在大语言模型后训练阶段,强化学习已成为提升模型能力、对齐人类偏好,并有望迈向 AGI 的核心方法。然而,奖励模型的设计与训练始终是制约后训练效果的关键瓶颈。
目前,主流的奖励建模方法包括 “基于偏好的奖励建模”(Preference-based Reward Modeling)和 “基于规则的验证”(Rule-based Verifier)两种方法。
其中,“基于偏好的奖励建模” 一般利用标注的偏好对数据来训练奖励模型,这种方法存在着诸多局限。首先,高质量偏好数据的获取成本极高,难以大规模扩展;其次,这种基于 “主观绝对偏好” 的奖励建模面对新任务时表现不佳,泛化能力有限,极易受到 “奖励黑客”(Reward Hacking)的影响。这些问题严重制约了奖励模型在大模型后训练阶段的实际落地。
随着 Deepseek R1 等推理模型的成功,“基于规则的验证” 强化学习方法(RLVR)迎来了广泛应用。RLVR 会依赖给定问题的标准答案或预期行为给出奖励,从而保证了奖励信号的准确性。因此,RLVR 尤其适用于数学推理、代码生成等具有明确评价标准的 “可验证” 任务。然而,在真实世界中,大量任务难以用规则简单验证,如开放域对话、写作、复杂交互等。这导致基于规则的验证方法难以扩展到更通用的场景。
基于偏好的奖励建模难以扩展和泛化,基于规则的验证难以满足通用场景的需求。那么,究竟什么才是扩展方便、泛化性强、场景通吃的奖励建模方案呢?
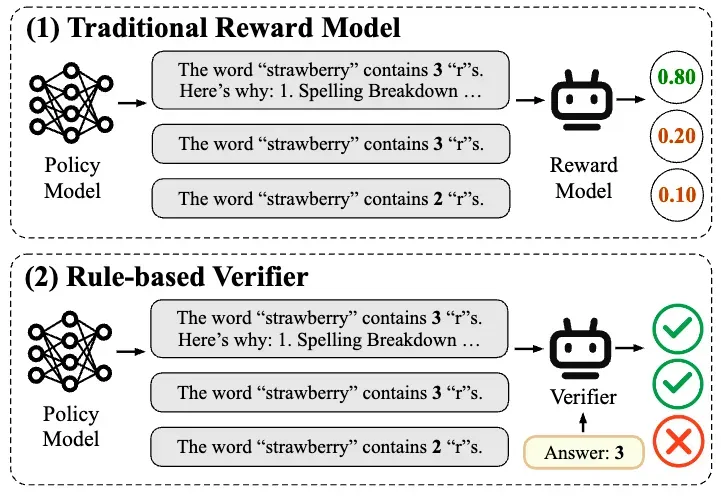
图一:传统的奖励模型和基于规则的验证器
回顾大模型(LLM)的成功之路,是利用 Next Token Prediction 的形式统一了所有任务,解决了任务形式不同导致无法泛化的难题。而奖励模型(RM)的设计仍然在重蹈传统方案的老路,即为特定场景标注偏好数据,训特定场景的 RM。因此,是否可以仿照 LLM 的成功之路,重新设计 RM 的训练范式呢?消除 RM 的 “打分标准”,就像消除 LLM 的 “任务形式” 一样,找到一个脱离于 “打分标准” 之外的更本质的优化目标函数来进行预训练,从而达到真正的通用性。
近期,上海人工智能实验室邹易澄团队联合复旦大学桂韬团队推出了预训练奖励模型 POLAR,找到了一种与绝对偏好解耦的、可以真正高效扩展的奖励建模新范式:策略判别学习(Policy Discriminative Learning, POLAR),使奖励模型能够像大语言模型一样,具备可扩展性和强泛化能力。POLAR 为大模型后训练带来突破性进展,有望打通 RL 链路扩展的最后一环。

- 论文链接:https://arxiv.org/pdf/2507.05197
- 项目链接:https://github.com/InternLM/POLAR
- 模型链接:https://huggingface.co/internlm/POLAR-7B
POLAR 是什么?—— 与绝对偏好解耦的策略判别学习
在强化学习中,策略优化实际上是一个不断调整策略分布、使其逐步接近最优策略分布的过程。因此,当前的候选策略与最优策略之间的 “距离” 可以被视为一种潜在的奖励信号:当候选策略越接近最优策略时,奖励函数应当给予越高的奖励,从而引导策略进一步向最优方向收敛。
通过衡量候选策略与目标最优策略之间的 “距离”,我们可以建立一种不依赖于人类绝对偏好的奖励建模方式,使奖励模型摆脱 “绝对的好坏”,而是为更接近目标策略的候选策略赋予更高的奖励分数。由于 “距离” 是一种相对性的概念,因此目标策略可任意指定,从而摆脱了对偏好数据人工标注的依赖,具有极强的可扩展潜力。具体而言,POLAR 利用从候选策略采样的轨迹(trajectories)来近似候选策略的分布;同时,以参考轨迹(demonstrations)来近似最优策略分布。通过衡量轨迹之间的差异来近似衡量策略分布之间的距离。
对于 “距离度量”,经典的方案有 “对比学习”(Contrastive Learning),通过构造正负样本来训练模型(如 CLIP)。POLAR 就是一种利用对比学习来建模策略分布之间 “距离” 的训练方案。至此,还剩下一个最关键的问题:正负例如何定义?
不论是候选策略的采样轨迹,还是代表最优策略的参考轨迹,直接用来近似策略分布都会造成一定的偏差,因此我们不能单纯基于单个轨迹来衡量两者的样本相似性。例如,在数学场景中,如果候选策略输出的答案与参考相同,可以说明此策略质量较高;但是,在写作等多样性较高的场景中,如果候选策略每次输出的都与标准答案相同,反而说明此策略质量不好。因此,“轨迹是否相似” 无法成为无偏的判断标准。
对此,POLAR 采用了另一种方案:同一个策略生成的轨迹作为正例,不同策略生成的轨迹作为负例。这一判断标准虽然有一些反直觉,但它是一种真正无偏的信号,和对抗生成网络(GAN)中判断是否是真实样本类似。我们可以把策略模型看作是某个分布的无偏采样器,虽然单次采样可能会产生正负例相反的噪声,但是当采样规模增大,大规模扩展数据时,分布间的差异和距离会被刻画得越来越精确。
如图二所示,POLAR 的预训练阶段采用上述对比学习方案进行大规模扩展。由同一个模型输出的一对样本作为正例,由不同模型输出的样本作为负例,从而让奖励模型学会区分策略分布,而非建模人类的绝对偏好。这一阶段无需任何的人类偏好数据。在第二阶段的 SFT 微调中,才引入少量的偏好数据对齐到人类偏好。
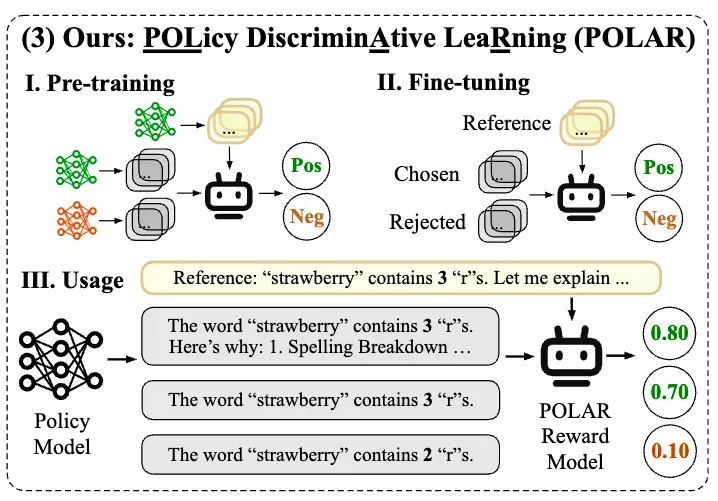
图二:策略判别学习(Policy Discriminative Learning)
POLAR 如何训练?—— 预训练和偏好微调
POLAR 的预训练语料完全通过自动化合成数据构建。具体而言,从 LLM 预训练语料中采样出大量的文本前缀,并从策略模型池(由开源的 131 个 Base LLM 和 53 个 Chat LLM 组成)中随机取模型进行轨迹采样。预训练目标使用 Bradley-Terry Loss:
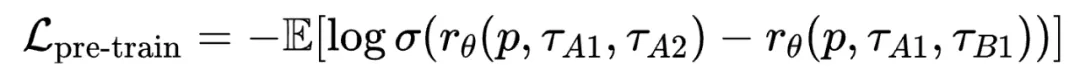
其中,A1 和 A2 代表相同策略模型生成的轨迹(正样本对);B1 代表不同策略模型生成的轨迹(负样本)。通过这种方式,POLAR 使 RM 学会为相近策略产生的轨迹赋予更高奖励,从而隐式建模策略分布的差异和距离。在这一阶段,POLAR-1.8B 共使用了 0.94T Token 的预训练数据,POLAR-7B 共使用了 3.6T Token 的预训练数据。
在微调阶段,POLAR 使用少量的偏好数据对齐人类偏好。对于同一个 Prompt,采样三条轨迹,由人工标注偏好顺序。同样使用 Bradley-Terry Loss 进行微调:
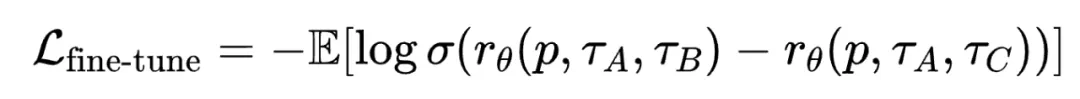
其中,A > B > C,分别代表偏好最优、次优、最差的轨迹。这种偏好排序隐式定义了一种 “策略差异”,例如 A 可以视为从最佳策略分布中采样得到,而 C 可以视为从一个与最佳策略相差较远的策略分布中采样得到。
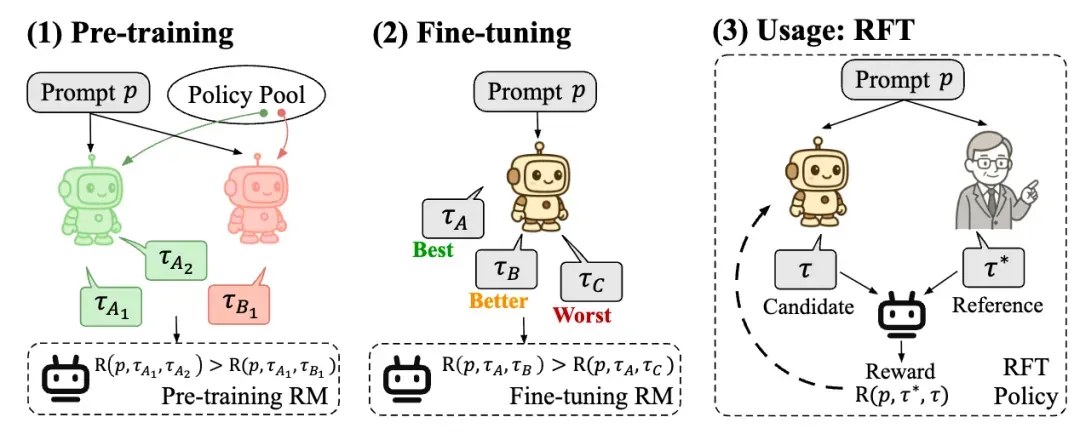
图三:POLAR 的两阶段训练(预训练和偏好微调)以及在 RFT 中的使用方法
POLAR 如何使用?—— 对强化微调的完美适配
强化微调(Reinforcement Fine-tuning,RFT)是 POLAR 的最佳使用场景。
传统的奖励模型建模的是绝对偏好,无法根据参考来打分,难以应用于领域外(Out-of-Domain)场景。RLVR 虽然可以根据参考答案和规则对模型输出进行正确与否的判断,但难以扩展到通用任务。
POLAR 完美适配 RFT 强化学习框架,基于问题的参考答案对模型输出进行打分。如果模型输出与参考答案更为接近,则会获得更高的奖励值。通过这一训练过程,可以使得候选策略逐步向最优策略偏移。
POLAR 效果如何?—— 性能和泛化的双重保证
1. 样例展示:闭式问题和开放问题全搞定
以下分别展示了在闭式问题和开放问题下,POLAR-7B 的打分效果,以分数从高到低呈现。测试例充分考虑了各种陷阱,以及轨迹之间的细微差别,考验其在边界情况下的打分准确性。
- 闭式问题:
问题: 单词 “strawberry” 中有几个 “r”?
参考答案: 单词 “strawberry” 中包含 3 个字母 “r”。我们可以逐字母数一下:“s”、“t”、“r”、“a”、“w”、“b”、“e”、“r”、“r”、“y”。因此,答案是 3。
轨迹一(与参考完全一致):单词 “strawberry” 中包含 3 个字母 “r”。我们可以逐字母数一下:“s”、“t”、“r”、“a”、“w”、“b”、“e”、“r”、“r”、“y”。因此,答案是 3。
分数: -1.5380859375
轨迹二(答案正确,思路正确): 我们来数一数单词 “strawberry” 中有几个 “r”:“s”、“t”、“r”、“a”、“w”、“b”、“e”、“r”、“r”、“y”。这里一共有三个 “r”,因此答案是三。
分数: -2.767578125
轨迹三(答案正确,无思路):单词 “strawberry” 中有 3 个 “r”
分数: -7.45703125
轨迹四(答案错误,思路正确):我们来数一数单词 “strawberry” 中有几个 “r”:“s”、“t”、“r”、“a”、“w”、“b”、“e”、“r”、“r”、“y”。这里一共有三个 “r”,因此答案是二。
分数: -7.6328125
轨迹五(答案正确,思路错误):我们来数一数单词 “strawberry” 中有几个 “r”:“s”、“t”、“r”、“a”、“w”、“b”、“e”、“r”、“r”、“y”。这里一共有两个 “r”,因此答案是三。
分数: -8.65625
轨迹六(答案错误,思路错误):我们来数一数单词 “strawberry” 中有几个 “r”:“s”、“t”、“r”、“a”、“w”、“b”、“e”、“r”、“r”、“y”。这里一共有两个 “r”,因此答案是二。
分数: -9.2890625
轨迹七(答案错误,无思路):单词 “strawberry” 中有 2 个 “r”
分数: -11.921875
- 开放问题
问题:帮我想 3 个形容雨很大的成语,要求不能重复。
参考答案:1. 倾盆大雨 2. 暴雨如注 3. 瓢泼大雨
轨迹一(与参考完全一致):1. 倾盆大雨 2. 暴雨如注 3. 瓢泼大雨
分数:-1.4267578125
轨迹二(正确回答):1. 大雨滂沱 2. 狂风骤雨 3. 大雨如注
分数:-5.234375
轨迹三(与参考相似,多一个):1. 倾盆大雨 2. 暴雨如注 3. 瓢泼大雨 4. 大雨滂沱
分数:-5.6328125
轨迹四(非成语):1. 急雨如瀑 2. 豪雨倾天 3. 雨势磅礴
分数:-5.70703125
轨迹五(与参考相似,少一个):1. 倾盆大雨 2. 暴雨如注
分数:-6.609375
轨迹六(与参考相似,重复一个):1. 倾盆大雨 2. 暴雨如注 3. 暴雨如注
分数:-6.65625
轨迹七(成语正确,少一个):1. 大雨滂沱 2. 狂风骤雨
分数:-6.83203125
轨迹八(成语正确,多一个):1. 大雨滂沱 2. 狂风骤雨 3. 大雨如注 4. 倾盆大雨
分数:-7.0234375
轨迹九(成语正确,重复一个):1. 大雨滂沱 2. 狂风骤雨 3. 狂风骤雨
分数:-7.234375
轨迹十(带雨字成语,一个含义不符):1. 大雨滂沱 2. 狂风骤雨 3. 雨后春笋
分数:-7.26953125
轨迹十一(带雨字成语,两个含义不符):1. 大雨滂沱 2. 雨过天晴 3. 雨后春笋
分数:-8.578125
2. 偏好评估:准确率跃升
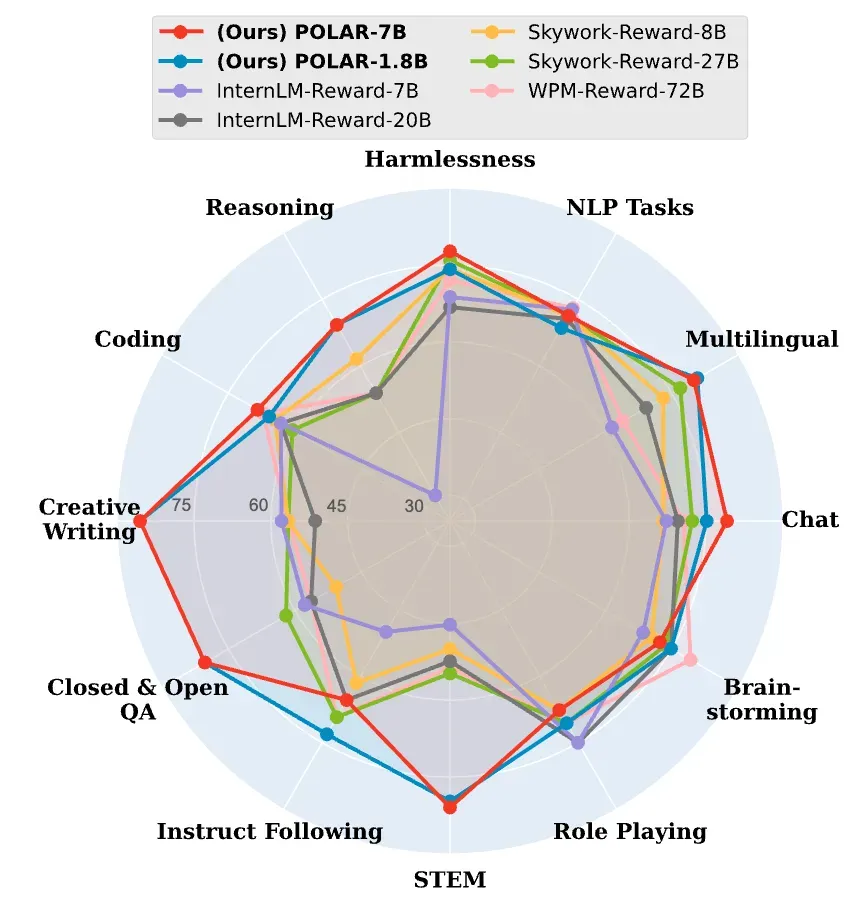
图四:偏好评估实验结果
在偏好评估方面,POLAR 展现出优越的性能和全面性,在大多数任务维度上优于 SOTA 奖励模型。例如,在 STEM 任务中,POLAR-1.8B 和 POLAR-7B 分别超越了最佳基线 24.9 和 26.2 个百分点,并且能够准确识别推理、聊天、创意写作等通用任务中轨迹的细微区别,准确预测人类偏好。值得注意的是,POLAR-1.8B 仅有 1.8B 参数,就可取得与 Skywork-Reward-27B 和 WorldPM-72B-UltraFeedback(参数量分别为其 15 倍和 40 倍)相当的结果,凸显了 POLAR 的强大潜力。
3. RFT 应用:全面增强 LLM 能力
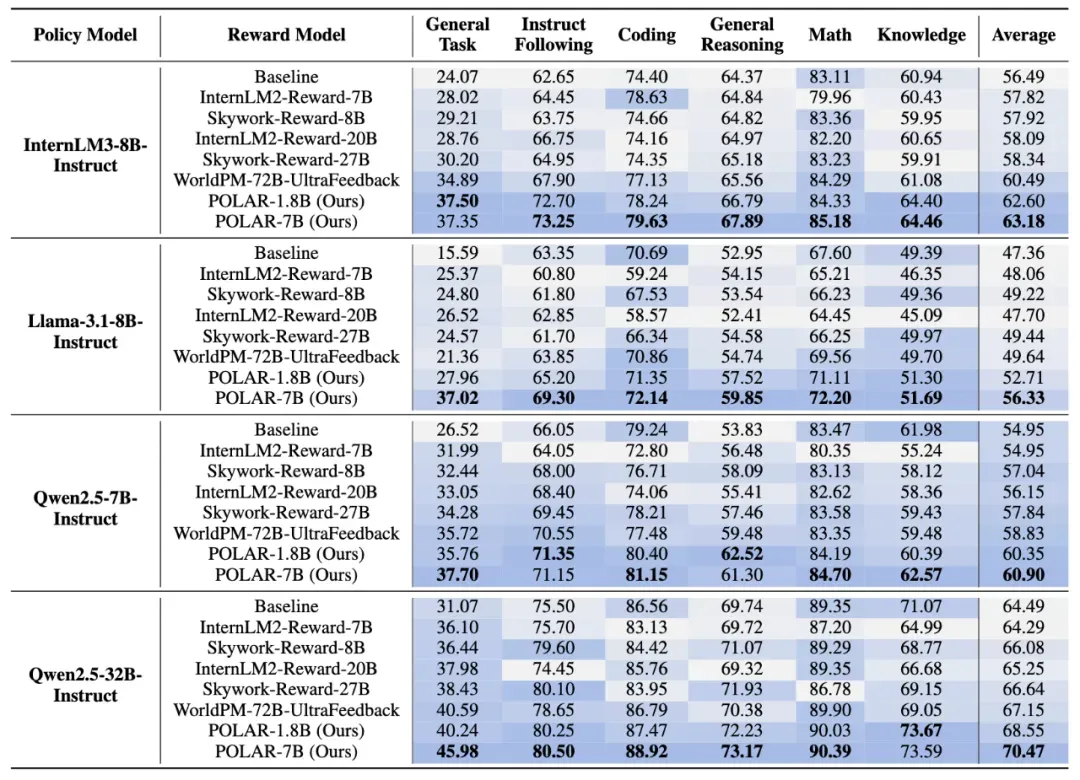
图五:强化微调实验结果
在 RFT 实验中,POLAR 持续优于 SOTA 的开源奖励模型。例如,使用 POLAR-7B 微调的 Llama-3.1-8B 在所有基准测试中,相对于初始结果平均提升了 9.0%,相对于 WorldPM-72B-UltraFeedback 优化的结果提升了 6.7%。POLAR 能够从预训练阶段学习策略模型之间的细微区别,而不仅仅依赖于标注的偏好对,从而显著增强了实际 RL 应用时的奖励信号泛化性。实验结果表明,尽管 POLAR-1.8B 和 POLAR-7B 在偏好评估中表现相似,但在下游 RL 实验中,POLAR-7B 展现出了显著优势。从 1.8B 到 7B 的效果提升,进一步说明了 POLAR 所具有的 Scaling 效应。这也侧面说明了当前传统 Reward Bench 可能存在的局限性,即与真实强化学习场景存在较大的差别。
4. Scaling 效应
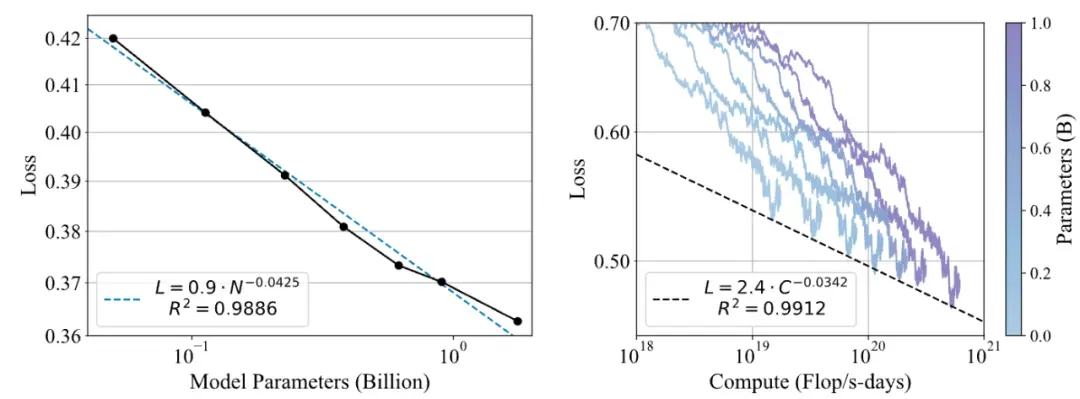
图六:POLAR 的 Scaling Laws
POLAR 展现出了与 LLM Next Token Prediction 目标类似的 Scaling Laws。这进一步体现了 POLAR 无监督预训练方法的巨大潜力。验证集损失随模型参数 N 的增加呈幂律关系下降,拟合的幂律函数为 L=0.9⋅N^−0.0425, R2 值为 0.9886。验证集损失也随最优训练计算量 C 的增加呈幂律关系下降,拟合的幂律函数为 L=2.4⋅C^−0.0342, R2 值为 0.9912。这些结果表明,分配更多的计算资源将持续带来更好的 RM 性能。POLAR 的极佳 Scaling 效应,体现了其用于构建更通用和更强大的奖励模型的巨大潜力。
结语
POLAR 在预训练阶段通过对比学习建模策略间的距离,仅需少量偏好样本就可对齐人类偏好。在使用阶段,POLAR 利用 RFT 范式对 LLM 进行强化学习,展现出了极佳的泛化性。POLAR 作为一种全新的、可扩展的奖励模型预训练方法,为 LLM 后训练带来了新的可能,让通用 RFT 多了一种有效实践方案。有望打通 RL 链路 Scaling 的最后一环。


