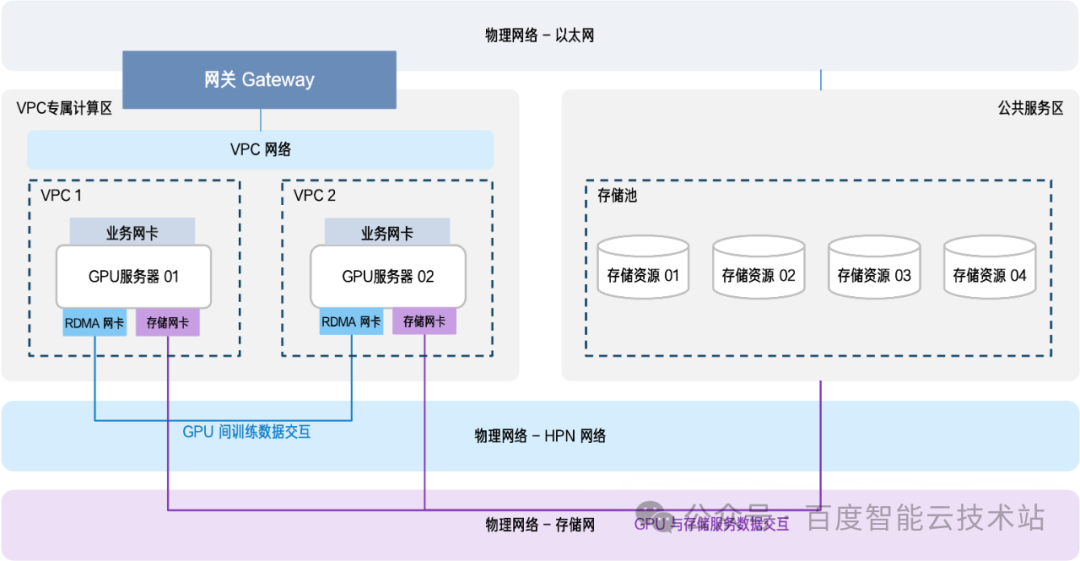
在企业级智算场景中,AI 训练需依托大规模 GPU 集群进行算力输出,同时依赖存储资源池存放训练数据与模型文件等。行业普遍采用「计算 - 存储分区部署」架构 —— 即 GPU 服务器集中部署于专属计算区、存储资源整合为公共存储池。
模型训练过程中需要不断对数据进行读写操作,例如 GPU 集群从存储池加载训练数据集、实时回传训练中间结果、保存训练过程中的 Checkpoint 文件等,因此在分区部署的架构下,计算和 AI 存储之间会产生高频次、大容量的跨区数据交互,跨区通信效率也因此成为决定 AI 训练任务整体性能的关键环节。
目前行业内主流的 GPU 集群与 AI 存储进行数据交互的网络通信方案各有优劣,企业需在性能与成本间艰难取舍:
专用 RDMA 网络
该方案的优势在于性能突出,能充分满足计算集群与存储集群间高带宽、低时延的通信需求,但建设成本极高,需额外采购高性能 RDMA 网卡、专用交换机及低延迟光纤,对企业预算要求苛刻。
 图片
图片
复用现有 VPC 网络
与专用 RDMA 网络方案恰好相反,其核心优势是成本可控 —— VPC 网络主要承载常规业务流量,而智算场景下这类流量负载通常较低,大量带宽资源处于闲置状态。复用 VPC 网络可直接盘活这些沉睡资源,无需额外搭建专网,大幅规避专网建设的巨额开销。但该方案的短板也十分明显:性能受限于 x86 架构网关的转发能力。x86 网关采用软件层面的数据包转发机制,单机处理性能有限(通常不足 50Gbps),无法支撑大规模集群并发读取存储资源的需求。
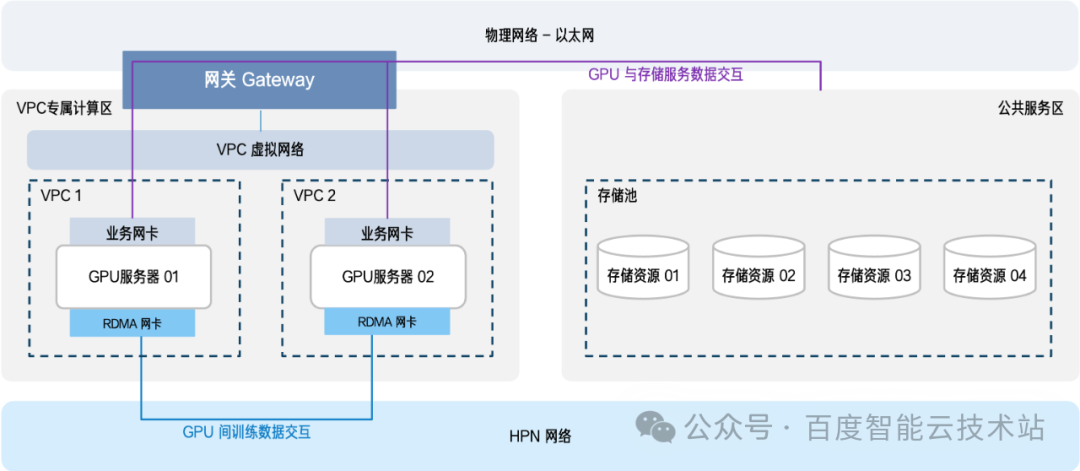
随着大模型参数攀升(如万亿级参数模型),训练数据量呈指数级增长,当多台 GPU 服务器同时访问存储池时,例如 50 台 GPU 集群并发读取,瞬时通信流量可突破 2,500Gbps,此时需通过堆叠数十台 x86 网关弥补性能缺口,不仅推高硬件采购成本,还会增加机房占地、电力消耗与运维复杂度。
某头部车企在智能驾驶研发中便深陷这一困境:其每日产生千万公里级路测数据,新增 50 余台 GPU 服务器需支撑智驾、座舱多模型并行训练,跨区通信带宽需求高达 2Tbps。若采用传统 x86 网关方案,需新购 44 台设备,硬件成本超千万元,且设备维护与故障风险极大。
百度智能云混合云推出的高性能智算网关,恰好打破了企业智算中心建设中「性能与成本不可兼得」的困局,为该车企及众多面临类似问题的企业,提供了智算中心跨区通信「性能无损 + 成本锐减」的破局之道。
1. 破局方案:复用 VPC 架构,依托高性能智算网关实现硬件卸载,赋能智算中心效能飞跃
百度智能云的核心思路,是在复用企业现有 VPC 网络架构的基础上,通过将转发逻辑卸载到高性能智算网关来突破性能瓶颈。该方案依托基于 Tofino 芯片,将原本依赖 x86 服务器软件层面的数据包转发逻辑,全部迁移至专用硬件层面,既保留了 VPC 网络架构简洁、资源利用率高的优势,又通过硬件加速实现通信效能的质变。
1.1. 三大核心优势,重构智算跨区通信体验
高性能:1.6Tbps 吞吐 + 微秒级延迟,破解流量拥堵难题
针对智算场景中大文件块传输(如数据集加载)与高频小请求(如 Checkpoint 保存)并存的复杂流量特征,百度智能云通过动态转发策略优化,实现 「大流量不拥塞、小请求不延迟」。单台高性能智算网关可提供 1.6Tbps 的超大吞吐能力,延迟控制在微秒级,无论是计算集群批量读取存储资源,还是高频次的训练中间数据回传,均能实现「即传即达」,彻底摆脱 x86 网关软件转发的性能桎梏。
低成本:单台顶 22 台,硬件成本直降 95%
以 1Tbps 跨区通信需求为例,传统 x86 网关需 22 台设备才能满足负载,而百度智能云高性能智算网关单台即可承载同等流量。设备数量的锐减,不仅使硬件采购成本降低 95% 以上,还大幅减少机房机柜占用与年度电力消耗,让「高性能智算」不再与「高投入」强绑定。
零门槛:平滑切换无感知,业务训练不中断
考虑到 AI 训练「长周期、不可中断」的特性,百度智能云基于高性能智算网关设计了全流程平滑倒换机制:上线时先通过灰度 IP 发布验证数据通道可用性,再逐步承接现网流量,实现从传统网关的无缝扩容。整个过程路由收敛时间控制在 100 毫秒内,业务全程无感知、无卡顿,完美适配企业连续训练需求。
1.2. 案例验证:头部车企智驾场景的降本增效实践
某头部车企的智能驾驶研发中心,是该方案的典型受益对象。其智算中心采用「计算 - 存储分区部署」模式,随着 50 余台 GPU 服务器的新增,跨区通信带宽需求飙升至 2Tbps,传统 x86 网关方案面临「成本超千万、运维风险高」的双重难题。
百度智能云为其定制的解决方案,核心在于「精准适配 + 平滑过渡」:
- 性能适配:部署 2 台高性能智算网关,总处理能力达 3.2Tbps,不仅满足当前 2,500Gbps 的峰值需求,还预留 30% 余量,可支撑未来 GPU 集群扩容;
- 平滑切换:新网关与传统设备并行运行,先通过测试网段验证传输稳定性,再逐步配置路由承接业务流量,待全量流量监控稳定后下线旧设备。
方案落地后,客户实现了三重核心价值:
- 训练效率跃升:跨区带宽瓶颈破除,数据集加载时间压缩近 90%,整体模型训练周期缩短 22%;
- 成本大幅优化:2 台高性能智算网关替代 44 台传统 x86 设备,硬件成本降低 95%,同时节省 40U 机柜空间与年度数万元电费;
- 业务零中断:升级过程中 50 余台 GPU 服务器的训练任务全程正常运行,无数据丢失、无任务卡顿。
2. 结语:平衡「高性能」与「低成本」,赋能企业 AI 创新
在企业级智算需求持续爆发的当下,能否平衡「高性能通信」与「低成本建设」,已成为企业在 AI 竞争中建立优势的关键。百度智能云混合云的高性能智算网关,通过 「复用现有 VPC + 硬件转发卸载」 的创新思路,将智算场景流量特征深度融入技术架构,既解决了计算 - 存储跨区通信的性能瓶颈,又实现了成本的量级化降低。
若您正面临智算中心跨区通信效率低、成本高的难题,渴望在控制投入的同时释放更大算力价值,欢迎联系百度智能云,为您的 AI 训练场景定制破局提速方案,助力企业在智能时代的竞争中抢占先机。


