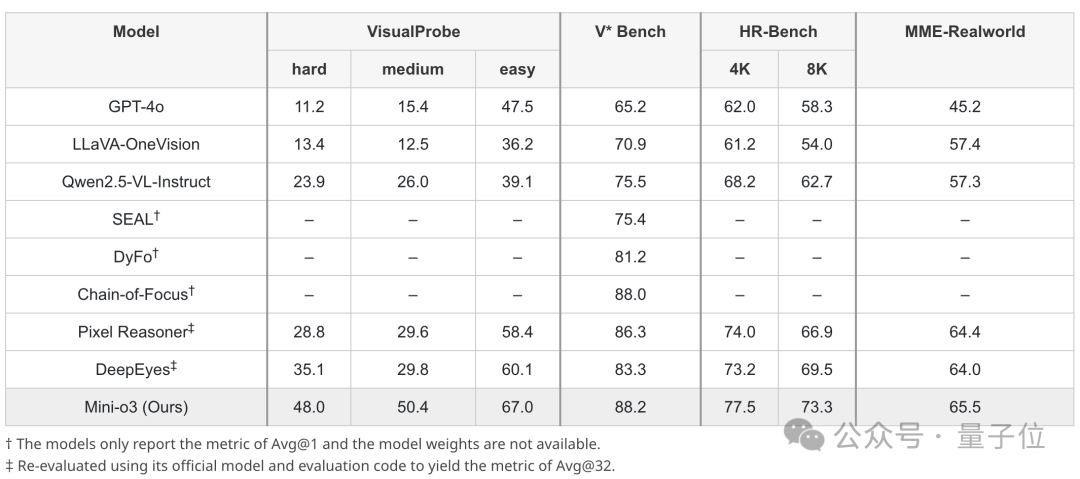 图片
图片
上表为现有模型和Mini-o3在视觉搜索任务上的性能比较,所有列出的模型大小均为7B。
为确保评估的稳健性和说服力,研究团队在VisualProbe、V*Bench和HR-Bench上评估所有模型。在所有数据集上,Mini-o3均实现了最先进的性能,显著优于其他开源基线。
研究团队将这些提升归因于Mini-o3能够维持更复杂和更深的推理轨迹。
 图片
图片
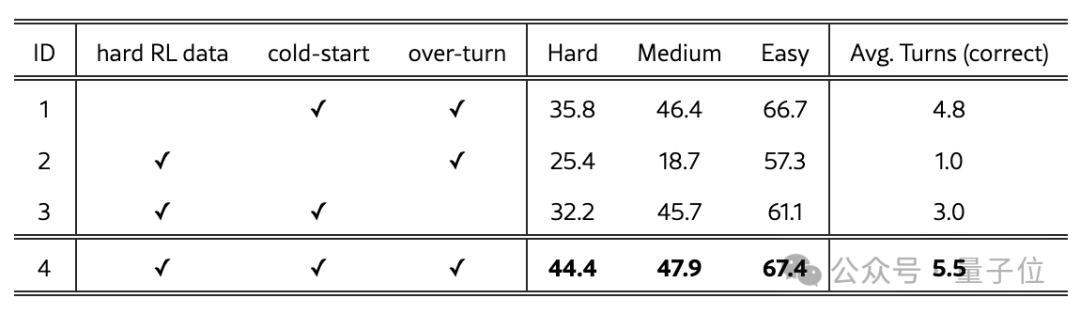
在消融实验中,上表的实验1和实验4显示,移除RL数据导致模型在VisualProbe-Hard上的性能下降约8.6分,表明具有挑战性的RL样本对于鼓励复杂的推理轨迹至关重要。
上表的实验2和实验4表明,冷启动SFT对于多轮工具使用至关重要:没有它,性能会崩溃。
研究团队认为,基础模型在预训练或指令微调阶段缺乏多轮自主推理轨迹的学习,而冷启动SFT为此提供了关键的基础能力初始化。
上表的实验3和实验4表明,超轮次掩码技术能有效提升RL效果,尤其在多轮交互场景中优势显著。
超轮次掩码技术的核心价值体现在两方面:首先,通过避免对正确性未知的截断响应进行错误惩罚,有效稳定了训练过程;其次,该技术实现了测试时的轮次扩展能力,使模型能够解决那些所需轮次远超训练上限的高难度任务,从而释放出强劲性能。
 图片
图片
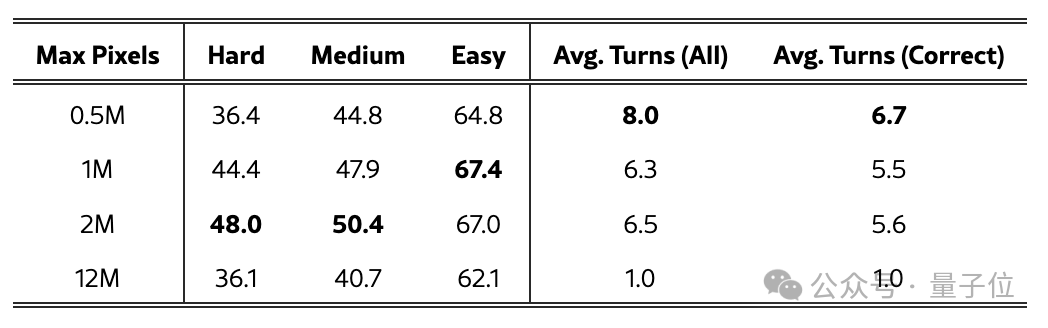
上表评估了不同最大像素预算的效果。结果显示,预算值过大或过小都会导致性能下降:过大的预算会引发提前终止现象,减少交互轮次并限制迭代优化;而过小的预算则会增加感知幻觉。
研究团队在同表中记录了平均交互轮次数值,这揭示了感知精度与交互深度之间的权衡关系。通过合理调整最大像素预算,才能实现最佳的整体性能。
 图片
图片
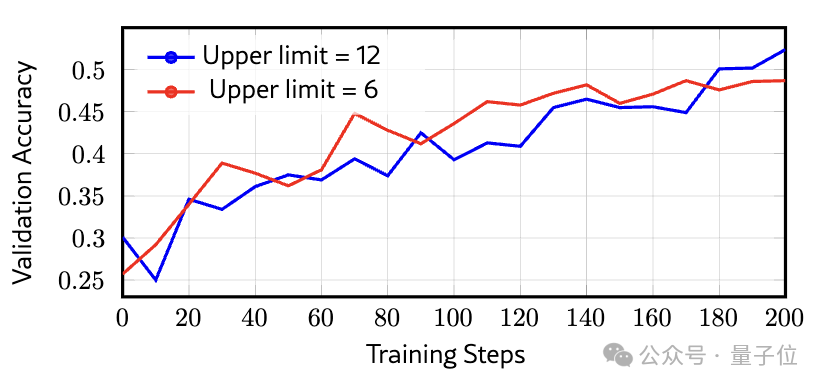
为了直观展示增加训练轮次的效果,研究团队对比了6轮交互上限和12轮交互上限在VisualProbe-Hard数据集上的准确率。结果显示:较低轮次上限(6轮)在初期进步更快,但训练约150步后就会停滞不前;而较高轮次上限(12轮)虽然前期学习速度较慢,最终却能达到更优异的性能水平。
简单地说,Mini-o3能够生成多样化的推理模式与深度思维链,其推理轨迹可扩展至数十个交互轮次,且准确率随轮次增加持续提升,在多个视觉搜索基准测试中显著超越现有模型。
研究人员表示,Mini-o3的技术方案能为多轮交互式多模态模型的开发与强化学习应用提供实用指导。
相关代码已全部开源。
作者团队
本次研究团队作者一共6人。
分别是:赖昕(Xin Lai)、Junyi Li、Wei Li、Tao Liu、Tianjian Li、赵恒爽(Hengshuang Zhao,通讯作者)。
其中赖昕和Junyi Li是Mini-o3项目的共同一作。

赖昕是字节跳动的研究员,研究方向为大型多模态模型。他本科就读于哈尔滨工业大学,后于2024年在香港中文大学获得博士学位。

博士期间,他作为第一作者参与的Step-DPO项目在MATH和GSM8K分别获得了70.8%和94.0%的准确率;LISA项目在GitHub上得到超过1.5k(现2.4k)星标。
另一位作者,Junyi Li公开资料不多,目前是香港大学的博士,参与字节研究工作,曾就读于华中科技大学。
公开资料显示,他作为第一作者的PartGLEE项目被ECCV2024接收。
参考链接:https://x.com/gm8xx8/status/1965616579024228527
权重/设置: https://huggingface.co/
Mini-o3仓库:https://github.com/Mini-o3/
Mini-o3论文: https://arxiv.org/abs/2509.07969