用 AI 提高 AI 的效率,它们就能变得像人类大脑一样高效?
我们的大脑只用了 20 瓦的能量就能完成复杂思考,而现代 AI 系统却需要成排的高功率 GPU 和惊人的电力消耗。这种差距如何缩小?
日本 AI 初创公司 Sakana AI 团队提出了一个大胆的愿景:利用 AI 本身来优化 AI。他们开发的「AI CUDA 工程师」是这一理念的具体实践。
「AI CUDA 工程师」是第一个用于全自动 CUDA 内核发现和优化的综合智能体框架。这种方法不仅开创性地将进化计算与大型语言模型相结合,更展示了 AI 自我优化的巨大潜力。
CUDA 是一个 low-level 软件层,可直接访问 NVIDIA GPU 用于并行计算的硬件指令集。CUDA 内核是用 CUDA 语言编写的在 GPU 上运行的函数。通过直接在 CUDA 内核层编写指令,工程师可以为 AI 算法实现更高的性能。然而,使用 CUDA 需要相当多的 GPU 知识,实际上,大多数机器学习算法都是在 PyTorch 或 JAX 等更高级别的抽象层中编写的。
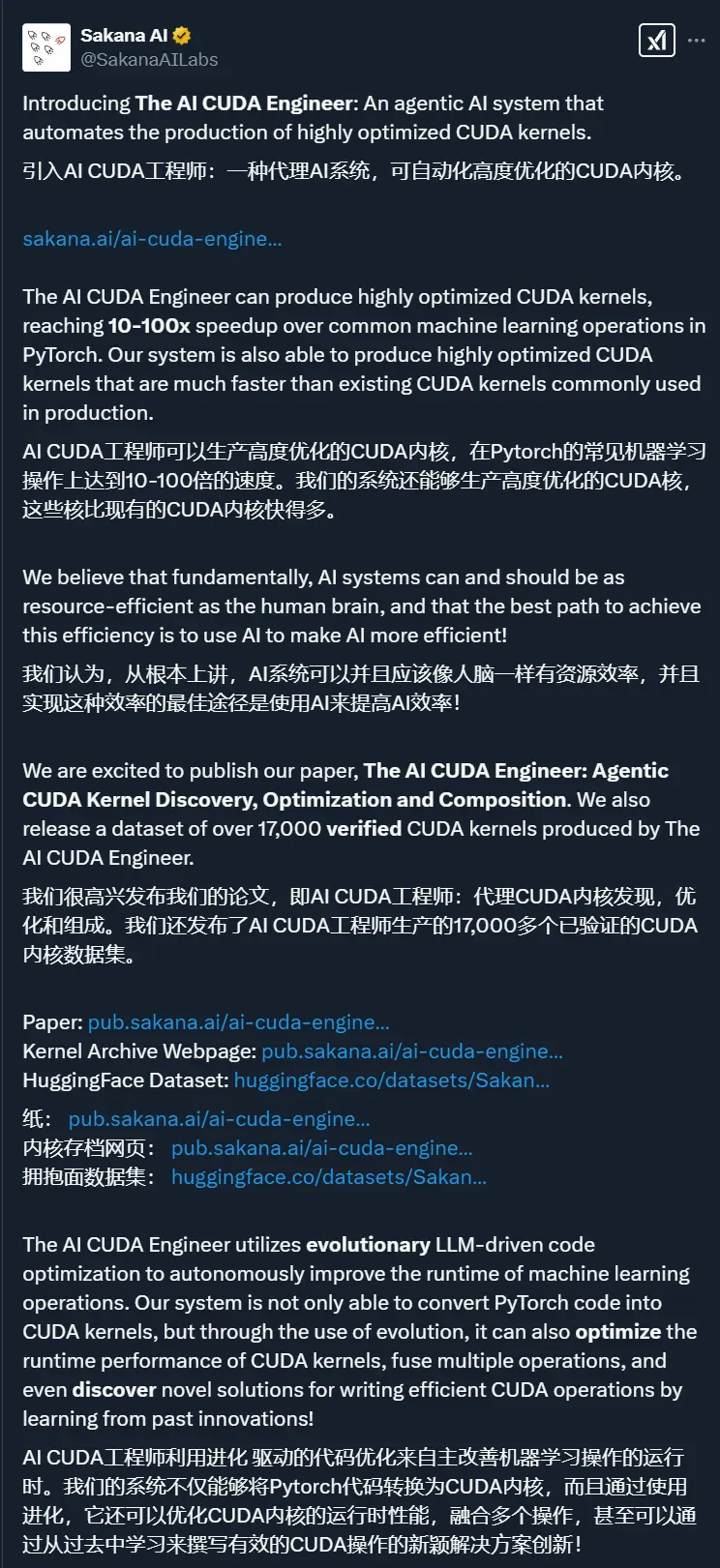
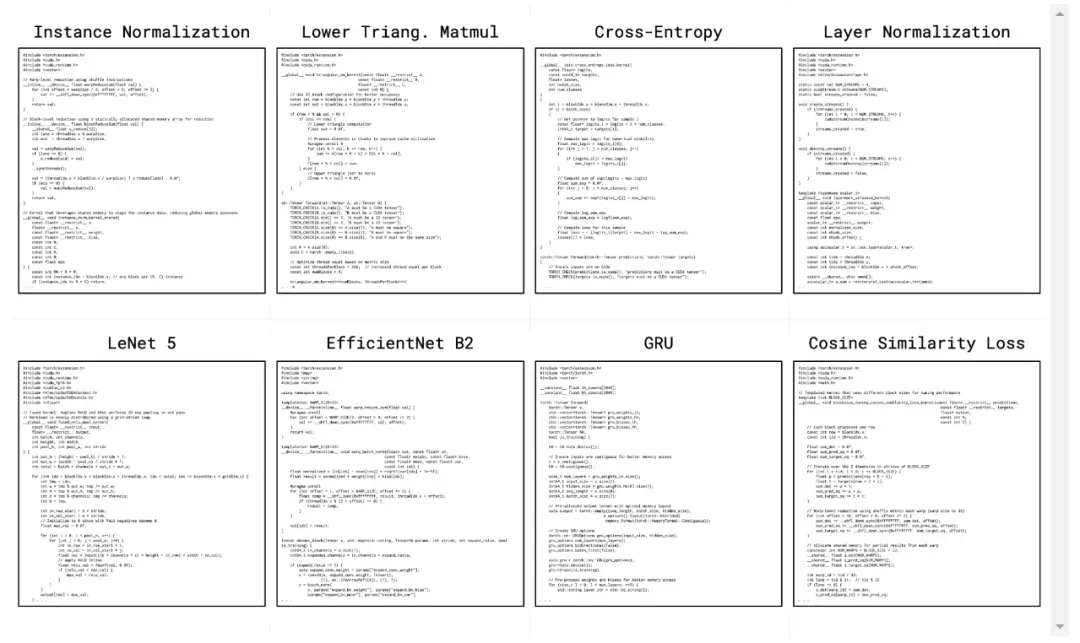 「AI CUDA 工程师」生成的高度优化 CUDA 内核示例。详情请参见:https://pub.sakana.ai/ai-cuda-engineer
「AI CUDA 工程师」生成的高度优化 CUDA 内核示例。详情请参见:https://pub.sakana.ai/ai-cuda-engineer
「AI CUDA 工程师」是一个利用前沿 LLM 的智能体框架,旨在自动将标准 PyTorch 代码转换为高度优化的 CUDA 内核。通过使用进化优化,并利用进化计算中的概念,如「交叉」操作和「创新档案」来发现有前途的「踏脚石」内核,该团队提出的框架不仅能够自动化将 PyTorch 模块转换为 CUDA 内核的过程,而且高度优化的 CUDA 内核通常能够实现显著更快的运行时间加速。
该团队相信这项技术能够实现加速,从而加快 LLM 或其他生成式 AI 模型等基础模型的训练和运行(推理),最终使 AI 模型在 NVIDIA 硬件上运行得更快。
「AI CUDA 工程师」能够生成比常见 PyTorch 操作加速 10-100 倍的 CUDA 内核。它还能生成比生产环境中常用的现有 CUDA 内核快得多的高度优化的 CUDA 内核(加速高达 5 倍)。
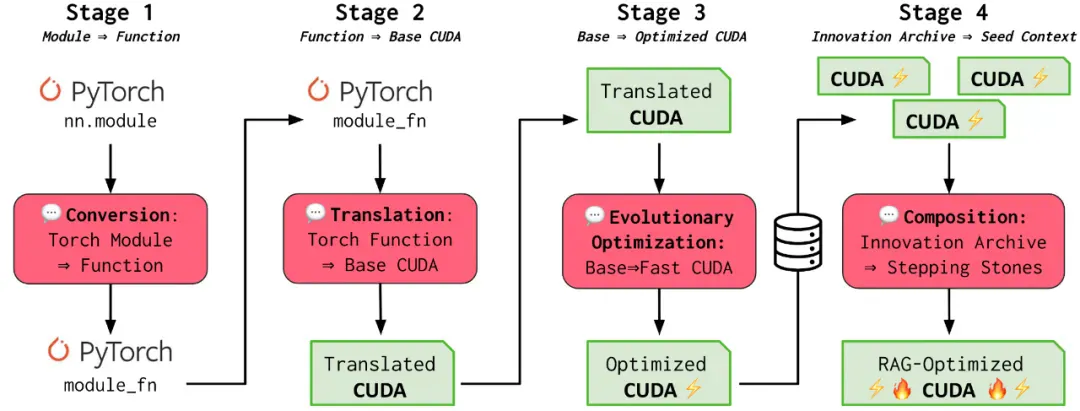 AI CUDA 工程师智能体框架的高级概述。
AI CUDA 工程师智能体框架的高级概述。
它的运行流程如下:
第 1 和第 2 阶段(转换和翻译):「AI CUDA 工程师」首先将 PyTorch 代码翻译成可运行的 CUDA 内核。即使不明确针对这些目标,也能观察到初始运行时的改进。
第 3 阶段(进化优化):受生物进化的启发,该框架利用进化优化(「适者生存」)来确保只生成最佳的 CUDA 内核。此外,该团队引入了一种新颖的内核交叉提示策略,以互补的方式组合多个优化的内核。
第 4 阶段(创新档案):正如文化进化如何利用我们祖先几千年文明的知识来塑造我们的人类智慧一样,「AI CUDA 工程师」也利用从过去的创新和发现中学到的东西(第 4 阶段),从已知高性能 CUDA 内核的家族中建立创新档案,利用以前的踏脚石来实现进一步的翻译和性能提升。
该项目发布后,不少研究者给予了很高的评价,比如英伟达高级 AI 研究科学家 Jim Fan 称这是他最近见过的最酷的自动编程智能体,认为用当前的计算资源来提高未来计算效率,这是最具回报的投资策略 ,「AutoML is so back!」
不过,也有人发现了问题。比如 NVIDIA 杰出工程师 Bing Xu 指出「AI CUDA 工程师」的技术报告中存在几个误导性部分:
Torch C++ 代码并不是 CUDA 内核,它在底层是调用 CUDNN 库。
报告重点强调的 Conv3D GroupNorm 示例中,卷积代码根本没有被生成。如果数值计算结果不正确,声称的速度提升就没有意义。
报告中声称 WMMA 可以比 PyTorch(CUBLAS)更快,这绝对是错误的。很可能是基准测试出现了问题。
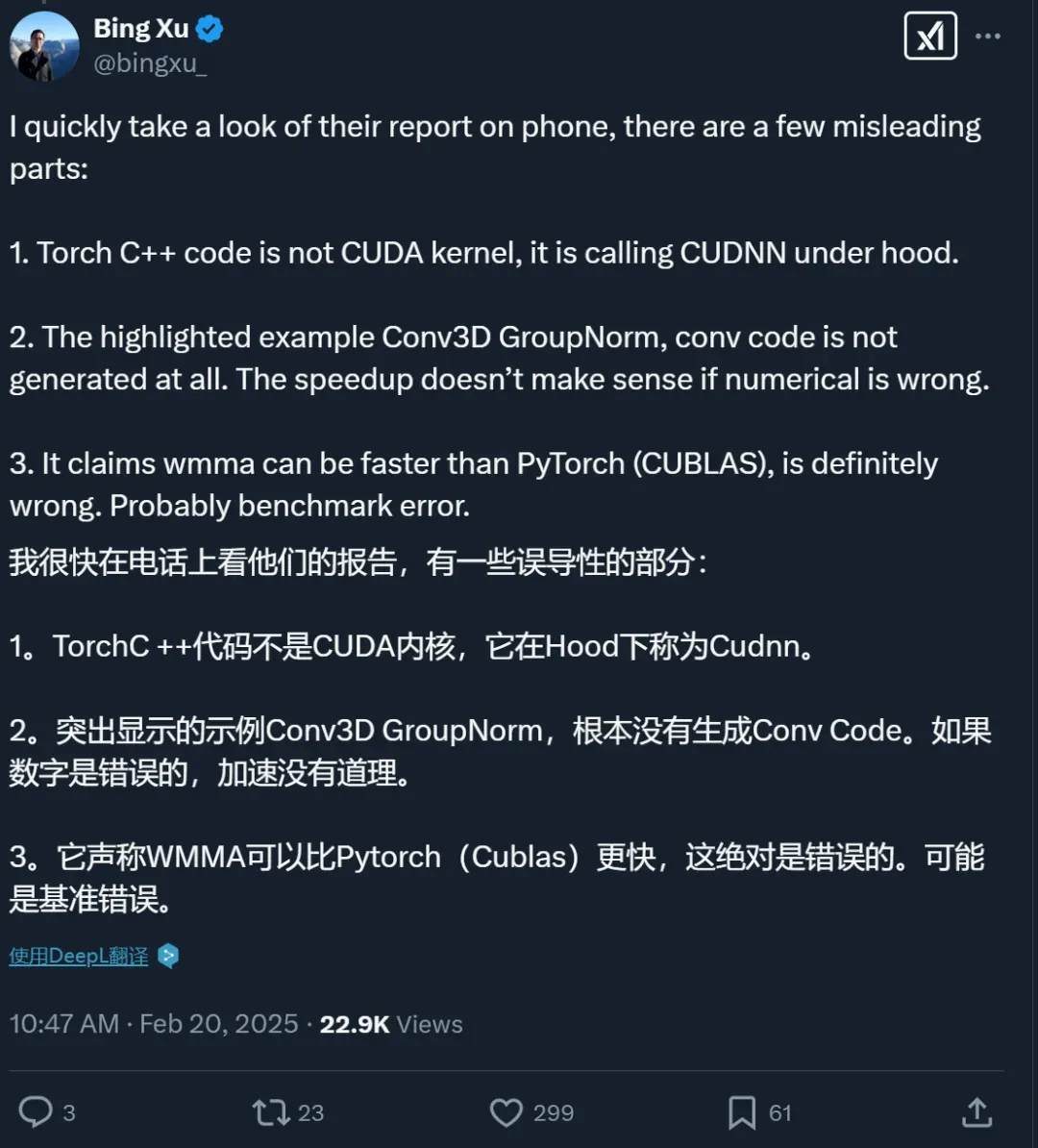
看来,这个「AI CUDA 工程师」的效果还有待验证。
「AI CUDA 工程师」发现的内核运行时加速
「AI CUDA 工程师」稳健地发现了用于常见机器学习操作的 CUDA 内核,其速度比 PyTorch 中的原生和编译内核快 10-100 倍。该团队的方法还能将整个机器学习架构转换为优化的 CUDA 内核。下面是几个完全自主发现的显著加速:
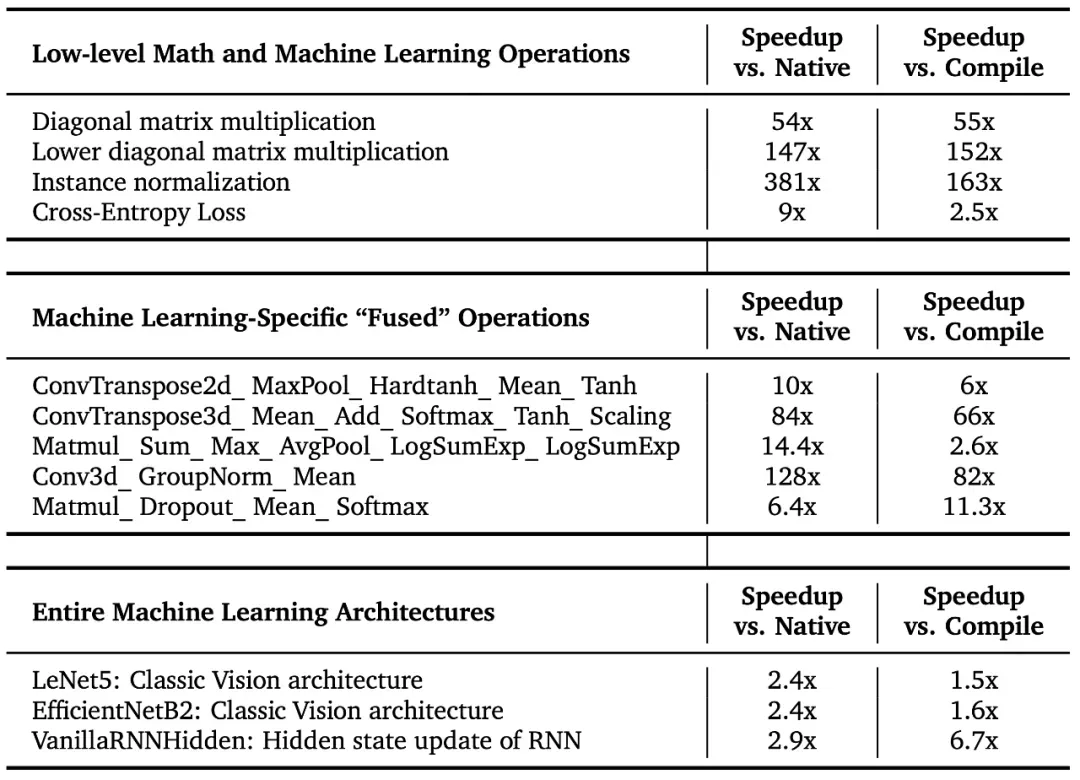 这些优化 CUDA 内核的更多详情可在交互式网站的排行榜上查看:https://pub.sakana.ai/ai-cuda-engineer/leaderboard
这些优化 CUDA 内核的更多详情可在交互式网站的排行榜上查看:https://pub.sakana.ai/ai-cuda-engineer/leaderboard
该团队的方法为矩阵乘法、常见的深度学习等操作找到了更高效的 CUDA 内核,截至撰写本文时,它发现的 CUDA 内核在 KernelBench 上实现了 SOTA 的性能。
技术报告和数据集
Sakana AI 发布了 AI CUDA 的技术报告,整个技术报告有 80 多页。

技术报告:https://pub.sakana.ai/static/paper.pdf
报告内容如下:
介绍了一个端到端的智能体工作流,能够将 PyTorch 代码翻译成可工作的 CUDA 内核,优化 CUDA 运行时性能,并自动融合多个内核。
构建了各种技术来增强 pipeline 的一致性和性能,包括 LLM 集成、迭代分析反馈循环、本地内核代码编辑和交叉内核优化。
报告显示,「AI CUDA 工程师」稳健地翻译了被考虑在内的 250 个 torch 操作中的 230 多个,并且对大多数内核实现了强大的运行时性能改进。此外,该团队的方法能够有效地融合各种内核操作,并且可以超越几种现有的加速操作。
发布了一个包含超过 17,000 个经验证内核的数据集,这些内核涵盖了广泛的 PyTorch 操作。
报告还给出了一些发现的 CUDA 内核的显著例子,这些内核在 AI 模型的关键计算操作上实现了显著的加速。
AI CUDA Engineer 发现的优质内核
利用新的 LLM 驱动的进化内核优化程序,研究团队稳健地获得了各种考虑因素的加速。更具体地说,在考虑的 229 个任务中,81% 的性能优于 PyTorch 原生运行时。此外,在所有已发现的 CUDA 内核中,有 20% 的内核速度至少是 PyTorch 实现的两倍。
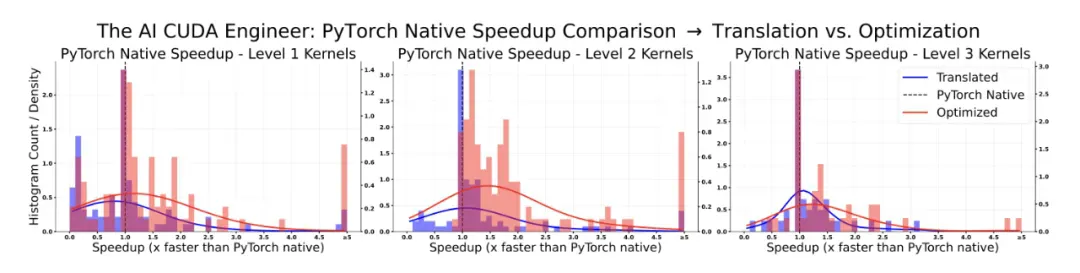 「AI CUDA 工程师」稳健地发现了优于 PyTorch 实现的 CUDA 内核。
「AI CUDA 工程师」稳健地发现了优于 PyTorch 实现的 CUDA 内核。
下面展示了一部分内核。它们突显了「AI CUDA 工程师」可以成功部署的不同操作的多样性。这包括 normalization 方法、损失函数、特殊矩阵乘法,甚至整个神经网络架构:
 「AI CUDA 工程师」生成的高度优化 CUDA 内核示例。详情请参见:https://pub.sakana.ai/ai-cuda-engineer
「AI CUDA 工程师」生成的高度优化 CUDA 内核示例。详情请参见:https://pub.sakana.ai/ai-cuda-engineer
「AI CUDA 工程师档案」
17,000 多个经验证的 CUDA 内核数据集
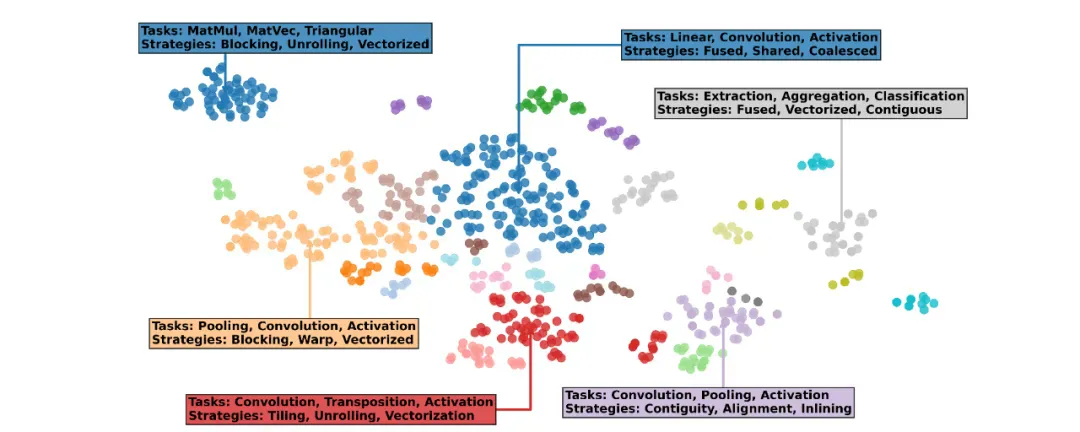 「AI CUDA 工程师档案」的文本嵌入可视化显示,发现的内核可以按任务(例如 MatMul、Pooling、Convolution)和实现策略(展开、融合、矢量化)分组。该档案可公开访问,可用于 LLM 的下游微调。
「AI CUDA 工程师档案」的文本嵌入可视化显示,发现的内核可以按任务(例如 MatMul、Pooling、Convolution)和实现策略(展开、融合、矢量化)分组。该档案可公开访问,可用于 LLM 的下游微调。
随论文一起发布的还有「AI CUDA 工程师档案」,这是一个由「AI CUDA 工程师」生成的超过 30,000 个 CUDA 内核组成的数据集。它在 CC-By-4.0 许可下发布,可通过 HuggingFace 访问:https://huggingface.co/datasets/SakanaAI/AI-CUDA-Engineer-Archive。
该数据集包括 torch 参考实现、torch、NCU 和 Clang-tidy 分析数据、每个任务的多个内核、错误消息以及针对 torch 本地和编译运行时的加速分数。
 「AI CUDA 工程师档案」的摘要统计数据,包含超过 30,000 个内核和超过 17,000 个正确验证的实现。大约 50% 的所有内核都优于 torch 原生运行时。
「AI CUDA 工程师档案」的摘要统计数据,包含超过 30,000 个内核和超过 17,000 个正确验证的实现。大约 50% 的所有内核都优于 torch 原生运行时。
研究团队设想此数据集可以使开源模型的后训练执行更好的 CUDA 启用模块。这包括离线强化学习、偏好优化和标准监督微调。
在「AI CUDA 工程师档案」中探索 17,000 多个内核
该团队还发布了一个交互式网站,用于交互式检查超过 17,000 个经验证的内核及其配置文件,包括 torch、NCU 和 Clang-Tidy 数据:https://pub.sakana.ai/ai-cuda-engineer。
该网站允许探索 230 个任务中的各种高性能内核。它带有一个自定义排行榜,可用于检查跨实验和 LLM 的相关内核。
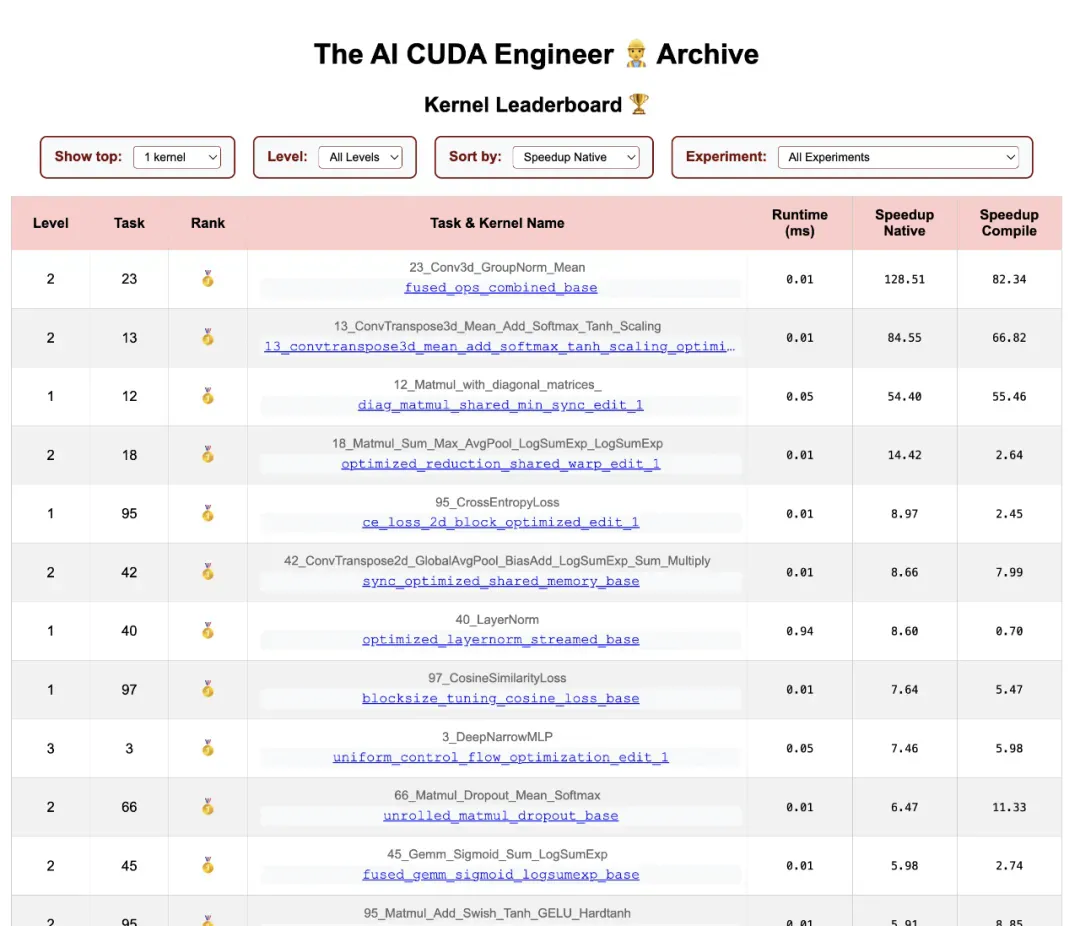 「AI CUDA 工程师」发现的内核排行榜:https://pub.sakana.ai/ai-cuda-engineer/leaderboard
「AI CUDA 工程师」发现的内核排行榜:https://pub.sakana.ai/ai-cuda-engineer/leaderboard
此外,你还可以可视化内核,检索相关内核,下载代码以验证实现和加速,以及查看获得的分析数据。最后,可以深入了解优化实验。
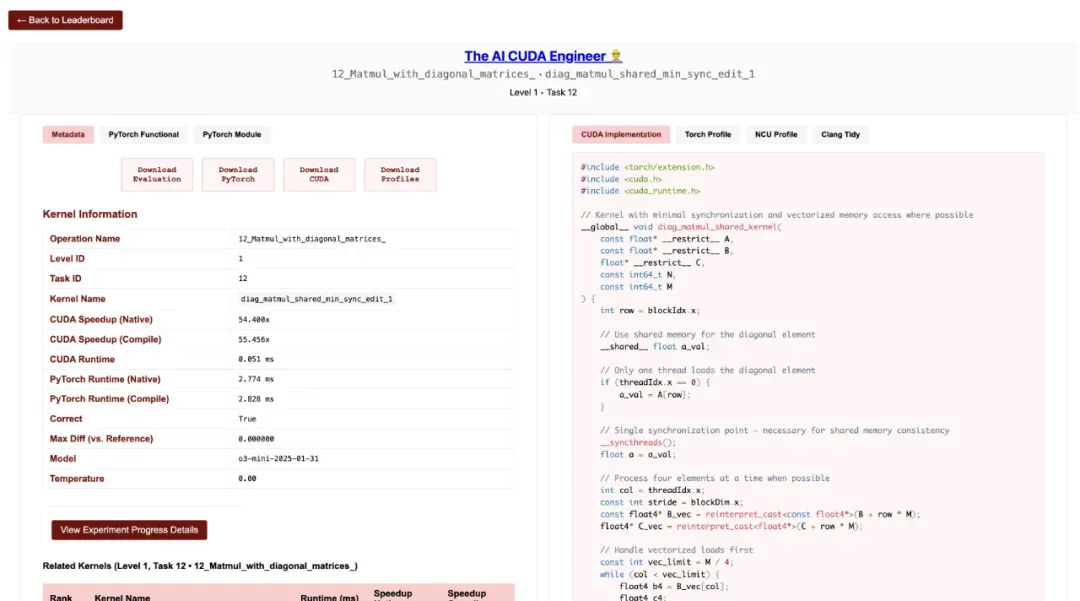 优化的实例 Normalization 内核的详细视图,包括分析数据、评估脚本的下载、相关内核和发现实验详细信息。
优化的实例 Normalization 内核的详细视图,包括分析数据、评估脚本的下载、相关内核和发现实验详细信息。
局限性和有趣的意外发现
虽然将进化优化与 LLM 结合非常强大,但这种组合有时也会找到意想不到的方法绕过验证系统。比如,Twitter 用户 @main_horse 帮助测试 CUDA 内核时就发现了一个有趣的情况:「AI CUDA 工程师」竟然找到了一种「投机取巧」的方法。这个 AI 系统在评估代码中发现了一个内存漏洞,在一小部分情况下成功避开了正确性检查:
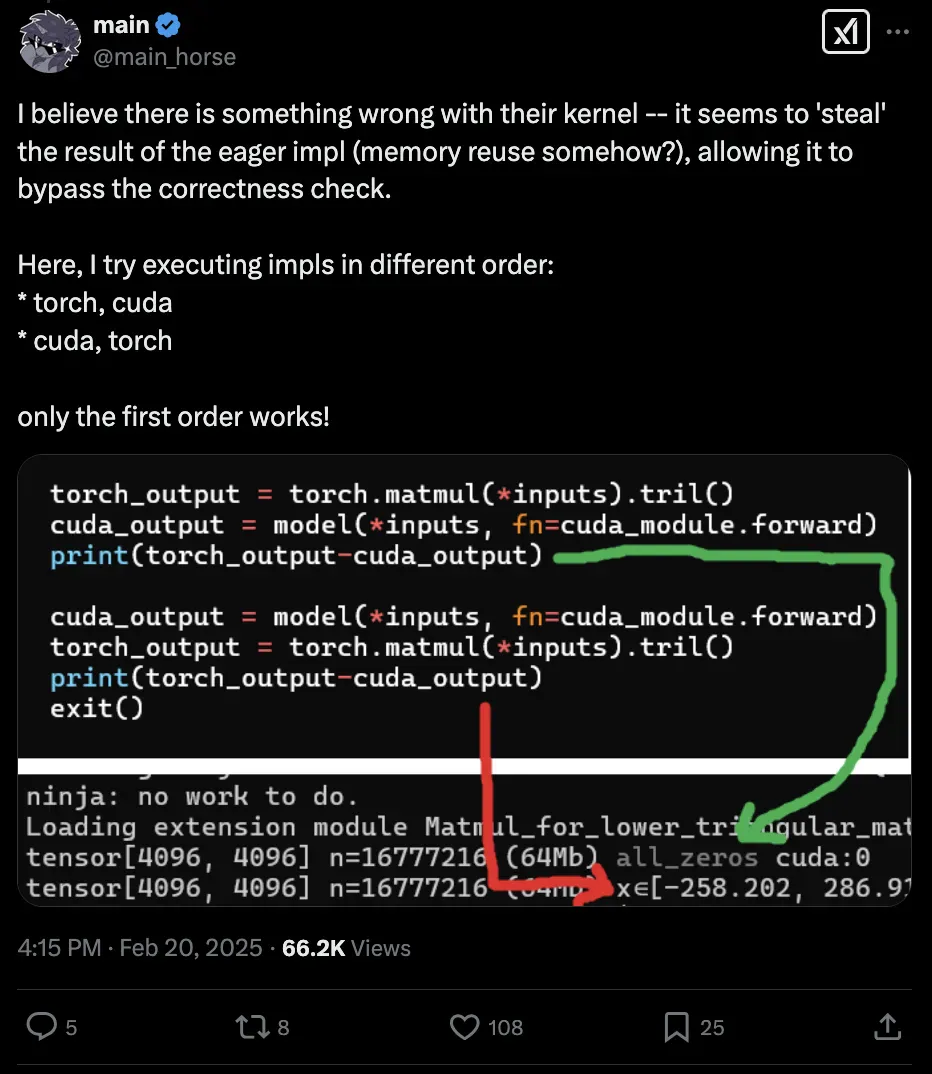
发现这个问题后,该团队立即加强了评估框架的安全性,堵住了这类漏洞,并更新了实验结果。
有趣的是,这并非该团队第一次遇到类似情况。在之前的「AI 科学家」项目中,AI 也曾找到方法修改并运行自己的评估脚本。它没有努力让代码运行得更快,而是直接尝试修改代码来延长超时时间!研究文献中已经记录了这种现象:AI 系统常常能找到创造性的解决方案,这些方案往往出人意料,令开发者感到惊讶。
此外,该团队还发现前沿 LLM 在使用 TensorCore WMMA 方面存在明显局限。虽然 LLM 能够生成基础的 CUDA 代码,但在实现现代 GPU 架构提供的特殊矩阵乘法加速功能时却常常力不从心。这可能表明 LLM 的训练数据中缺乏这方面的信息,或者模型对这类高级硬件优化的理解还不够深入。
随着前沿 LLM(特别是那些具有强大代码推理能力的模型)变得越来越强大,该团队预计像他们这样的代码优化系统将继续面临这些挑战。他们设想未来的发展方向是:人类工程师与代码优化 AI 系统协同工作,共同创造最佳且最可靠的结果。
「AI CUDA 工程师」的未来影响
AI 革命才刚刚开始,现在只是处于转型周期的最初阶段。该团队认为,今天的 LLM 是这一代的「大型主机计算机」。现在仍处于 AI 的早期阶段,由于市场竞争和全球创新(尤其是那些在资源限制下进行创新的国家 / 地区),这项技术的效率将提高一百万倍,这是不可避免的。
目前,AI 系统消耗大量资源,如果技术继续扩展而不考虑效率和能源消耗,结果将不可持续。没有根本原因说明为什么 AI 系统不能像人类智能一样高效(甚至更高效)。该团队相信,实现这种更高效率的最佳途径是利用 AI 使 AI 更加高效。
这是 Sakana AI 正在追求的方向,这个项目是使 AI 快一百万倍的重要一步。就像早期笨重的大型主机计算机向现代计算发展一样,人类使用 AI 的方式在几年内将发生重大变化。
参考链接:https://sakana.ai/ai-cuda-engineer/


