环境:SpringBoot3.4.2
1. 简介
人类处理知识时,会同时通过多种数据输入模式进行。我们的学习方式、经验积累本质上都是多模态的。我们并非仅依赖视觉、仅依赖听觉或仅依赖文本,而是综合运用多种感官。
与之相反,传统机器学习往往专注于针对单一模态数据进行处理的专用模型。例如,我们开发了用于文本转语音或语音转文本任务的音频模型,以及用于目标检测和分类等任务的计算机视觉模型。
然而,新一轮的多模态大型语言模型浪潮正悄然兴起。例如,OpenAI 的 GPT-4o、谷歌的 Vertex AI Gemini 1.5、Anthropic 的 Claude3,以及开源模型 Llama3.2、LLaVA 和 BakLLaVA 等,均能够接受多种输入(包括文本、图像、音频和视频),并通过整合这些输入生成文本响应。
Spring AI 多模态能力
多模态(Multimodality)指模型能够同时理解并处理来自多种来源的信息,涵盖文本、图像、音频及其他数据格式。
Spring AI 的 Message API(消息接口) 为多模态大型语言模型(LLMs)提供了所有必要的抽象层支持,开发者可通过该接口实现跨模态数据的无缝整合与交互,无需底层适配即可构建支持文本、图像、音频等多输入源的AI应用。
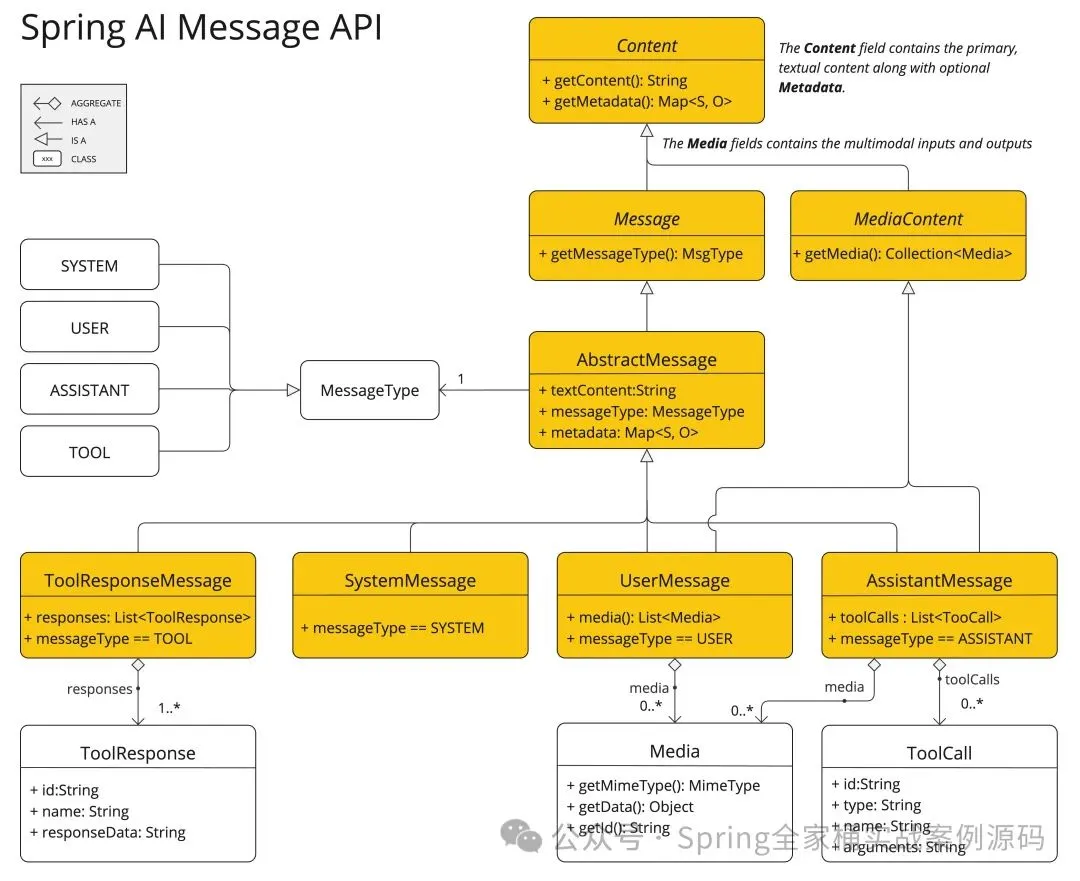 Spring AI Message API
Spring AI Message API
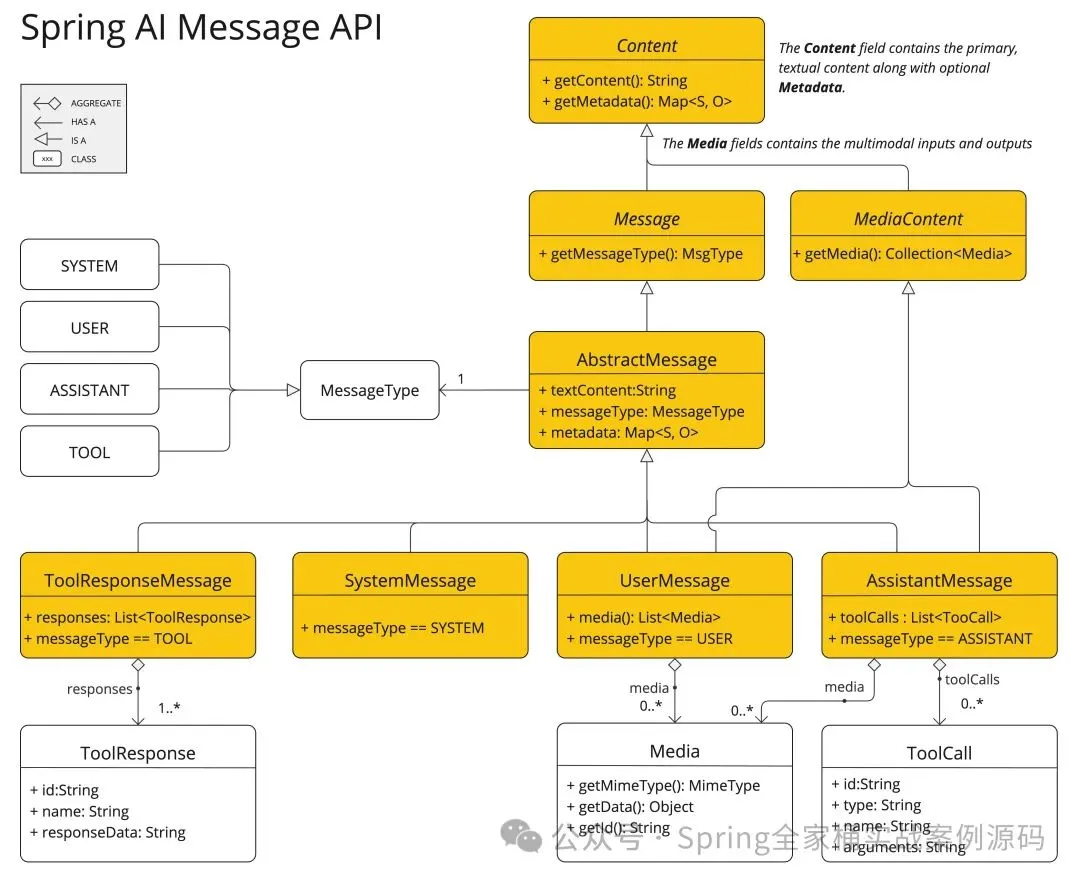 说明:
说明:
UserMessage 的 content 字段 用于承载主要文本输入,而可选的 media 字段 则支持添加一种或多种跨模态附加内容(如图像、音频、视频等)。字段通过 MimeType 明确标识模态类型,以定义数据格式(如 image/jpeg、audio/mp3)。
接下来,我们将通过实例演示有关图片识别的实例。
2.实战案例
准备环境
复制<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-model-openai</artifactId> </dependency>
配置文件
复制spring:
ai:
openai:
api-key: sk-xxxooo
base-url: https://api.xty.app
chat:
options:
model: gpt-42.1 图片分析
首先,我们准备如下的这张图片,我们对该图片进行分析,看看大模型能分析出什么内容来:
示例代码:
复制private final ChatClient chatClient ;
@GetMapping("/image")
public String image() {
return this.chatClient
.prompt()
.user(u -> u.text("你看到了什么?")
.media(MimeTypeUtils.IMAGE_PNG, new ClassPathResource("static/multimodal.test.png")))
.call()
.content() ;
}输出结果
 图片
图片
正确的分析出图片中的内容。
2.2 身份证识别
下面我们在准备一张身份证,看看是否能正确的读取出身份证中的内容信息。
 图片
图片
示例代码:
复制@GetMapping("/sfz")
public String sfz() {
String text = """
输出该身份证中的姓名(name), 性别(sex), 民族(nation), 出生(birth), 住址(address), 身份证号码(idNo)。
最终以json格式输出。
""";
return this.chatClient
.prompt()
.user(u -> {
u.text(text)
.media(MimeTypeUtils.IMAGE_PNG, new ClassPathResource("static/sfz.jpg"));
})
.call()
.content() ;
}输出结果
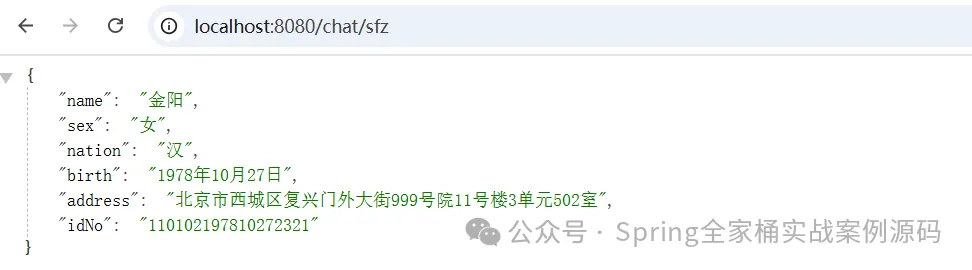 图片
图片
正确识别出身份证中的所有信息。
2.3 结构化输出
以下示例将演示通过上传汽车图片方式分析图片,并由系统以结构化 JSON 格式返回分析结果(例如各颜色,总数)。
定义数据模型
复制public record CarCount(List<CarColorCount> counts, int total) {
}
public record CarColorCount(String color, int count) {
}接着,定义如下Service 发送图片到OpenAI进行分析
复制@Service
public class CarCountService {
private final ChatClient chatClient;
public CarCountService(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
public CarCount getCarCount(InputStream imageInputStream, String contentType, String colors) {
String text = """
1.统计图像中不同颜色车辆的数量
2.用户通过提示词(prompt)提供图像,并指定需统计的颜色
3.仅统计用户提示词中明确指定的颜色(忽略其他颜色)
4.过滤用户提示词中的非颜色信息(如无关文本或无效描述)
5.若用户提示词中未指定任何颜色,直接返回总数为 0
""" ;
return chatClient.prompt()
.system(systemMessage -> systemMessage
.text(text))
.user(userMessage -> userMessage
.text(colors)
.media(MimeTypeUtils.parseMimeType(contentType), new InputStreamResource(imageInputStream)))
.call()
.entity(CarCount.class);
}
}REST接口
复制@PostMapping("/count")
public ResponseEntity<?> getCarCounts(@RequestParam("colors") String colors,
@RequestParam("file") MultipartFile file) {
try (InputStream inputStream = file.getInputStream()) {
var carCount = carCountService.getCarCount(inputStream, file.getContentType(), colors);
return ResponseEntity.ok(carCount) ;
} catch (IOException e) {
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body("图片上传失败");
}
}接下来,我们准备如下的图片
 图片
图片
输出结果
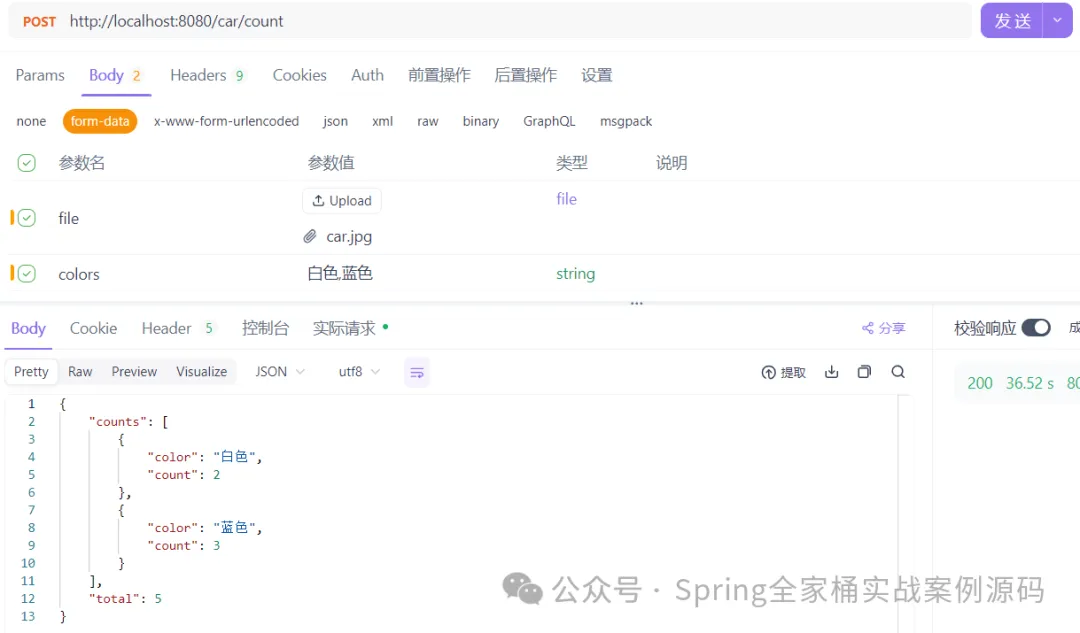 图片
图片


