就在刚刚,李飞飞World Labs重磅发布全新实时生成式世界模型——RTFM(Real-Time Frame Model,实时帧模型)!
这是一款效率极高的,在大型视频数据上进行端到端训练的自回归扩散Transformer模型。
仅需一块H100 GPU,RTFM就能在你与之交互时,实时渲染出持久且3D一致的世界,无论是真实场景还是想象空间。
其独特之处在于,它不构建世界的显式三维表征。相反,它接收一张或多张二维图像作为输入,然后直接从不同视点生成同一场景的全新二维图像。
简单来说,你可以将它看作一个「学会了渲染的AI」。

仅仅通过观察训练集中的视频,RTFM便学会了对三维几何、反射、阴影等复杂物理现象进行建模;而且,还能利用少量稀疏拍摄的照片,重建出真实世界的具体地点。
请注意,接下来你看到的这些不是真实视频,它们完全是由RTFM实时生成的画面。

RTFM的设计围绕三大核心原则:
- 高效性:仅需单块H100 GPU,RTFM便能以交互式帧率运行实时推理。
- 可扩展性:RTFM的设计使其能随着数据和算力的增加而扩展。它在建模3D世界时不依赖于显式的3D表示,并采用一种通用的端到端架构,从大规模视频数据中学习。
- 持久性:可以与RTFM进行无休止的交互,而这个世界将永不消逝。它所模拟的是一个持久的3D世界,不会在您移开视线时消失。
|
|
|
|
|
|
|
|









RTFM可渲染由单张图像生成的3D场景。同一个模型能处理多样的场景类型、视觉风格和效果,包括反射、光滑表面、阴影和镜头光晕
有网友戏言,「我们的世界或许是在单个H100上运行的」。

前谷歌高级工程师表示,RTFM最新成果真正解决了,长期困扰世界模型可扩展性的问题。

现在,RTFM正式开放,任何人皆可试玩。
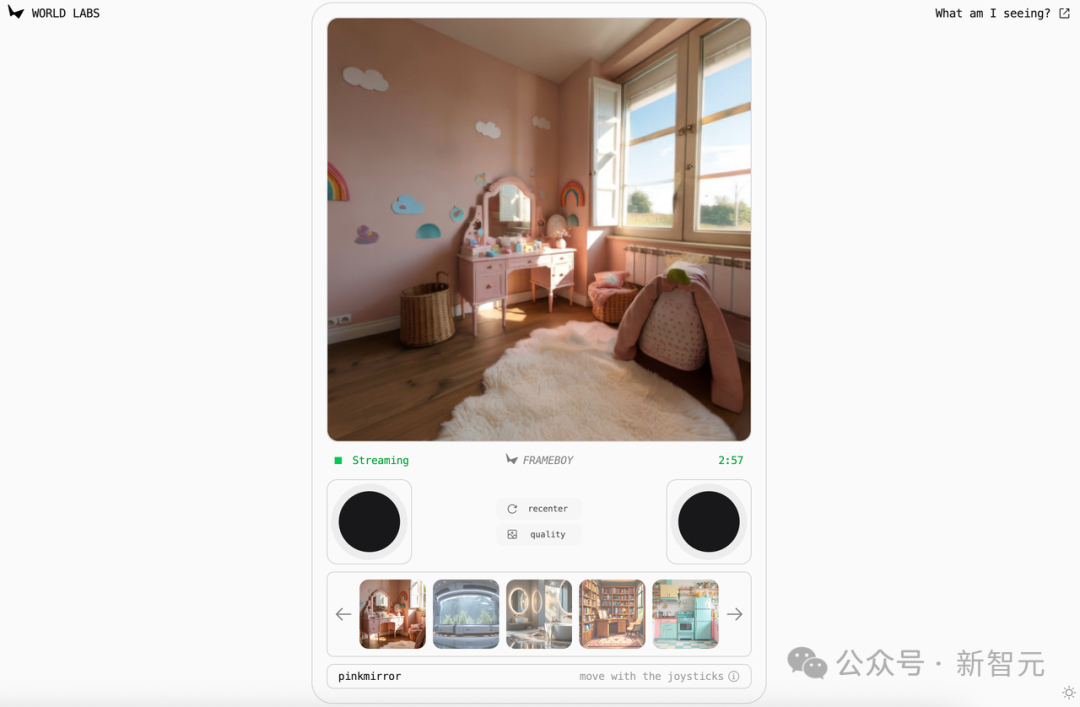
传送门:https://rtfm.worldlabs.ai/
世界模型:算力吞噬者
我们憧憬着这样一个未来:强大的世界模型能够实时地重建、生成并模拟一个持久、可交互且遵循物理规律的世界。这类模型将彻底改变从传媒到机器人等众多行业。
过去一年,随着生成式视频建模的进步被应用于生成式世界建模,这项新兴技术的发展令人振奋。
随着技术的发展,有一点日益清晰:生成式世界模型的算力需求将极其庞大,远超当今的大语言模型。
如果我们简单地将现有视频架构应用于此,要以60fps的帧率生成一个交互式的4K视频流,每秒需要生成超过10万个token(大约相当于《弗兰肯斯坦》或第一本《哈利·波特》的长度)。
而要在一小时或更长的交互中维持这些内容的持久性,则需要处理超过1亿token的上下文窗口。
以当今的计算基础设施而言,这既不可行,也不具备经济效益。
团队坚信「苦涩的教训」(The Bitter Lesson):在AI领域,那些能随着算力增长而平滑扩展的简单方法往往会占据主导地位,因为它们能受益于数十年来驱动所有技术进步的、呈指数级下降的计算成本。

生成式世界模型恰好能从未来算力成本持续降低的趋势中获得巨大优势。
这自然引出一个问题:生成式世界模型是否会受限于当今的硬件瓶颈?或者说,我们是否有办法在今天就一窥这项技术的未来?
高效性:将未来提前带到眼前
对此,李飞飞团队设定了一个简单的目标:设计一个足够高效、可在当前部署,并能随算力增长而持续扩展的生成式世界模型。
而更为宏大的目标是:构建一个能在单块H100 GPU上部署的模型,既要保持交互式帧率,又要确保世界无论交互多久都能持久存在。
实现这些,将让我们得以将未来愿景呈现在当下,通过今天的体验一窥这类模型在未来的巨大潜力。
而这一目标,也影响了从任务设定到模型架构的整个系统设计。
为此,团队精细优化了推理堆栈的每一个环节,应用了架构设计、模型蒸馏和推理优化等领域的最新进展,力求在今天的硬件上,以最高保真度预览未来模型的样貌。
可扩展性:将世界模型视为「学习型渲染器」
传统的3D图形管线使用显式的3D表征(如三角网格、高斯溅射)来对世界进行建模,再通过渲染生成2D图像。它们依赖于人工设计的算法和数据结构来模拟3D几何、材质、光照、阴影、反射等效果。
这些方法作为计算机图形学领域数十年来可靠的支柱,却难以随数据和算力的增长而轻松扩展。
相比之下,RTFM则另辟蹊径。
它基于生成式视频建模的最新进展,训练一个单一的神经网络。该网络仅需输入场景的一张或多张2D图像,便能从新的视角生成该场景的2D图像,而无需构建任何显式的3D世界表示。
RTFM的实现是一个在帧序列上运行的自回归扩散Transformer。它通过对大规模视频数据进行端到端训练,学会在给定前序帧的条件下预测下一帧。
RTFM可被视为一个「学习型渲染器」——
- 输入的帧被转换为神经网络的激活值(即KV缓存),从而隐式地表征了整个世界;
- 生成新帧时,网络通过注意力机制从这一表征中读取信息,从而创建出与输入视图一致的世界新视图。
从输入视图到世界表征的转换,再到从表征渲染新帧的整个机制,均通过数据进行端到端学习,而非人工设计。
RTFM仅通过在训练中观察,便学会了模拟反射、阴影等复杂效果。
|
|
|
|




可以通过将RTFM与Marble相结合,由单张图像创建3D世界。RTFM能够渲染光照和反射等复杂效果,这些都是端到端地从数据中学习得到的
RTFM打破了重建(在现有视图之间进行插值)与生成(创造输入视图中未见的新内容)之间的界限,而在计算机视觉领域,这两者历来被视为独立问题。
当为RTFM提供大量输入视图时,由于任务约束更强,它更倾向于重建;而当输入视图较少时,它则必须进行外推和想象。
|
|
|
|




可以使用RTFM从短视频中渲染真实世界的场景
持久性:以带位姿的帧作为空间记忆
真实世界的一个关键属性是持久性:当你移开视线时,世界不会消失或彻底改变;无论你离开多久,总能回到曾经到过的地方。
这对于自回归帧模型而言一直是个挑战。
由于世界仅通过2D图像帧被隐式表征,要实现持久性,模型就必须在用户探索世界时,对一个不断增长的帧集合进行推理。这意味着生成每个新帧的成本都比前一个更高,因此模型对世界的记忆实际上受限于其算力预算。
RTFM通过为每个帧建模一个在 3D 空间中的位姿(位置和方向)来规避此问题。
团队通过向模型查询待生成帧的位姿来生成新帧。这样,模型对世界的记忆(包含在其帧中)便具有了空间结构;它使用带位姿的帧作为一种空间记忆。
这为模型赋予了一个弱先验——即它所建模的世界是一个三维欧几里得空间——而无需强迫它明确预测该世界中物体的3D几何形状。


RTFM配合「上下文调度」技术,使其能在大型场景中保持几何形状的持久性,同时维持高效
RTFM的空间记忆实现了无限的持久性。
在生成新帧时,会通过从带位姿帧的空间记忆中检索附近的帧,为模型形成一个自定义的上下文。
团队将这种技术称为「上下文调度」(context juggling):模型在空间的不同区域生成内容时,会使用不同的上下文帧。
这使得RTFM能够在长时间的交互中保持大型世界的持久性,而无需对一个不断增长的帧集合进行推理。
展望未来
RTFM将未来提前带到眼前,让我们看到了未来世界模型在当今硬件上部署的雏形,并为「将世界模型视为从数据中端到端学习的渲染器」这一理念设定了技术路线。
扩展RTFM有许多激动人心的方向。比如,通过增强使其能够模拟动态世界,并允许用户与生成的世界互动;同样,它也非常适合扩展。
当前的模型目标是在单块H100 GPU上实现实时推理,李飞飞团队期待,面向更大推理预算的更大型号模型将持续带来性能提升。


