Recently, The University of Hong Kong and NVIDIA jointly developed a new visual attention mechanism called Generalized Spatial Propagation Network (GSPN), which has made significant breakthroughs in high-resolution image generation.
Although traditional self-attention mechanisms have achieved good results in natural language processing and computer vision fields, they face dual challenges of huge computational overhead and loss of spatial structure when handling high-resolution images. The computational complexity of traditional self-attention mechanisms is O(N²), making it very time-consuming to process long contexts. Additionally, converting two-dimensional images into one-dimensional sequences causes the loss of spatial relationships.
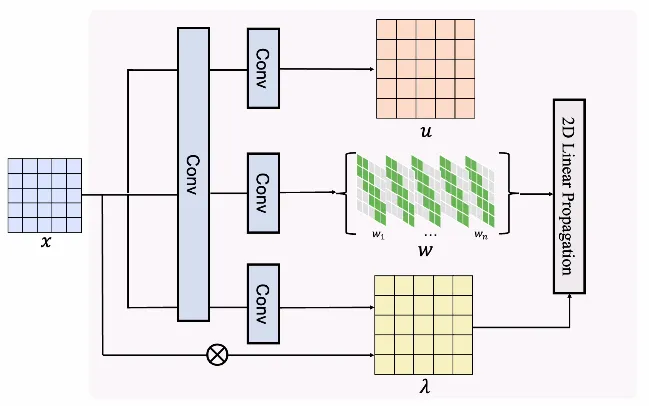
To address these issues, GSPN adopts an innovative two-dimensional linear propagation method combined with the "stability-context conditioning" theory, reducing the computational complexity to √N level while preserving the spatial coherence of the image. This new mechanism significantly improves computational efficiency and sets performance records on multiple visual tasks.
The core technology of GSPN includes two major parts: two-dimensional linear propagation and stability-context conditioning. By scanning row by row or column by column, GSPN can efficiently process two-dimensional images. Compared with traditional attention mechanisms, GSPN not only reduces the number of parameters but also maintains the integrity of information propagation. Moreover, researchers proposed the stability-context conditioning to ensure the system's stability and reliability during long-distance propagation.
In experiments, GSPN demonstrated outstanding performance. In image classification tasks, GSPN achieved an 82.2% Top-1 accuracy at 5.3GFLOPs, surpassing many existing models. In image generation tasks, GSPN increased the generation speed by 1.5 times when processing 256×256 tasks. Especially in text-to-image generation tasks, GSPN could quickly generate images at a resolution of 16K×8K, accelerating inference time by more than 84 times, showcasing its great potential in practical applications.
In summary, GSPN, through its unique design concepts and structures, has significantly improved computational efficiency while maintaining spatial coherence, opening up new possibilities for future multimodal models and real-time visual applications.
Project homepage: https://whj363636.github.io/GSPN/
Code: https://github.com/NVlabs/GSPN
Key points:
🌟 GSPN boosts the generation speed of high-resolution images by over 84 times through an innovative two-dimensional linear propagation mechanism.
💡 This mechanism solves the problems of computational complexity and loss of spatial structure in traditional self-attention mechanisms when handling high-resolution images.
🚀 GSPN sets performance records in multiple visual tasks, providing new directions for future applications.


