作者 | 论文团队
编辑 | ScienceAI
随着大语言模型(Large Language Models, LLMs)推理能力的提升,其在自动化科学发现(Automatic Scientific Discovery)领域的潜力也引发了学术界与公众的广泛关注。AI 领域知名学者何恺明曾在一次访谈中提出一个引人深思的问题:「以当前大模型的智能水平,若将其置于牛顿时代,它能否独立发现牛顿物理定律?」
然而,评估这种能力面临诸多挑战。首先,现实世界中的科学定律已广泛存在于大模型的训练语料中,直接评估难以避免数据泄漏问题。其次,当前的评估方法通常依赖于在静态数据表格中归纳等式,无法真实反映实际科研中通过设计实验获取数据以进行探索性研究的本质。
为此,来自香港科技大学和英伟达的研究者提出了 NewtonBench—— 一个具备强泛化能力、旨在模拟真实实验探索环境的科学定律发现基准(Scientific Law Discovery Benchmark)。

论文地址:https://arxiv.org/pdf/2510.07172
代码地址:https://github.com/HKUST-KnowComp/NewtonBench
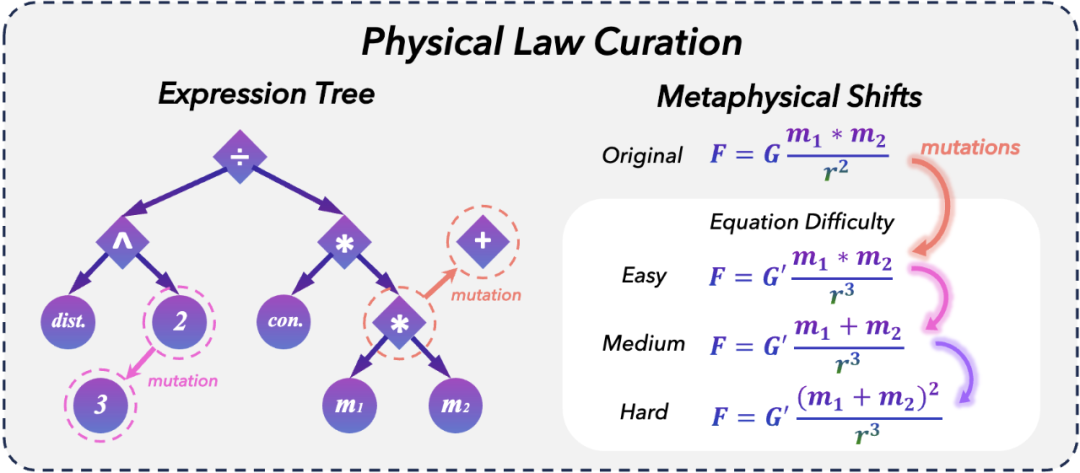
NewtonBench 覆盖了 12 个物理领域,其核心创新在于通过「形而上学变换(metaphysical shift)」将已知物理定律转换为全新的定律,从而有效规避了数据泄漏问题,能够更真实地评估大模型的原始推理能力。
此外,NewtonBench 为每个物理定律的发现过程提供了沙盒化的实验环境。大模型可以在其中自主设定实验参数,执行不同复杂度的实验任务,并从环境中获取反馈数据。这种高度模拟真实科学研究流程的设计,显著提升了评估结果的实际意义。
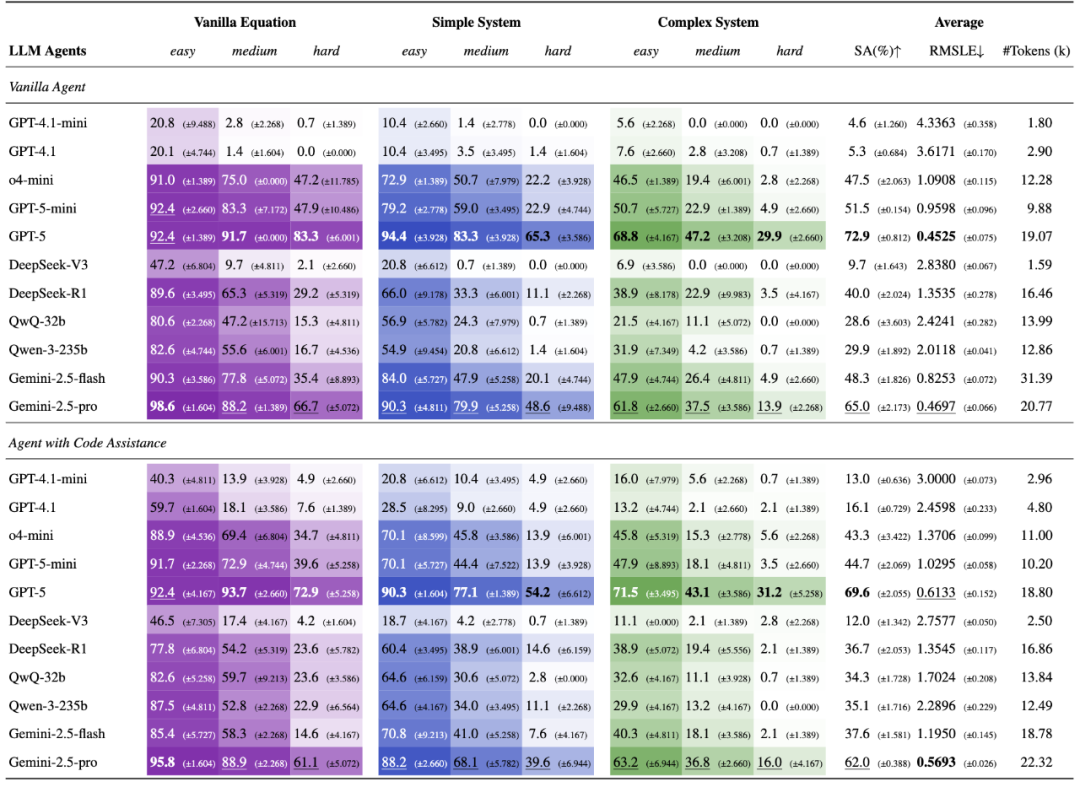
该研究对 11 个领先的大语言模型进行了基准测试,包括 GPT-5、Gemini-2.5-Pro、DeepSeek-R1 和 Qwen-3-235B 等。
评测结果显示,非推理模型(如 GPT-4.1、DeepSeek-V3)表现普遍不佳。而推理模型(如 GPT-5、DeepSeek-R1)则展现出显著差异。在复杂实验环境下,表现最优的 GPT-5 和 Gemini-2.5-Pro 的定律发现准确率分别为 29.9% 和 13.9%,而其他模型的准确率均低于 5%。这充分凸显了强大的推理能力对于科学定律发现的关键作用。
研究还深入分析发现,为模型额外提供代码解释器工具(Code Interpreter Tool) 可以帮助能力较弱的模型突破计算瓶颈,但可能导致能力较强的模型产生过度依赖,反而抑制其自主探索的效率。
目前,NewtonBench 的评测数据集与评测代码已全部开源。
NewtonBench 基准构建
物理法则构建
NewtonBench 包含 324 个物理定律发现任务,覆盖力学、电磁学、热力学等 12 个物理领域。其核心构建方法是:以真实物理定律为基础,在「形而上学变换(metaphysical shift)」框架下,通过等式变换操作(mutation operation)生成衍生定律。根据变换步骤的复杂度及其引入的泛化需求,任务被划分为简单、中等、困难三个难度等级。
实验环境构建
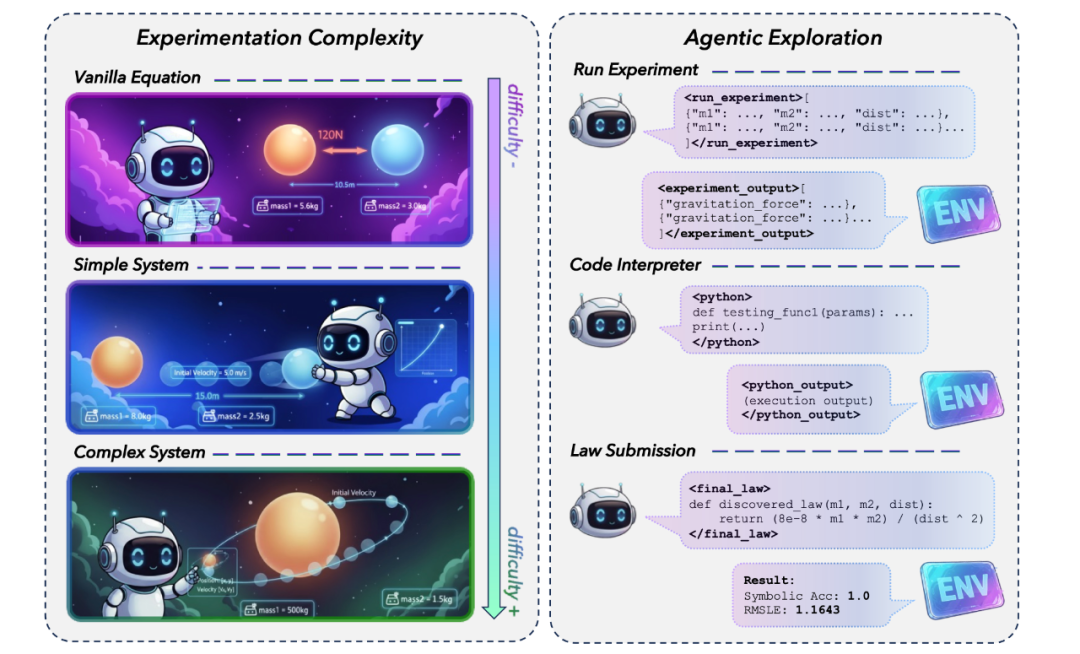
对于每个物理定律,NewtonBench 提供三种不同复杂度的实验环境。在简单实验环境中,实验的输入与输出参数完全对齐目标物理定律的表达形式,接近于理想的符号回归(symbolic regression) 场景。而在中等及复杂难度环境中,目标物理定律仅隐含于部分实验数据中。例如:要求模型通过两个小球沿直线相向运动的观测数据,推导出引力与距离、质量的函数关系。
大模型可通过函数调用(function calling)机制执行实验操作,并从环境动态获取实验结果。模型最多可进行 10 轮实验交互,最终需提交其推导出的物理定律表达式。
实验结果
研究人员对 11 个前沿大语言模型 进行了系统评测,采用符号准确率(Symbolic Accuracy) 和 均方根对数误差(Root Mean Squared Logarithmic Error, RMSLE) 作为核心评估指标。实验结果表明:
1. 非推理模型整体表现欠佳,即使在最简单的实验设定下,其符号准确率也仅处于 20%-50% 的区间;
2. 推理模型(如 GPT-5、DeepSeek-R1)凭借其强大的复杂推理与数学运算能力,在简单场景下的符号准确率普遍突破 80%;
3. 随着实验复杂度提升,推理模型间的性能差距显著扩大。在最具挑战性的「困难定律 + 复杂实验」场景下:
性能领先的 GPT-5 和 Gemini-2.5-Pro 符号准确率分别仅为 29.9% 和 13.9%;
其余模型的准确率均低于 5%,显示出任务难度的陡增特性。
值得注意的是,代码执行工具的辅助效果呈现出显著的分化现象:
对于较弱模型(符号准确率 < 40%),代码工具可带来显著性能提升;
然而对于较强模型,代码辅助均产生负面效应。
这一矛盾现象促使研究人员开展了深度归因分析。
代码辅助效果分析
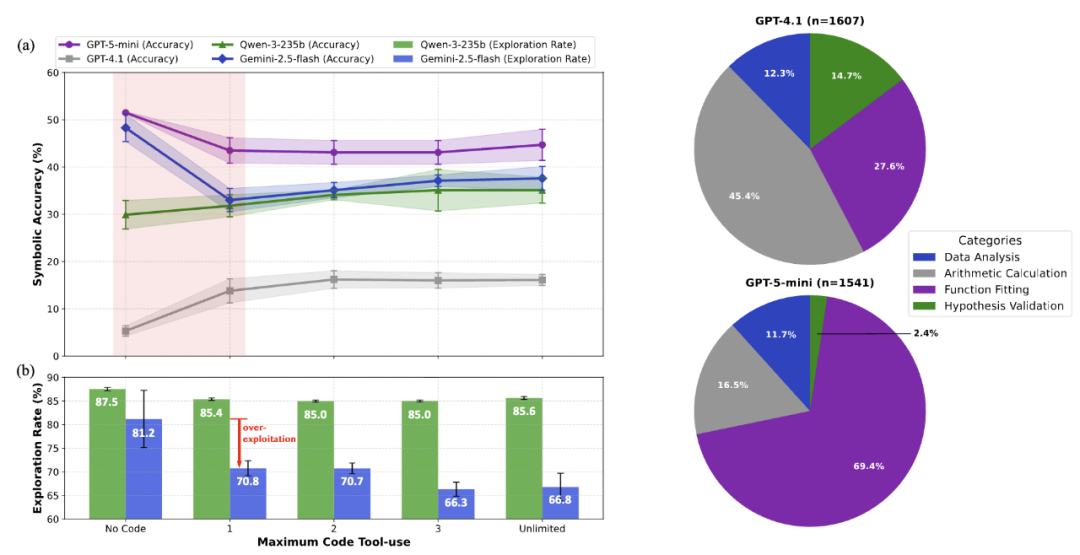
研究人员选取了四个代表性模型(GPT-4.1、Qwen-3-235B、Gemini-2.5-Flash、GPT-5-Mini),通过控制代码调用权限数量展开对比实验。结果显示,当两个高性能模型初步获得代码权限时,准确率均出现显著下滑。进一步分析模型决策文本中的探索(exploration)与利用(exploitation)关键词频发现:性能骤降的 Gemini-2.5-Flash 在使用代码后,探索类词汇出现频率急剧下降;而受益于代码辅助的 Qwen-3-235B 则保持稳定的探索倾向。这表明代码工具的引入导致部分模型发生推理范式偏移 —— 从开放探索转向对代码工具的过度依赖,最终削弱其定律发现能力。
此外,研究人员深度解析了 GPT-4.1 与 GPT-5-Mini 的代码使用模式。在 GPT-4.1 中,45.4% 的代码调用集中于数值计算环节,而该比例在 GPT-5-Mini 中降至 16.5%。与之形成鲜明对比的是,GPT-5-Mini 将 69.4% 的代码资源投入函数拟合(function fitting)过程。这一发现印证了核心观点:对于基础模型,代码工具有效突破其计算瓶颈;但高性能模型将其大量用于快速获取局部最优解,反而抑制了对全局最优定律的探索空间。
总结
NewtonBench 的评测结果系统揭示了当前大模型科学发现能力的核心瓶颈:前沿推理模型虽能推演预设场景中的已知定律变体,但其泛化能力在面对复杂物理定律及实验环境时呈现系统性衰减。
尤为关键的是,代码工具在辅助基础模型突破计算瓶颈的同时,却显著抑制了高性能模型(如 GPT-5 等)的自主探索倾向,致使其陷入局部最优陷阱。这充分表明,现有 AI 的科学发现能力存在内在脆弱性且易受工具范式干扰。
未来研究亟需构建可动态平衡探索与利用的认知架构,并将评估体系拓展至真实科研流程模拟 —— 涵盖未知定律发现、动态实验设计及可证伪性验证,方有望锻造出具备本征科学智能的新一代人工智能系统。