
本文第一作者密振兴,香港科技大学计算机科学与技术学院人工智能方向博士生,研究方向是多模态理解与生成,3D/4D 重建与生成,目前正在寻找工业界全职职位或实习职位。
自 Stable Diffusion、Flux 等扩散模型 (Diffusion models) 席卷图像生成领域以来,文本到图像的生成技术取得了长足进步。但它们往往只能根据精确的文字或图片提示作图,缺乏真正读懂图像与文本、在多模 态上下文中推理并创作的能力。能否让模型像人类一样真正读懂图像与文本、完成多模态推理与创作,一直是学术界和工业界关注的热门问题。
OpenAI 的 GPT-4o image generation 和 Google 的 Gemini Pro 用超大规模参数和海量数据,展示了强大的多模态推理与生成能力。但在学术与产业环境中算力和数据并不充裕时,用较少数据与计算资源实现类似的功能,依然是一道难题。
在顶级学术会议 ICML2025 上,香港科技大学联合 Snap Research 提出了多模态理解与生成新方法:ThinkDiff。该方法仅需较少的图文对和数小时训练,就能让扩散模型具备思考能力,使其在复杂的图像文本组合输入下,完成推理式生成,为多模态理解与生成开辟了全新路径。

Paper:I Think, Therefore I Diffuse: Enabling Multimodal In-Context Reasoning in Diffusion Models
Paper link:https://arxiv.org/abs/2502.10458
Github:https://github.com/MiZhenxing/ThinkDiff(in progress)
Project page:https://mizhenxing.github.io/ThinkDiff
ThinkDiff 算法设计
ThinkDiff 这项工作的核心是将现有大规模的视觉语言模型 (VLM) 的推理能力迁移给扩散模型 (Diffusion model)。通过联合 VLM 强大的多模态推理能力和 Diffusion 的高质量生成能力,使得最终的模型能够真正理解图像与文本提示之间的逻辑关系,以此为基础进行高质量的图像生成。
LLM 与 Diffusion 的共享特征空间
最新的 Text-to-image 扩散模型如 Flux 和 Stable Diffusion 3 等,都开始使用大语言模型 (LLM) 例如 T5 的文本编码器 (Encoder) 作为扩散模型的文本编码器 (Text Encoder)。
在这种设计下,扩散模型里的扩散解码器 (Diffusion Decoder) 与 T5 解码器 (LLM Decoder) 共享同一个输入特征空间。只要把 VLM 对图像和文本的推理对齐到该特征空间,就能让扩散模型继承 VLM 的推理能力。
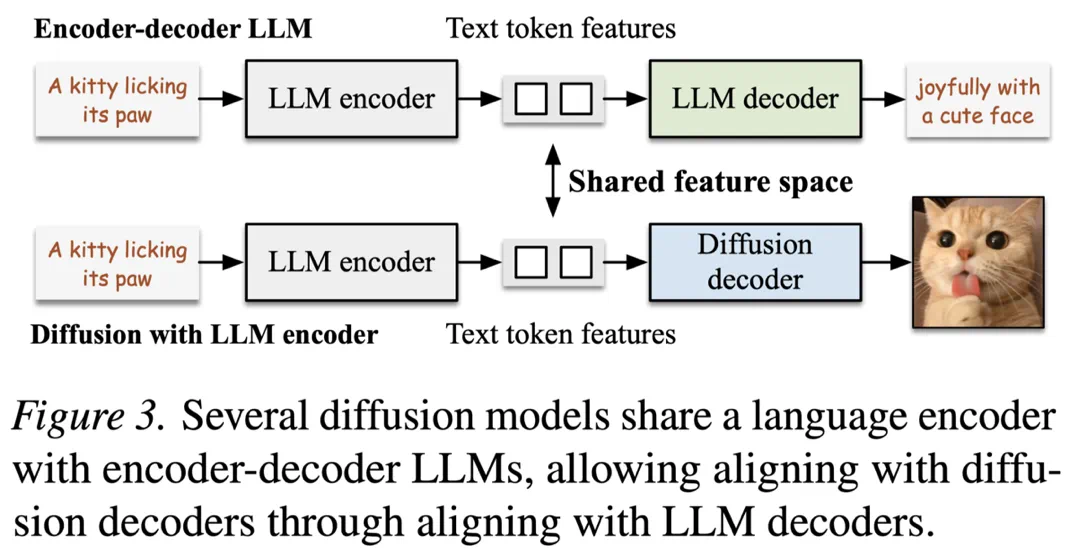
将 VLM 对齐到 LLM 解码器
直接对齐 VLM 与扩散解码器需要大量复杂数据和低效的 Diffusion 训练,因此,ThinkDiff 通过一个代理任务,将 VLM 与 LLM 解码器做视觉-语言训练 (Vision-language Pretraining)。在将 VLM 与 LLM Decoder 对齐之后,由于共享空间的存在,VLM 就自然地与 Diffusion Decoder 对齐。
在训练过程中,对于每个训练样本,ThinkDiff 将图像 + 文本输入到 VLM,自回归 (Autoregressive) 地生成多模态特征向量,再通过一个轻量级的对齐网络 (Aligner),将这些特征向量映射到 LLM 解码器的输入空间,去自回归地重建图像的文字描述,用交叉熵损失进行监督。
经过训练的对齐网络 (Aligner),可以有效地把 VLM 的多模态推理能力传递给了 LLM 解码器。而在推理阶段,只要用同样的对齐网络,通过共享的特征空间,就可以将 VLM 的多模态推理能力传递给扩散解码器,使扩散模型具备多模态理解与生成能力。
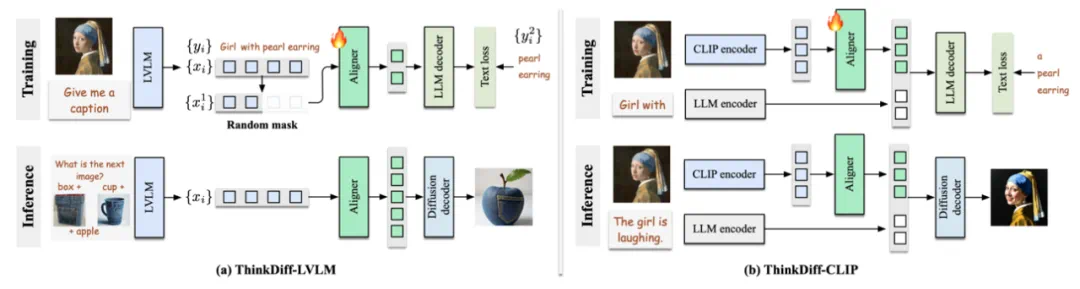
网络结构核心设计
对齐 VLM 生成的 Token:传统 Diffusion 在使用 LLM 时,是将 LLM 当做输入文本的编码器,将得到的特征送入 Diffusion 生成像素。而 VLM 的理解与推理能力,来自于它自回归生成的 tokens,而非编码的输入 tokens。因此在 ThinkDiff 中,我们选择将 VLM (大型视觉-语言模型) 自回归生成的 tokens 的特征对齐到扩散模型,使扩散解码器能够真正继承 LVLM 的多模态推理能力。
掩码训练 (Masked Training):为了避免对齐网络走捷径,而非真正对齐特征空间,ThinkDiff 在训练阶段对 VLM 输出的 token 特征使用随机掩码策略,随机丢掉一部分特征,让对齐网络学会仅从不完整的多模态信息中恢复语义。这种掩码训练使得对齐网络深度理解图像 + 文本,从而高效地将理解能力传递给扩散解码器。
网络变体
依据使用的 VLM 的不同,ThinkDiff 有 ThinkDiff-LVLM 和 ThinkDiff-CLIP 两种变体。ThinkDiff-LVLM 将大规模视觉语言模型 (LVLM) 对齐到 Diffusion,使得 Diffusion 继承 LVLM 的多模态理解能力。ThinkDiff-CLIP 将 CLIP 对齐到 Diffusion,使得 Diffusion 拥有极强的文本图像组合能力。
实验结果
多模态理解与生成定量结果
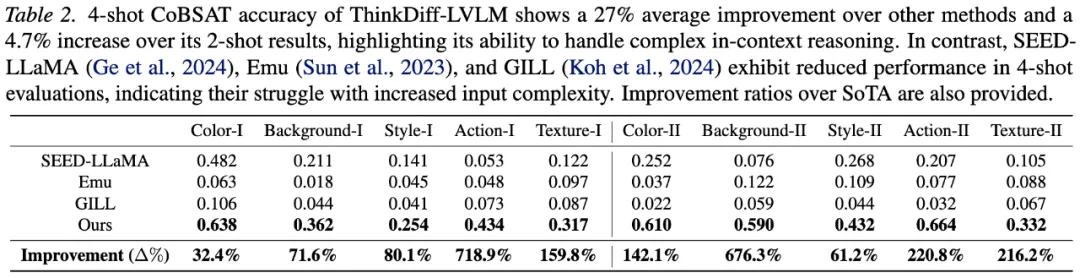
ThinkDiff-LVLM 在多模态理解与生成基准 CoBSAT 上,大幅领先现有方法,展现出高精度高质量的理解与生成能力。

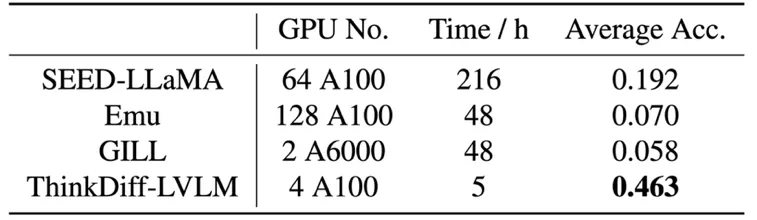
以下是训练资源的对比,与其他使用上百张 GPU 的方法相比,ThinkDiff-LVLM 仅使用 5 小时 × 4 × A100 GPU 的训练,就达到了最优的效果。
多模态理解与生成图片结果
ThinkDiff-LVLM 在 CoBSAT 上,能够对输入的多模态图片与文本进行深度推理,并用高质量的图片展现推理结果。
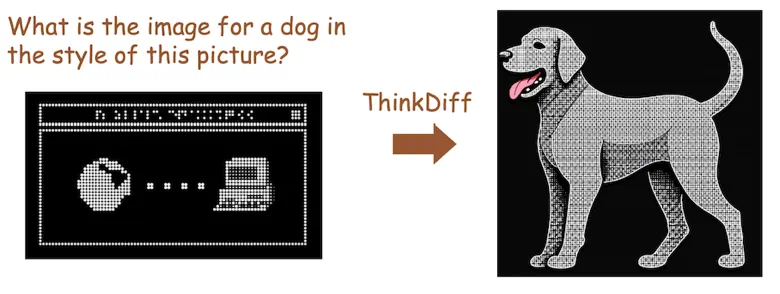
与 Gemini 的对比
ThinkDiff-LVLM 在日常图片推理与生成任务上展现出与 Gemini 类似的能力。
Gemini:
Ours:
多模态组合生成结果
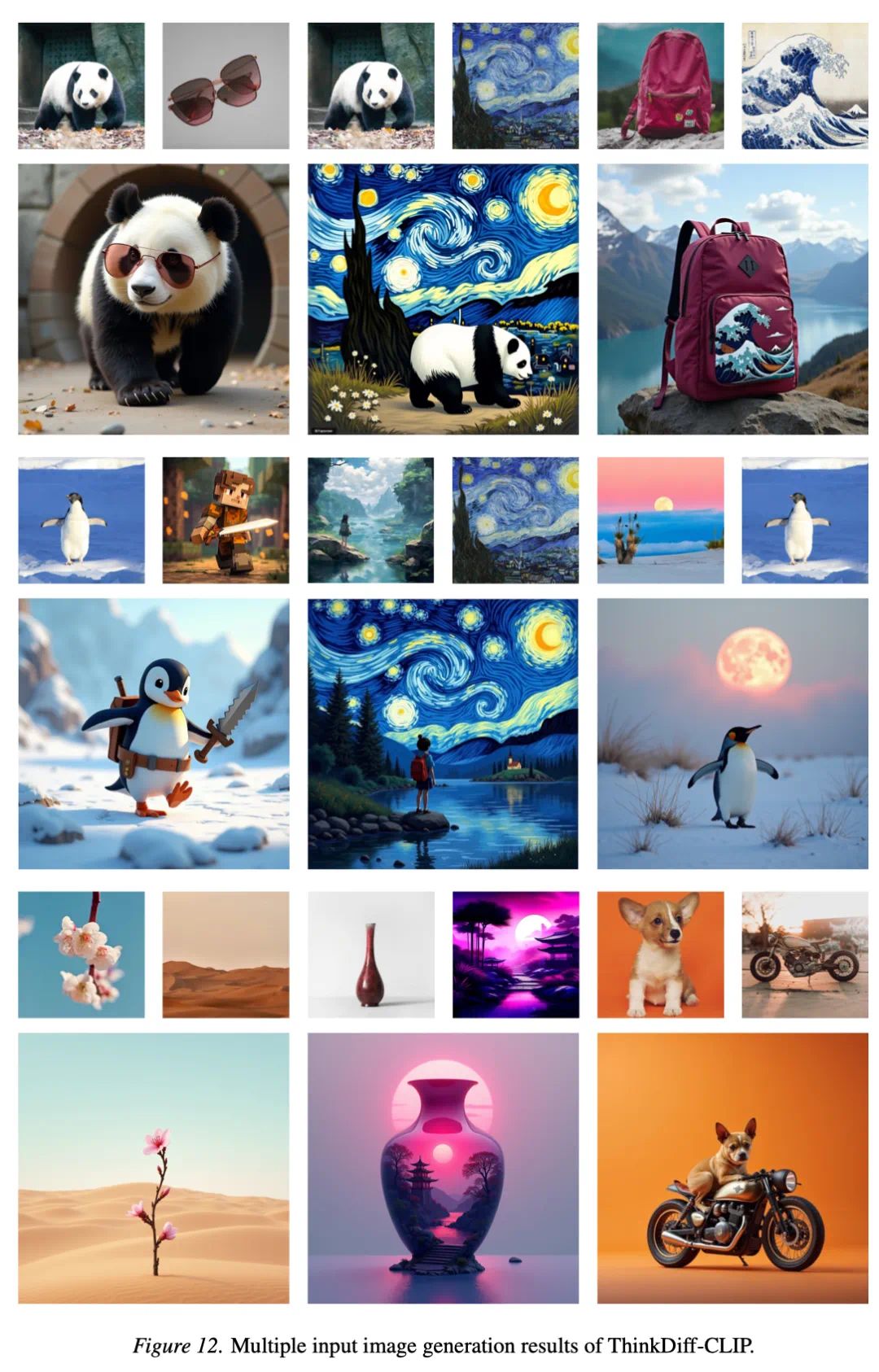
在输入多张图片时,ThinkDiff-CLIP 能够合理地将多张输入图片组合成合理的输出图片。
多模态视频生成结果
将 ThinkDiff-CLIP 的扩散解码器改成 Cogvideo 时,ThinkDiff-CLIP 能在不重新训练的情况下,依据输入的图片和文本,生成高质量的视频。

总结
ThinkDiff 将多模态推理能力传递给扩散模型,创造出高质量的统一多模态理解与生成模型。它用极少的训练资源和常见的数据,让扩散模型具备了在多模态上下文中进行推理和创作的能力。在定量和定性实验上,都优于现有的开源模型,并展现出与商业模型相当的潜力。无论是在科研领域还是工业应用,都对图像生成与理解技术做出重要贡献。


