
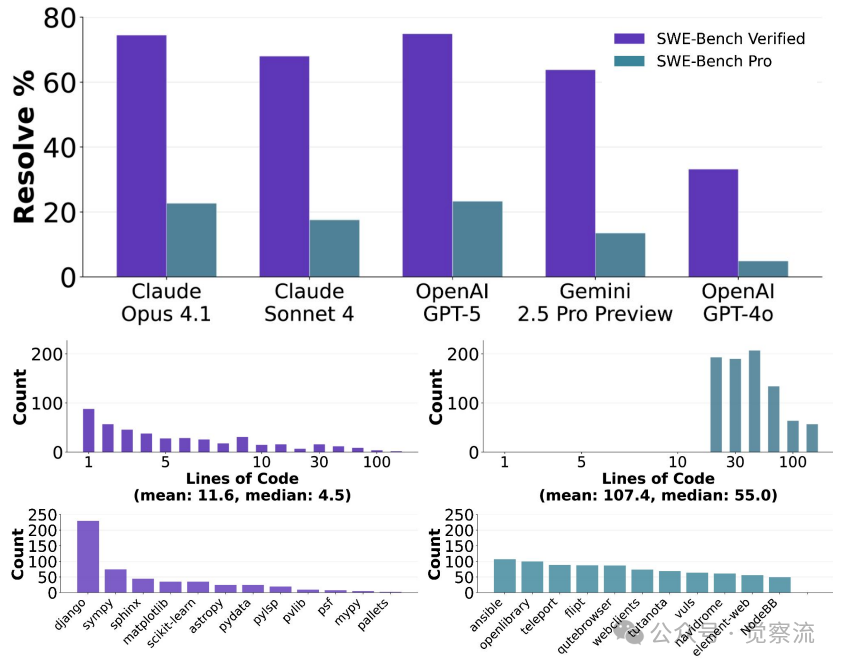
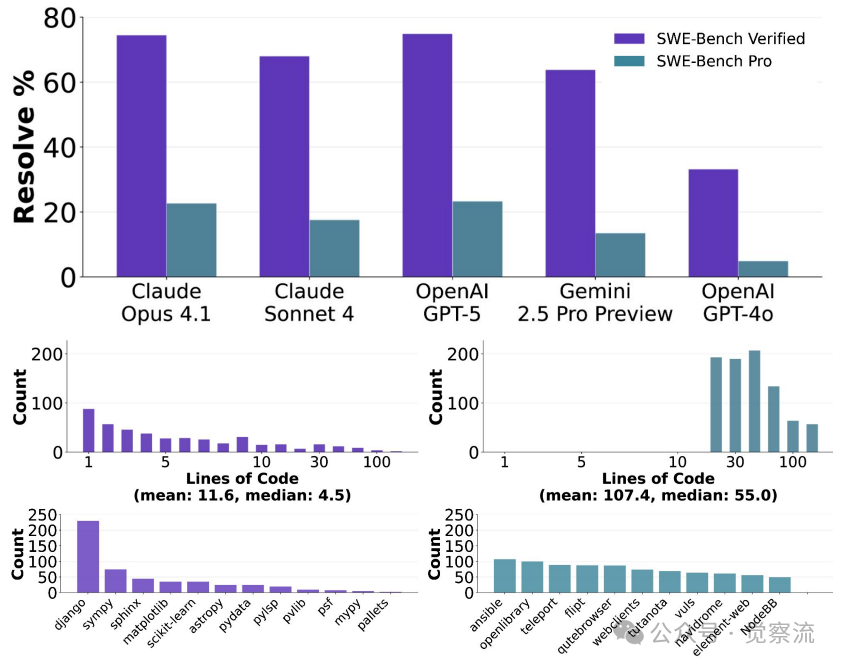
大家好,我是肆〇柒。今天要与大家分享的是一项由 Scale AI 研究团队最新发布的重磅研究成果——SWE-Bench Pro。这项研究增强了我们对 AI 编程智能体能力的认知,它不再满足于测试模型能否完成简单的代码修改,而是直面真实企业环境中那些需要修改数百行代码、跨越多个文件的复杂任务。当看到 GPT-5 在这一新基准上仅获得 23.3% 的通过率时,我们可能一直低估了专业级软件工程的真正挑战。
当你让AI修复复杂bug时,它为何总是"卡住"?
你是否曾遇到过这样的场景:当你让AI编程智能体修复一个需要修改5个文件、涉及120行代码的bug时,它不是反复读取同一文件,就是生成了语法正确的代码却完全误解了问题本质?这并非你的错觉,而是当前AI编程智能体在真实企业级任务中的普遍表现。
当你尝试让智能体为Open Library添加Google Books元数据源支持时——这个看似简单的功能请求,实际上需要协调8个文件、处理ISBN-13解析、实现错误处理机制、确保与现有Amazon集成无缝衔接——你可能会惊讶地发现,即便是最先进的模型也难以完成这项任务。这正是SWE-Bench Pro要揭示的核心问题:在SWE-Bench-Verified上报告超过70%通过率的模型,面对真正复杂的、企业级的软件工程任务时,其表现究竟如何?
SWE-BENCH PRO 是设计来模拟真实、具有挑战性的软件工程任务
SWE-Bench-Verified中超过30%的任务(161/500)仅需1-2行代码修改即可解决,而真实的企业软件工程通常需要跨越数百行代码的多文件修改。SWE-Bench Pro正是为填补这一评估鸿沟而生,它包含1,865个经人工验证的问题,源自41个活跃维护的仓库,每个问题平均涉及107.4行代码修改和4.1个文件变更,真实反映了专业软件工程师需要花费数小时甚至数天才能完成的"长周期任务"。
Open Library的故事:一个被简化的功能请求背后
让我们深入SWE-Bench Pro中的一个典型任务——Open Library的"Google Books元数据源"集成,这将帮助我们理解为什么简单任务与复杂任务之间存在如此巨大的能力鸿沟。
Open Library是一个由互联网档案馆运行的开源非营利项目,目标是为每本出版的书籍创建一个网页。作为真实世界的全栈Web应用,Open Library代表了SWE-Bench Pro所包含的仓库类型,其复杂性远超单一文件修改的范畴。
从模糊到清晰:问题描述的演变
原始提交信息仅简单写着"enable vCard v4.0 contact import(close #1328)",没有提供任何描述。而在SWE-Bench Pro中,这一问题被重写为清晰、完整的问题陈述:

问题陈述对比:原始提交信息 vs 人工重写的问题
重写后的问题不仅描述了问题现象(vCard 4.0导入失败),还详细说明了影响范围、复现步骤、预期行为和附加上下文。这种转变正是SWE-Bench Pro人类增强流程的核心价值——保留核心技术挑战的同时,消除不必要的模糊性。
任务的真正复杂度:7项需求与8+文件修改
当你作为开发者接到这个任务时,你会发现它远不止"添加一个API调用"那么简单。SWE-Bench Pro为该任务定义了7项具体需求:
1. 在openlibrary/core/imports.py中将"google_books"添加到STAGED_SOURCES元组
2. 实现正确的URL构建:"http://{affiliate_server_url}/isbn/{identifier}?high_priority=true&stage_import=true"
3. 在supplement_rec_with_import_item_metadata中正确处理source_records字段
4. 在scripts/affiliate_server.py中实现stage_from_google_books函数
5. 为affiliate_server处理程序添加Google Books回退逻辑
6. 处理Google Books返回多结果的情况,记录警告并跳过
7. 确保解析的元数据字段符合Open Library导入系统要求
这些需求需要修改8个以上文件,涉及scripts/affiliate_server.py、openlibrary/core/imports.py、openlibrary/plugins/importapi/code.py等多个关键组件。更关键的是,新功能必须与现有Amazon集成无缝协作,这要求智能体理解整个导入流程的架构设计。
为什么SWE-Bench无法准确评估这类任务?
在理解SWE-Bench Pro的设计之前,我们需要先认识SWE-Bench的三大局限,这些局限使它无法准确评估像Open Library任务这样的复杂场景。
数据污染风险:训练数据与测试数据的模糊边界
当你使用SWE-Bench测试模型时,是否考虑过这些测试问题可能已经出现在模型的训练数据中?宽松许可(MIT/Apache/BSD)的项目极易被纳入训练数据,而copyleft许可(GPL)则形成了法律屏障。SWE-Bench-Verified使用的仓库多为宽松许可,这意味着模型可能只是在"回忆"训练数据中的解决方案,而非真正理解并解决软件工程问题。
任务过于简单:1-2行修改 vs 100+行修改
当你在SWE-Bench-Verified中看到70%以上的通过率时,是否知道其中161个问题(占总数500的32.2%)仅需1-2行代码修改?相比之下,Open Library的Google Books集成任务平均需要修改107.4行代码、跨越4.1个文件,超过100个任务需要修改100行以上代码。这才是真实企业级开发的常态。
缺乏企业级代表性:从单一文件到多系统集成
当你在企业环境中工作时,是否经常需要处理跨多个服务、涉及遗留系统集成的复杂问题?SWE-Bench-Verified主要关注单一文件的小规模修改,而忽视了企业环境中常见的多文件、长周期开发任务。真实的企业软件工程通常需要跨越数百行代码的多文件修改,而这些复杂场景在SWE-Bench中未能得到充分体现。
SWE-Bench Pro如何解决这些问题?
SWE-Bench Pro通过三大设计原则,确保像Open Library这样的任务能够被准确评估,从而揭示模型的真实能力边界。
抗污染设计:确保评估的公正性
SWE-Bench Pro将数据集分为三部分:
- 公开集(731问题):全部来自GPL许可仓库,确保这些内容不太可能出现在商业模型的训练数据中
- 商业集(276问题):来自18家初创公司的私有代码库,完全隔离于公开训练数据
- 预留集(858问题):用于未来防过拟合检查
Open Library任务属于公开集,采用GPL许可,这确保了评估结果的真实性和可靠性。当你看到GPT-5在该任务上表现不佳时,可以确信这不是因为数据污染,而是模型真实能力的体现。
任务复杂性保障:从简单修改到系统集成
SWE-Bench Pro严格排除了所有1-10行修改的简单任务,确保每个问题都具有真实企业级复杂度。以Open Library任务为例:
- 需要修改8+个文件,而非单一文件
- 涉及多个组件的协调(Amazon集成、Google Books API、导入管道)
- 需要处理边缘情况(多结果返回、缺失字段等)
- 要求理解整个系统的数据流和架构
这种复杂度正是真实企业开发的写照。当你作为开发者面对类似任务时,你会发现它需要的不仅是语法正确的代码,更是对整个系统架构的深入理解。
人类增强验证流程:保留挑战,消除模糊
SWE-Bench Pro为Open Library任务设计了三阶段增强流程:
1. 问题描述重构:将模糊的原始issue重写为清晰的问题陈述
2. 需求列表制定:明确列出7项具体需求,确保任务可验证
3. 接口规范定义:明确指定stage_from_google_books等函数的签名和行为
这一流程解决了SWE-Bench中"问题描述模糊"和"命名不一致导致误判"两大痛点。例如,明确要求stage_from_google_books必须返回布尔值,避免模型因命名不一致而失败。当你作为开发者使用AI工具时,这种清晰的规范能显著提高工具的有效性。
实证结果:为什么你的AI助手在复杂任务上"卡住"?
当你看到SWE-Bench-Verified上70%以上的通过率时,是否曾对AI编程智能体产生过高期望?SWE-Bench Pro揭示了一个残酷但重要的真相:在真正复杂的任务面前,即便是最先进的模型,其表现也远未达到专业软件工程师的水平。
整体表现:23.3% vs 70%+
GPT-5在SWE-Bench Pro公开集上仅达到23.3%的通过率,而在更具挑战性的商业集上,这一数字进一步下降至14.9%。这与SWE-Bench-Verified上>70%的通过率形成鲜明对比。
 SWE-BENCH PRO 是设计来模拟真实、具有挑战性的软件工程任务
SWE-BENCH PRO 是设计来模拟真实、具有挑战性的软件工程任务
这一差距揭示了一个关键事实:当任务复杂度提升至企业级水平时,现有LLM智能体的能力存在显著局限。在Open Library任务上,GPT-5和Claude Opus 4.1的表现均远低于25%,这解释了为什么你在实际工作中感到AI助手不如演示视频中那么强大。
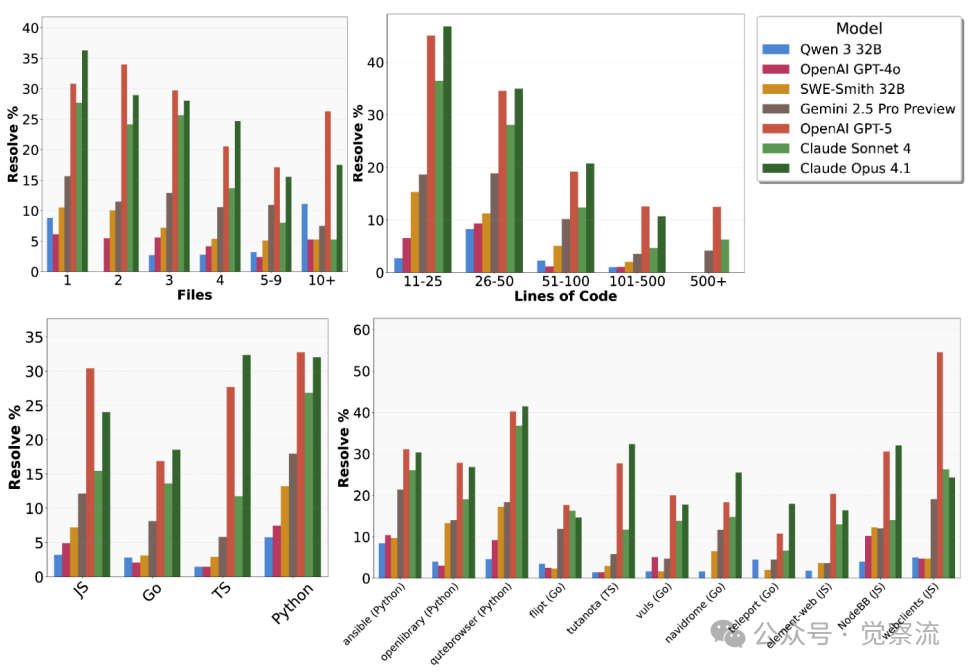
语言差异:为什么你的JavaScript项目更难用AI辅助?
当你在开发JavaScript/TypeScript项目时,是否发现AI助手的表现不如在Python项目中稳定?SWE-Bench Pro的评估结果给出了答案:
不同语言和仓库上的模型性能分布
- Python和Go任务上,部分模型可达30%以上通过率
- JavaScript和TypeScript任务表现波动极大,从接近0%到超过30%不等
为什么会这样?可能的原因是Python/Go的代码结构更清晰、类型系统更规范,降低了模型理解难度。当你在开发React应用时,面对复杂的组件交互和状态管理,AI智能体更容易迷失方向——正如上图所示,某些JavaScript仓库中所有模型的通过率都低于10%。
失败模式深度解析:你的AI助手为何"卡住"?
让我们回到Open Library任务,看看GPT-5和Claude Opus 4.1是如何失败的:
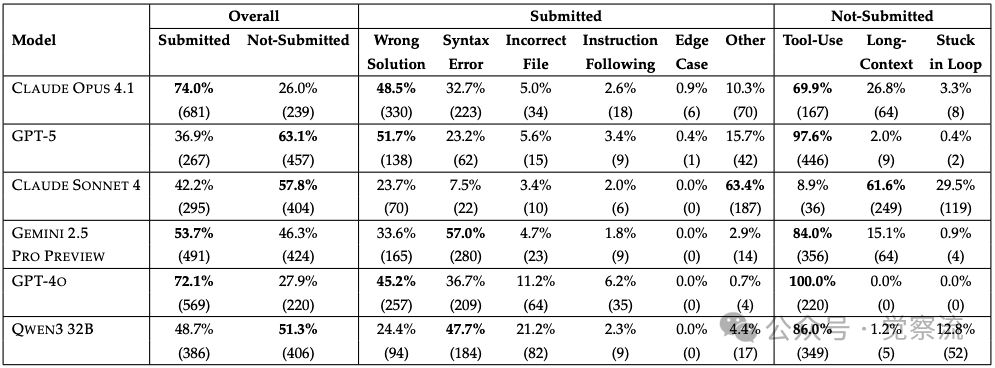
大型模型(Opus 4.1/GPT-5):
- 提交率高(Opus 4.1: 74.0%,GPT-5: 36.9%),表明它们能有效利用工具
- 主要失败:语义理解错误(Opus 4.1:35.9% wrong solutions)
- 次要失败:语法错误(24.2%)和文件导航问题
以Open Library任务为例,当Claude Opus 4.1尝试修改scripts/affiliate_server.py时,它能正确调用工具查看文件,却误解了stage_from_google_books与get_current_batch之间的关系,导致生成的代码无法正确处理批处理逻辑。它能执行技术操作,但在理解问题本质和算法正确性方面存在挑战。
中型模型(Sonnet 4):
- 提交率中等(42.2%),但提交中错误率高(63.4%)
- 主要失败:上下文溢出(35.6% context overflow)和无限文件读取(17.0% endless file reading)
当Sonnet 4面对Open Library任务时,它反复读取同一组文件(如affiliate_server.py和imports.py),却无法确定核心修改点。就像你在调试复杂问题时不断在IDE中跳转文件却找不到问题根源,AI智能体也面临类似的"记忆"限制。
不同模型在 SWE-Bench Pro 上的失败模式分析
这些失败模式解释了为什么你在实际工作中经常看到AI助手:
- 生成语法正确的代码,却完全误解问题(语义理解错误)
- 不断查看文件却无法推进(无限文件读取)
- 在复杂任务中迷失方向(上下文溢出)
启示与展望:如何在你的项目中有效使用AI编程智能体
SWE-Bench Pro不仅是评估工具,更为我们提供了如何在实际项目中有效使用AI编程智能体的洞见。
SWE-Bench Pro的三重价值:超越简单通过率
SWE-Bench Pro通过"多样化的现实任务选择;具有挑战性的多文件代码修改;以及严格的污染预防"三大核心原则,创建了一个更准确反映专业软件工程复杂性的基准。当你评估AI工具时,应关注其在类似任务上的表现,而非简单任务的通过率。
当前局限与实用建议
虽然SWE-Bench Pro代表了重大进步,但它也揭示了当前AI编程智能体的局限:
- 语言差异显著:如果你是前端团队负责人,面对JavaScript/TypeScript任务,应意识到即使是最先进的模型也可能在关键任务上失败。参考Figure 4,你可能需要设计额外的验证层,而非完全依赖AI生成的代码。
- 企业代码库更难处理:商业集(14.9%)显著低于公开集(23.3%),证明企业私有代码库的复杂度更高。当你将AI工具引入企业环境时,应预期其表现会低于公开基准。
- 多文件修改是最大挑战:上下文溢出(35.6%)和无限文件读取(17.0%)是主要失败模式。当你让AI处理涉及多个文件的任务时,应明确指示关键文件和修改点。
未来研发重点:解决你每天遇到的问题
基于SWE-Bench Pro的发现,未来研发应聚焦三个关键方向,这些方向直接关系到你在日常工作中可能获得的改进:
1. 多文件协同能力:强化跨文件代码理解和修改能力,解决你经常遇到的"AI助手无法理解整个系统架构"问题
2. 上下文管理:解决"endless file reading"和"context overflow"问题,让你不再看到AI助手在文件间无休止地跳转
3. 语义理解:提升对业务逻辑和算法正确性的把握,减少"语法正确但逻辑错误"的代码
对程序猿的具体行动指南
基于SWE-Bench Pro的结果,以下是你可以在项目中立即应用的实用建议:
1. 针对不同语言选择合适的工具:
- 对于Python/Go项目,可尝试GPT-5处理中等复杂度任务,但需重点检查语义正确性
- 对于JS/TS项目,应设置更严格的验证流程,因为模型在此类任务上表现波动极大
2. 复杂任务分步处理:
当任务涉及多文件修改时,先让AI助手聚焦单个文件或组件
- 明确指示关键文件和修改点,避免上下文溢出
3. 建立验证层:
对AI生成的代码实施额外的代码审查
- 特别关注边缘情况处理,因为模型在这些方面最容易出错
4. 渐进式应用策略:
从代码生成辅助开始
逐步扩展到简单问题修复
但关键系统仍需人工审核
总结:专业级AI工程师的试金石
23.3%的通过率揭示了LLM代码能力的真实边界——在真正复杂的、企业级的软件工程任务面前,AI智能体仍有很长的路要走。当你下次让AI助手处理像Open Library任务这样需要多文件协调修改的复杂问题时,你将明白为什么它经常"卡住"。这是当前技术的真实局限。
SWE-Bench Pro通过多样化的现实任务选择;具有挑战性的多文件代码修改;以及严格的污染预防三大核心原则,创建了一个更准确反映专业软件工程复杂性的评估环境。这一新基准不仅提供了更准确的进展衡量标准,还为解决当前局限提供了关键洞见,指引着未来研究朝着开发真正自主、有能力的软件工程智能体的方向前进。
对我们而言,这意味着:
- 不要被SWE-Bench-Verified上70%+的通过率迷惑
- 关注模型在复杂任务上的实际表现
- 为AI工具设定合理的期望和使用边界
- 重点关注语义理解和多文件协同能力的提升
只有通过更真实、更难、更干净的评估标准,才能推动AI编程智能体真正达到专业级水平。SWE-Bench Pro正是这一道路上的关键试金石,它不仅告诉我们AI现在能做什么,更清晰地指明了我们需要朝哪个方向努力。真正的专业判断,不仅在于知道工具能做什么,更在于知道它不能做什么。


