一项由苹果研究人员主导的新研究,对当前被寄予厚望的大型推理模型(LRM)泼了一盆冷水。
研究发现,在解决复杂任务时,像 Claude3.7Thinking 和 Deepseek-R1等专为“模拟思维过程”设计的推理模型,不仅未能展现出优势,反而出现“思考不足”、性能崩溃等严重问题。
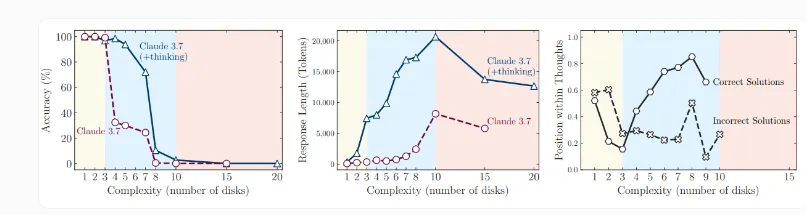
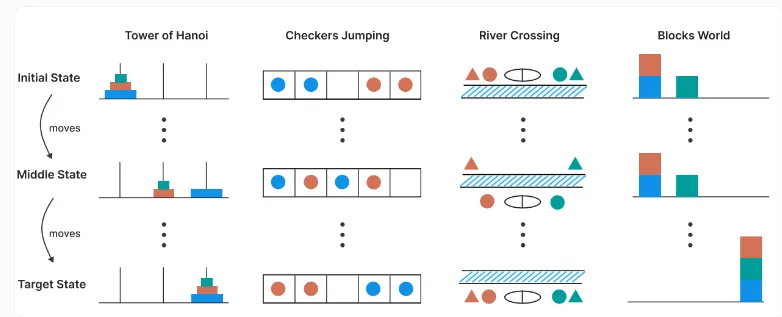
这项研究测试了四种经典逻辑谜题:汉诺塔、跳棋、渡河与积木世界。这些谜题允许精确控制任务复杂度,是衡量语言模型推理能力的理想场景。结果显示,标准 LLM 在简单任务中准确率更高且效率更高,而当复杂度升高,推理模型虽表现稍有提升,但最终同样在高复杂度下全面崩溃。
更令人意外的是,这些模型在面对最复杂任务时,不仅准确率下降为零,反而使用了更少的推理标记(tokens)。换句话说,它们“思考”的意愿和能力反而降低了。
研究团队绘制了模型在不同复杂度下的推理轨迹,揭示了两种典型失败模式:过度思考:在简单问题中,模型找到答案后仍持续生成错误备选方案;思考崩溃:在高复杂度问题中,推理过程戛然而止,连尝试路径都无法生成。
虽然推理模型借助“思路链”“自我反思”等机制被认为是通往通用人工智能(AGI)的一步,但苹果的研究指出:这些机制在扩展性上存在根本缺陷,目前的推理模型无法制定出具备通用性的策略,其“思考”更多是统计上的生成,而非真正的逻辑演绎。
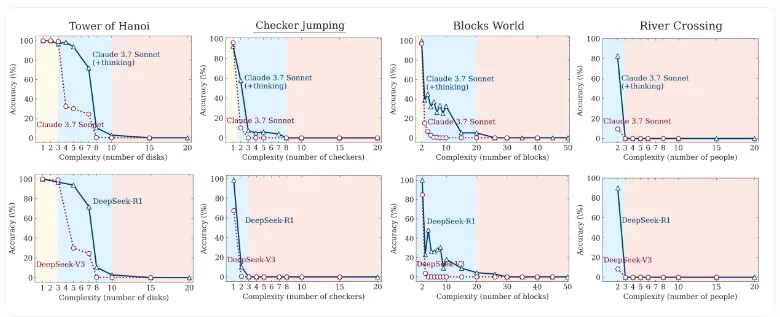
研究还发现,不同谜题的表现也与训练数据相关。例如,出现在训练数据中较多的“汉诺塔”任务,其准确率普遍高于复杂度相似但数据稀少的“渡河”任务。这凸显了当前模型对训练分布的高度依赖性。
苹果研究人员最终指出:“当前推理模型的‘思维能力’存在与问题复杂度相对的不对称扩展性,在结构上无法支撑高阶任务的解决。”他们建议,对推理模型的核心设计原则应进行重新思考。
这一发现对行业影响深远。随着 AI 模型规模扩展收益趋于饱和,推理能力被视为通向下一阶段 AI 革命的关键,包括 OpenAI 在内的多家头部企业均在此方向押下重注。如今,这项研究提醒人们:在走向真正“理解”和“推理”的路上,AI 仍面临根本性的技术挑战。


