一凡 发自 副驾寺
智能车参考 | 公众号 AI4Auto
VLM的两大瓶颈,有了新的突破方法。
最近,上海期智研究院、理想汽车、同济大学和清华大学等单位合作,提出自动驾驶智能体DriveAgent-R1,让模型不再是被动地接受数据,而是用主动感知机制,从底层逻辑上重塑自动驾驶。

然后结合混合思维框架,让DriveAgent-R1实现了多项SOTA,甚至超越了Claude Sonnet 4等顶尖的多模态大模型。
这项工作意味着理想的AI司机也开始强化学习了。强化学习在行业内已形成广泛共识,对于提升自动驾驶性能起到了关键作用。从L2到L4,自动驾驶已进入强化学习时间。
VLM(Vision-Language-Model视觉语言模型)已成为行业最火热的方向之一,然而VLM存在决策短视和被动感知两大限制,影响了自动驾驶在复杂环境下的可靠性。
为了解决上述问题,研究团队前天发布论文,提出了自动驾驶智能体DriveAgent-R1,通过引入混合思维框架和主动感知机制让智能体具备了长时程、高层级决策能力。
混合思维(Hybrid-Thinking)框架是指DriveAgent-R1正式推理前,会根据输入的多模态数据判断当前视觉信息是否充足,选择思考模式。
如果是信息充足的简单场景,就用纯文本推理,高效快速。如果不足,就调用外部视觉工具补充信息,辅助文本推理。
有点像是「智能体的插混系统」,“可油可电”,具体看场景需求。
主动感知(Active Perception)机制则是让智能体主动探查环境,感知不确定因素。这与以往相关成果在底层逻辑上不同。
过去的自动驾驶系统,大多是被动接受场景数据,能读懂限速和导航相关的文本指令,理解场景的视觉信息,但容易忽略视觉细节,比如模糊的指示牌这种不确定信息。
DriveAgent-R1遇到相关场景时,则会主动地多看或者“凑近看”,确定信息。这种底层逻辑上的改变,让DriveAgent-R1实现了深度视觉依赖,使决策更加鲁棒和有据可依,有了媲美人类老司机的可能。
两大创新结合赋予了DriveAgent-R1强大能力,在多个数据集上实现SOTA。
具体是怎样实现的?
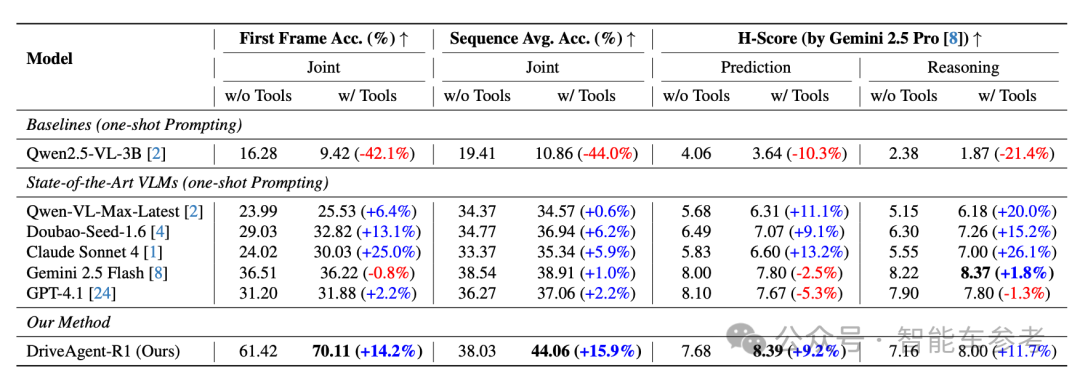
DriveAgent-R1以Qwen2.5-VL-3B为底座,用到了8张H20 GPU。总体上通过视觉编码器处理6路环视摄像头输入的视觉信息,通过语言解码器处理车速和导航等文本指令,最终输出一个8秒长时程驾驶意图的决策。
“决策”表现为一个含有4个元动作的序列,每个元动作由速度和轨迹两部分组成,速度包括加速、减速、保持和停止4种选择,轨迹则有直行、左转和右转。
具体分步来看,DriveAgent-R1的训练采用了「三阶段渐进式训练策略」,核心是强化学习。
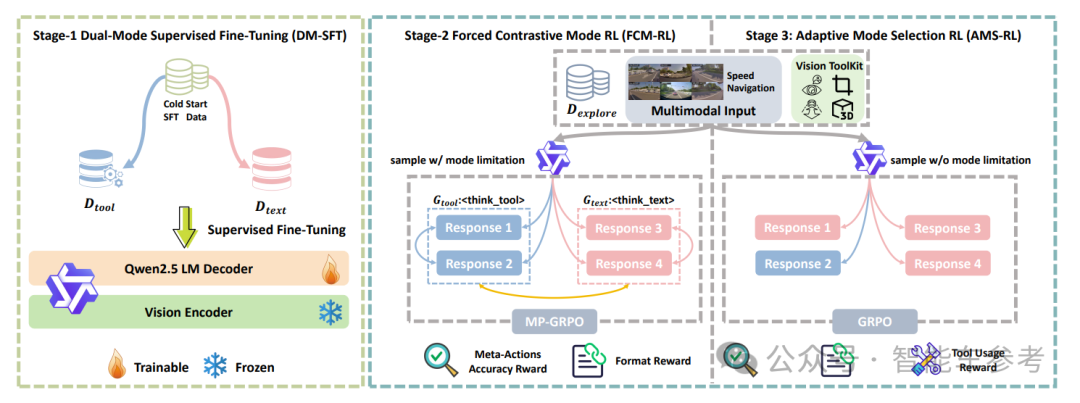
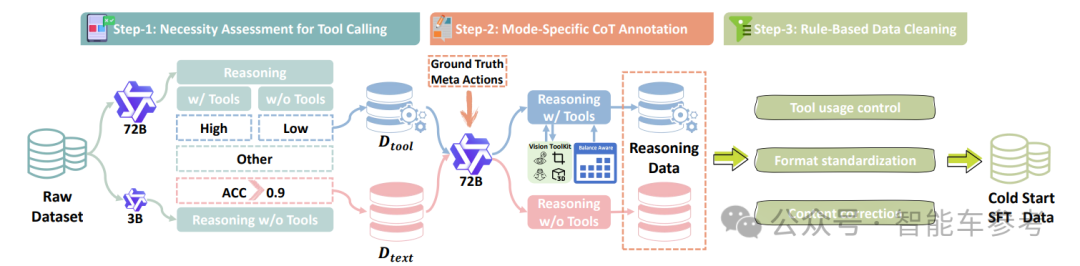
第一阶段双模式监督微调 (DM-SFT),设计一个自动化数据构建流水线。
首先通过一个“工具调用必要性评估”将原始数据划分为工具必需集和工具非必需集。然后使用强大的72B“教师模型”为数据进行逆向推理式CoT标注,最后通过规则进行清洗,构建高质量的冷启动SFT数据集。
第二阶段是强制对比模式强化学习(FCM-RL),提出模式分区GRPO (MP-GRPO)算法,对每个输入,我们强制智能体生成两种模式的响应组,从而创造出一种多维度的对比学习信号,强化模型在不同思考模式下的独立思考能力,避免对某种模式产生偏见。奖励函数由准确性和格式一致性组成。
第三阶段是自适应模式选择强化学习 (AMS-RL),移除了模式强制约束,采用原生的GRPO算法。智能体必须自主选择合适的思维方式,让其可根据上下文自主选择最优的思维模式,实现真正的混合思维。奖励函数在第二阶段的基础上,增加动态奖励窗口,在训练初期鼓励探索工具的使用,在后期则要求高精度的、有影响力的工具使用。
模型测试时,会先输入多模态数据,然后判断当前视觉信息是否充足,再从两种思考模式中做出选择。
简单的常规场景,模型生成特殊token<think_text>激活文本M-CoT模式,完全依赖初始输入和内部知识进行纯文本推理。
复杂或不确定场景,生成特殊token<think_tool>激活工具M-CoT模式。这种情况下,R1会主动调用外部视觉工具,也就是主动感知,获取更多补充信息。
视觉工具主要有以下4种:
- 获取高分辨率视图 (Retrieve High-Resolution View): 智能体缓存了过去5秒所有视角的图像,可以按需请求任一特定视角的高分辨率图像。缓存图像而不是存储视频序列,节省了内存和计算成本。
- 关键区域检查 (RoI Inspection): 相当于给了智能体一个“放大镜”,它可按需框出特定感兴趣区域,主动检查,确认关键细节信息,比如远方的红绿灯或者路牌文字。
- 深度估计(Depth Estimation):利用单目深度估计让模型直观地掌握物体的相对距离和空间布局。
- 3D物体检测 (3D Object Detection) :集成一个开放词汇表单目3D物体检测工具,常规物体和场景中新出现的对象都能检测。
具体实现过程以一个场景为例,比如晚上在没有路灯的小路上行驶,模型意识到非常规场景后,进入工具M-CoT模式,调用外部工具。

然后返回的图像显示前面是个路口,有交通标识而且路上有碎石,需要谨慎驾驶。
接着模型开始推理,发现限速标志看不清,再次调用工具放大看,发现限速30,决定减速,同时稍稍往右打方向,躲开碎石。

最后输出包含4个元动作的决策序列。

这项工作也指出了一些还需要优化的地方,比如外部工具还太少,未来可以集成天气感知模块应对暴雪和大雨这种恶劣天气。生成的轨迹目前也是离散的元动作序列,没有直接生成低层连续轨迹等。
但总的来说,这项工作提供了很多前沿思考,通过实验验证了主动获取视觉信息是VLM的有前景的一个方向,以及强化学习对释放智能体的潜力来说,至关重要。
强化学习既是这项工作的灵魂所在,也是2025年智能辅助驾驶行业加速上车的新范式。
华为ADS 4的车端模型将强化学习和深度学习结合,小鹏汽车走向了强化学习和模型蒸馏路线,Momenta今年要打造基于强化学习的一段式端到端,地平线则认为通过强化学习更能理解物理规律……
无论是供应商还是主机厂,无论是目前专精算法还是软硬结合,不同背景的头部玩家押注了同一条路线。
All in L4的玩家对此认知更早,小马智行楼教主曾透露,其在2020年就意识到要转向强化学习,他当时认为:
模仿学习天花板太低,做不到L4。
从模仿学习到强化学习,是AI司机从“类人”到“超人”的转变。强化学习大规模上车,也意味着L2和L4正在迈入同一条河流,渐进式升维路线,自此开始加速演化。


