资讯列表

AI将使勒索软件更加危险
相比之下,在安全专家中,只有29%的人表示他们对勒索软件攻击做了非常充分的准备——这表明在准备程度上存在显著差距(29%),凸显了采取更强大安全措施的必要性。 安全领导者对暴露管理的深刻理解网络安全需要采取一种更先进、更灵活的方法,这种方法要考虑到业务风险与回报之间的权衡,而不仅仅是单纯关注绝对保护。 在复杂的环境中,暴露管理为管理和减轻风险提供了更有效的解决方案。

新一代AI图像生成模型Reve Image震撼登场,引领创作新潮流
一款名为Reve Image的全新AI图像生成模型正式亮相,迅速引发科技与设计圈的广泛关注。 据悉,该模型由Reve团队从零开始打造,专注于提升美学表现、精准的提示遵循能力以及出色的排版设计,旨在为用户提供高质量的视觉创作体验。 Reve Image的推出被视为AI图像生成领域的一大突破。

关于LLMs 复读机问题
今天来看一个关于LLMs复读机问题的详细介绍,主要从定义、出现复读机问题的原因和怎么解决三个方面来介绍:1、什么是 LLMs 复读机问题? LLMs 复读机问题:字符级别重复:指大模型针对一个字或一个词重复不断生成。 例如在电商翻译场景上,会出现“steckdose steckdose steckdose steckdose steckdose steckdose steckdose steckdose...”;语句级别重复:大模型针对一句话重复不断生成。

王兴:美团已开发内部大模型 LongCat,AI 策略是主动进攻
王兴认为,每当有像人工智能这样颠覆性的技术出现时,唯一有意义的应对策略并非捍卫已有的东西,而是要利用自身所拥有的一切资源去主动进攻。这是唯一行之有效的应对策略。

来了!十个构建Agent的大模型应用框架
随着生成式人工智能(GenAI)的蓬勃发展,基于大型模型的应用已经悄然融入我们的日常工作和生活,它们在诸多领域中显著提升了生产力和工作效率。 为了更便捷地构建这些基于大模型的应用程序,开源社区和产品开发者们正以前所未有的速度进行创新。 在这些创新中,面向智能体(Agent)的应用,即所谓的Agentic AI,已经崭露头角,成为近年来生成式AI系统中最具潜力的明星。

开源实时识别模型RF-DETR: 实时识别画面中的物体,开源可商用
RF-DETR是一款由Roboflow团队倾力打造的开源、最先进的实时目标检测模型。 如果你还在为YOLO系列跑得不够快,或者精度差那么一点点而挠头,那么恭喜你,救星来了!RF-DETR目标直指实时识别领域的王座,并且它还非常慷慨地选择了开源,这意味着你可以免费拥有,甚至还能“魔改”出自己的专属“鹰眼”。 想象一下,你的智能监控系统能够像一位经验老道的侦探一样,在视频流中瞬间捕捉到每一个关键物体,而且速度快到让你怀疑人生。

Meta 推出强化学习新框架 SWEET-RL,让 AI 更懂人类意图
SWEET-RL通过逐轮反馈和架构对齐优化,显著提升了多轮人机协作任务的性能。该框架在开源模型上的成功应用,减少了对专有模型的依赖,展示了其在真实场景中的实用性和可扩展性。未来,这一研究有望推动更多高效、协作型AI代理的开发。
AbletonMCP :调用Ableton的MCP服务,让Claude能够创作音乐
AbletonMCP 是一款创新工具,它通过模型上下文协议(MCP)将音乐制作软件 Ableton Live 与 Claude AI 连接起来,使得 Claude 能够直接与 Ableton Live 进行互动和控制。 这种整合实现了基于提示的音乐创作、音轨制作和现场会话的操控,为音乐制作带来了全新的体验。 该系统主要由两个部分组成:Ableton 远程脚本和 MCP 服务器。

让 AI 听懂你的语言:DeepSeek 提示词技巧介绍
在生成式AI技术飞速发展的今天,提示词(prompt)已成为人机交互的核心接口。 DeepSeek作为领先的智能对话系统,其输出质量直接取决于提示词的编写水平。 数据显示,专业优化的提示词可将回答准确率提升60%以上。

"瀚海智语"大模型正式发布,助力中国海洋领域智能化
国家自然资源部近日宣布,国家海洋环境预报中心联合海洋出版社有限公司和三六零数字安全科技集团有限公司成功开发并发布了海洋垂直领域大语言模型——"瀚海智语"(英文名称OceanDS)。 该模型以360智脑13B和Deepseek-R1-70B大模型为基座,专注于海洋领域应用,已顺利通过专家评审并正式发布。 "瀚海智语"的问世标志着中国在海洋领域人工智能技术应用方面迈出了重要一步,将为海洋行业的智慧化转型提供强有力的技术支撑。

李开复重组01.AI:拥抱 Deepseek 开源模型,挑战 OpenAI 商业模式
前谷歌中国区负责人李开复正在调整他的人工智能初创公司01.AI 的战略,全面采用 Deepseek 的开源模型,并表示这对 OpenAI 的商业模式构成了生存挑战。 在接受《南华早报》采访时,李开复透露他的公司已放弃之前训练专有大型语言模型的策略,转而完全依赖 Deepseek 的开源产品。 他表示,Deepseek 的发布在中国引发了"ChatGPT 时刻",带动了国内硬件和软件提供商与 Deepseek 模型的整合。

Fin-R1:基于Qwen2.5-7B强化学习训练的金融大模型,7B参数击败行业巨头
金融科技领域迎来一位强劲新秀。 上海财经大学统计与数据科学学院张立文教授团队(SUFE-AIFLM-Lab)联合财跃星辰共同研发的Fin-R1模型正式开源,以惊人的性能引发业界广泛关注。 这款基于Qwen2.5-7B的金融专用大模型通过强化学习训练,在多项金融基准测试中达到了领先水平。

腾讯发布混元 - T1 正式版,推理能力大幅提升
近日,腾讯发布了混元大模型系列的正式版 —— 混元 - T1。 这款新模型基于混元中等规模底座,经过大规模后训练,显著增强了推理能力,特别是在深度思考和复杂问题解决方面表现出色。 自从今年2月混元 T1-Preview 上线以来,用户们便体验到了更快、更深刻的思考过程,而此次正式版的推出,则标志着该系列产品的进一步升级。
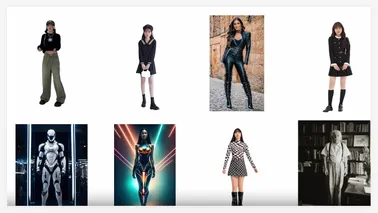
阿里通义实验室LHM技术实现从单图像的快速3D 人体重建与动画生成
近日,阿里通义实验室一项名为 LHM(大型可动画人体重建模型)的创新技术在3D 人体重建领域取得了重大突破,为该领域带来了全新的发展方向和应用前景。 从单个图像进行可动画的3D 人体重建一直是一个极具挑战性的任务,存在着几何、外观和变形分离的模糊性等问题。 当前的最新研究进展大多集中在静态人体建模方面,并且这些方法往往依赖于合成的3D 扫描进行训练,这在很大程度上限制了它们在实际场景中的泛化能力。

Cloudflare 推出 “AI 迷宫”,引导恶意爬虫走入虚假数据陷阱
全球知名的网络基础设施公司 Cloudflare 近日宣布推出一项名为 “AI Labyrinth”(AI 迷宫)的新工具,旨在打击未经授权抓取网站数据的网络爬虫。 这一举措的核心在于,当 Cloudflare 监测到不当的爬虫行为时,该工具会将这些爬虫引导到一系列 AI 生成的虚假页面,目的在于 “拖延、迷惑并浪费” 恶意爬虫的资源。 长期以来,网站管理员依赖 “robots.txt” 文件来管理爬虫的访问权限,但很多 AI 公司,包括一些知名企业,如 Anthropic 和 Perplexity AI,常常忽视这一规则。

AMD发布GAIA开源项目 助力本地大语言模型高效运行
近日,AMD 宣布推出一款名为 GAIA 的开源应用,旨在为用户提供一种高效、本地化的方式来运行大语言模型(LLM)。 目前,该应用已支持 Windows 平台,特别为锐龙 AI300系列处理器进行了优化,充分发挥了这些处理器在 AI 任务中的优势。 GAIA 是一个生成式 AI 应用,用户可以在个人电脑上私密地运行 LLM,确保数据隐私。
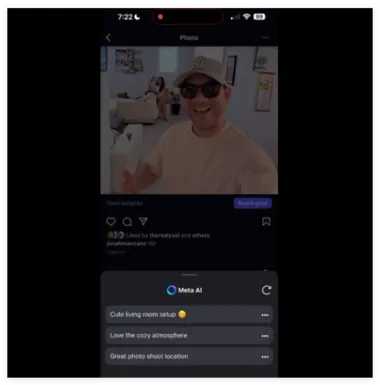
Meta 测试 AI 生成 Instagram 评论功能,用户反应存疑
Meta 正在测试一项新功能,允许用户利用人工智能在 Instagram 上生成评论建议。 X 用户乔纳·曼扎诺(Jonah Manzano)发现并分享了这一测试功能,显示用户可以点击帖子下方的铅笔图标来访问 Meta AI,该 AI 会分析照片并提供三条可能的评论。 如果用户不满意,还可以刷新获取更多建议。

AI自我纠错,Diffusion超越自回归!质量提升55%,已达理论证据下界
如果大语言模型(LLMs)能够发现并纠正自己的错误,那岂不是很好? 而且,如果能够直接从预训练中实现这一点,而无需任何监督微调(SFT)或强化学习(RL),那会怎样呢? 最新提出的离散扩散模型,称为GIDD,它能够做到这一点。