智能时代,企业数据每日剧增。员工寻找答案的效率直接影响工作流程,StackOverflow调查表明54%的开发者因等待问题答案而工作中断。信息就在那里,却被深埋在企业资源迷宫中。
检索增强生成(RAG)技术为企业级知识管理带来希望。但RAG系统的魔力不在于语言模型本身,而在于底层数据存储方案的选择。
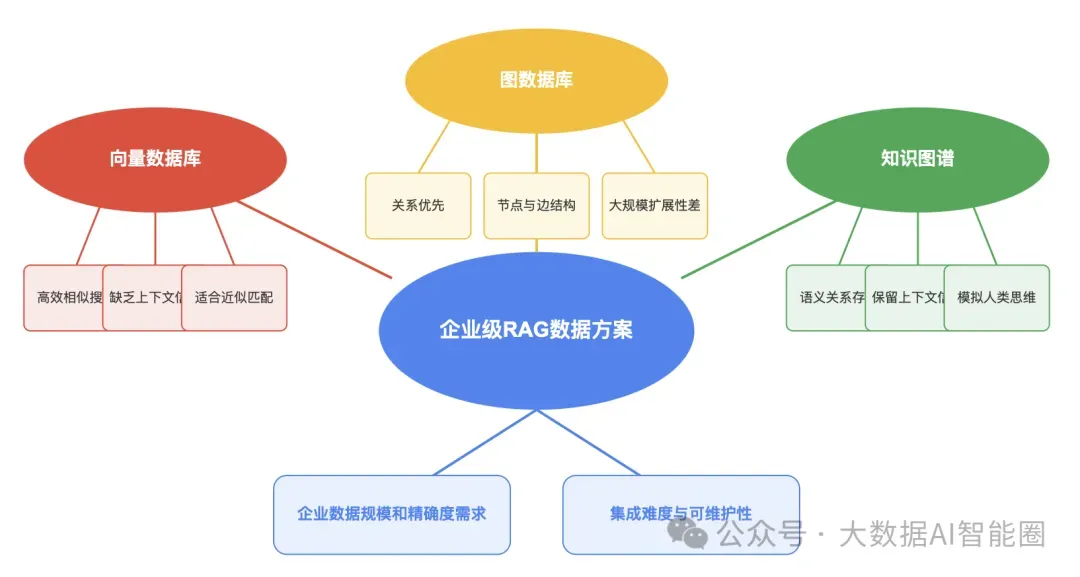
向量数据库:高效但易失语境
向量数据库将文档分割成100至200字符的文本块,通过嵌入模型转换为数值向量存储。
搜索时,用户查询同样被转换为向量,系统使用KNN或ANN算法找出最相似向量。
这种方案在处理大规模语义相似性搜索时表现出色,支持多种数据类型存储。
你问"Apple的市值是多少?",系统能找到语义相关内容,即使没有关键词完全匹配。
矛盾点在于数据分块过程会丢失上下文信息。"Apple于1976年4月1日成立,1984年推出了Macintosh"这段信息被分块后,用户询问"Apple何时推出第一台Macintosh?"可能得到"1983年"这一错误答案。
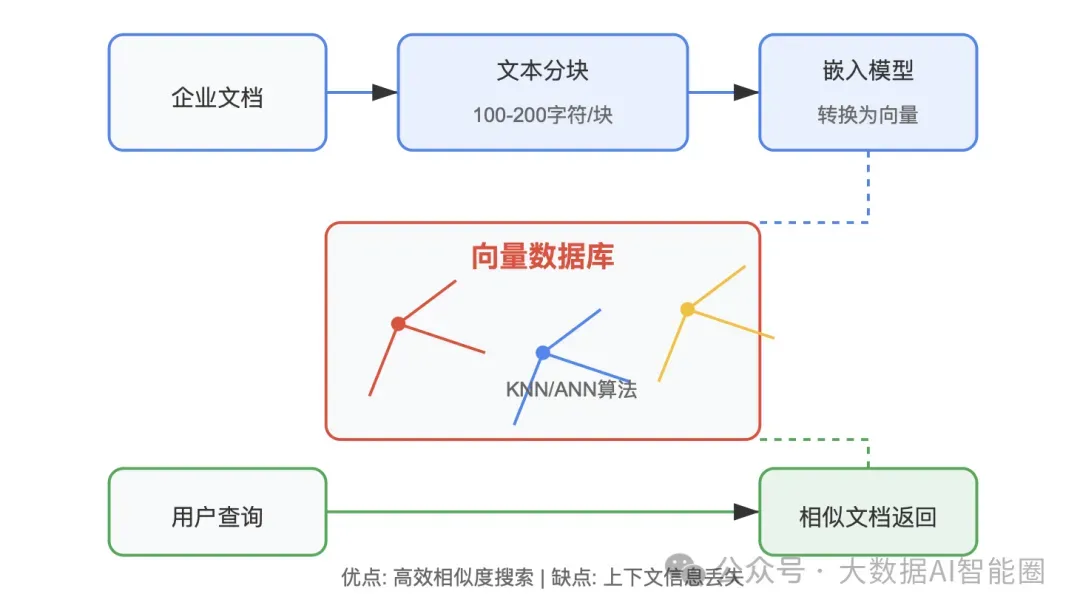
企业环境中,向量数据库面临的挑战更为突出:数据规模增长导致KNN算法效率下降,需持续更新整个数据集,运维成本激增。
图数据库与知识图谱:关系网络的力量
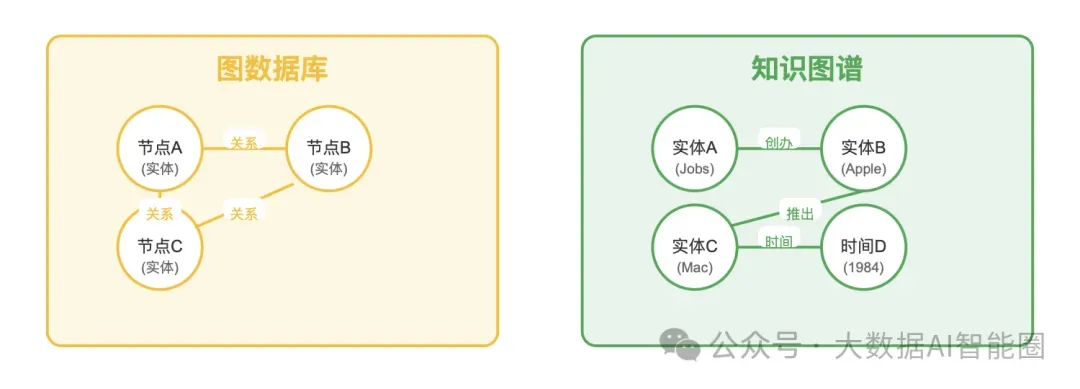
图数据库通过节点与边表达实体间关系,区别于向量数据库的关键在于:关系本身成为数据模型的核心。每条关系都拥有方向性、权重和上下文,映射企业内部复杂的知识生态。
图数据库技术应用于RAG场景时,能清晰回答"谁"、"什么"、"何时"类问题。用户提问"Apple何时推出Macintosh?",系统直接沿着实体关系追溯:Apple(实体)→推出(关系)→Macintosh(实体)→时间(属性)→1984(值)。
知识图谱在图数据库基础上进一步发展,用语义描述收集和连接概念、实体、关系和事件。
这种模型极大模拟了人类思维方式,能理解复杂上下文并保留隐含关系。
研究表明,在同样使用GPT的条件下,从基于SQL数据库的16%准确率提升到使用知识图谱表示时的54%准确率。这种飞跃性提升来自知识图谱对语义关系的精准编码。
企业级RAG数据方案的最佳实践

企业选择数据方案时,需基于业务场景确定最适合的方案。
RAG系统的核心挑战在于:一方面需高效检索海量信息,另一方面必须保持信息间的复杂关联与上下文。
真正高效的企业级RAG解决方案应当整合多种技术优势:利用向量数据库处理非结构化内容,同时依靠知识图谱保留关系和语义,两者协同工作。
在实践中,当面对"Steve Jobs创办了哪些公司?"此类多跳查询时,纯向量搜索可能仅找到片段信息,而知识图谱可沿关系网络追溯,提供完整脉络。
每种数据方案都有其适用场景:向量数据库适合语义相似性搜索,图数据库擅长处理关系密集型数据,知识图谱则在复杂上下文理解中表现最佳。
企业级RAG不是技术选型的二选一,而是综合考量三种方案特性,根据具体业务场景进行最优组合。这不仅关乎系统效能,更直接影响员工对AI辅助工具的信任和接受度。
记住:成功的RAG系统应当如同企业的认知神经网络 - 高效检索与精准关联相互融合,使AI真正成为企业知识管理的得力助手。


