编辑 | 伊风
出品 | 51CTO技术栈(微信号:blog51cto)
“以后用 Copilot 写的代码都不能提交了?”
最近,开源虚拟化项目 QEMU 正式通过了一项新政策,在开发者社区引发强烈震动。
 图片
图片
由 Red Hat 主导的这一重量级项目明确表示:
将拒绝一切由 AI 工具生成,或被怀疑由 AI 工具生成的代码提交。
GitHub Copilot、ChatGPT、Claude、Code Llama 等主流工具,全被点名封杀。
 图片
图片
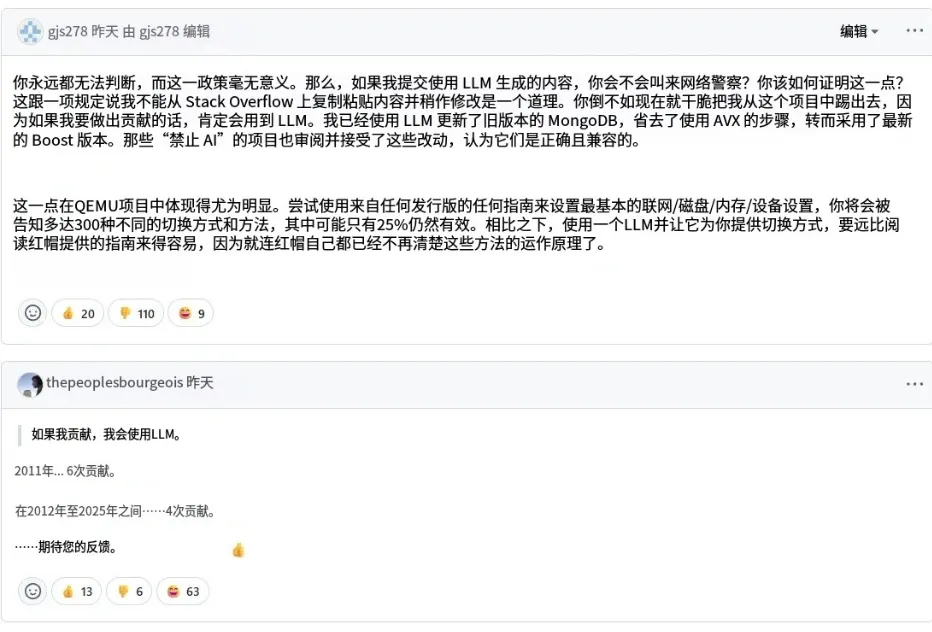
这个决定很快点燃了评论区——一位充满反骨的开发者直接开喷,并表示“将来投稿一定要用LLM”:
“你根本不可能分辨代码是不是用 LLM 写的,所以这项政策毫无意义。你要怎么证明?难道你要叫“网络警察”来抓我?这就跟禁止“复制粘贴 Stack Overflow 的代码并稍作编辑”差不多荒唐。”
这番发言很快被群嘲——不仅被一百多人踩,还被网友扒出从 2012 年到 2025 年只提交过四次代码的“战绩”。
 图片
图片
AI 编程已经卷入无数开发者的日常,许多初学者甚至从第一行代码就开始用 Copilot 辅助。
为什么不少开发者还是支持“封杀”AI编程?
禁用 AI 工具,真的是开源世界的下一场大趋势吗?
1.QEMU 官方表态:AI 代码的法律归属仍属灰色地带
这项新政策由 Red Hat 虚拟化大佬 Daniel P. Berrangé 起草。他是 QEMU 和 libvirt 项目的核心维护者之一。
Berrangé 指出,虽然 AI 代码生成工具日益流行,但它们在法律和许可层面仍处于灰色地带。厂商可能声称输出内容不受限制、许可灵活,但这类表述很可能只是基于利益立场的推广“话术”。
更关键的是,这些模型的训练数据往往来自于大量带有不同开源许可证的项目。而这些训练数据所衍生出的输出,究竟属于谁?是否符合特定项目的开源许可?目前在法律界和开发社区都尚无明确共识。
按照 DCO(开发者证书)规定,贡献者必须保证自己有权以指定许可提交代码。而在当前缺乏共识的前提下,任何声称“AI生成代码符合许可”的承诺,都是站不住脚的。
因此,QEMU 明确提出:暂不接受任何由 AI 工具生成或被怀疑生成的代码提交。
Berrangé 也强调,这一政策是阶段性的。AI 工具未来或许能合法、安全地用于开源项目,但当前环境下,采取谨慎立场更为稳妥。
“最安全的方式,是先从严格开始,之后再酌情放宽。”2.三大关键考量:版权、质量与伦理
QEMU 是开源虚拟化领域的顶流项目之一,长期由 Red Hat 主导开发,体量庞大、架构复杂、社区成熟,是少数能够与 Linux 深度集成、承担底层架构任务的大型项目。
正因如此,QEMU 的政策动向往往具有“风向标”意义,可能波及包括 libvirt、virt-manager、OpenStack 等在内的整条虚拟化工具链。
实际上,QEMU 并不是第一个“封杀 AI 代码”的项目。此前,Gentoo Linux 和 NetBSD 已率先推进类似政策;GNOME 生态中的 Loupe 也明确禁止提交任何 AI 生成内容。
综合这些项目的共识,背后有三大关键考量:
1.代码质量:AI 工具生成的代码常因缺乏上下文理解而逻辑混乱、冗余堆砌,极易造成“代码污染”。这虽然最容易识别,却并非唯一顾虑;
2.版权合规:训练数据来源复杂,生成内容可能“撞脸”原始代码。一旦和特定开源项目高度相似,却未遵循原始许可协议,就可能引发侵权;
举个例子:Linux 社区广泛使用的 GitHub 平台上充满了 GPL 授权代码,而 NetBSD 项目采用的是更宽松的 BSD 许可证。如果 AI 模型无意间“复刻”了某段 GPL 代码并被引入 NetBSD,项目就必须面对两个选项:要么全盘重写,要么重新获得许可。对于人力紧张的小型项目来说,这种代价是不可接受的。
3.伦理风险:大型模型在训练阶段可能使用了未经授权的公共或私人代码,形成对原始创作者劳动成果的系统性“掠夺”。
3.开发者声音:AI 工具滥用,或已导致大量专有代码泄露
在Hacker News上,不少开发者对当前 AI 编码工具的滥用现象表达了深刻担忧,认为这不仅关乎开源精神,更可能引发新一轮“版权灾难”。
一位开发者表示:
开源和自由软件(libre/free software)在未来尤为脆弱——如果 AI 生成的代码被裁定为侵犯版权或归属于公有领域,那么问题就严重了。
同时,相较于开源项目的高曝光度,专有软件中的版权污染风险更隐蔽但更棘手。
因为专有代码很难被外部验证,即使存在侵权行为,也往往难以察觉。而与此同时,许多 LLM 的训练语料库又掺杂了开源项目(特别是 GPL 许可代码),这使得生成内容很可能在“合法性”与“私有性”之间模糊不清。
 图片
图片
另一位开发者也发出警告:
我很确定,大量专有代码其实都掺杂了自由开源软件(FOSS)代码,违反了开源许可证(特别是 GPL 和类似条款)。现在很多专有代码就是用受 FOSS 训练的 AI 写出来的,而且公司对此态度公开。这可能会引爆一堆麻烦(一个“虫洞罐头”)。
 图片
图片
更讽刺的是,虽然公司在合规层面往往会严令禁止员工使用 AI 工具,但在实际工作中,“一边封口,一边照用”的情况并不罕见。正如一位网友在 Hacker News 上所说:
“考虑到在 Hacker News 上有那么多人说他们在用 Cursor、OpenAI 等等处理工作事务,加上我在职场中的亲身经历——公司一边说“绝对不能用”,一边却很多人照用——我怀疑有大量专有代码正在被泄露出去。”
4.写在最后:这是开源的趋势拐点吗?
AI 编程工具正以前所未有的速度融入开发流程,“禁 AI”看似谨慎,却也可能让部分新手开发者望而却步——尤其是那些从一开始就习惯依赖 Copilot、ChatGPT 等工具的年轻人。
在这样的背景下,开源社区如何既守住底线,又不拒绝未来?
这可能不是一朝一夕能够解决的问题。如果要真正实现 QEMU 所说的“在开源项目中合法、安全地使用 AI 工具”,或许需要同时满足多个前提:训练数据的合规化、生成内容的可追溯机制、社区治理的更新,以及更清晰的法律共识与判例支撑。
QEMU 的封禁决议,并非首例,也应该不是终点。
真正的难题,不是要不要使用 AI,而是如何构建一个信任、规则与责任共存的开发新范式。
你怎么看 QEMU 的这项“禁 AI”政策?
如果你是开源项目的维护者,会禁止 AI 生成的代码提交吗?


