
译者 | 朱先忠
审校 | 重楼
通过整合文本、图像、音频等数据,多模态大型语言模型(MLLM)开始突破传统RAG的文本局限,赋予AI感知能力。其核心架构采用CLIP、Whisper等编码器实现跨模态语义统一,通过投影层对齐多模态信息。不过,多模态大型语言模型的评估需要综合检索质量、生成忠实度及跨模态一致性等一系列指标实现。
简介
基于我以前关于LLM、检索增强生成(RAG)和高级RAG技术的文章中的基础概念,本文将着手探讨下一个领域——多模态LLM。
我们将首先揭开多模态LLM核心原理的神秘面纱,探索该领域的突出模型,然后深入研究多模态LLM RAG和关键评估指标的强大组合。
诚然,传统的LLM RAG具有一定的开创性,但也面临着根本的限制,因为它几乎完全以文本为中心。
- 拥有RAG的大型语言模型可以阅读任何文本,但缺乏对物理世界的感知。他们无法直接解读图像、音频或视频。
- 许多现实世界的问题和查询都涉及隐式的视觉或听觉信息。如果用户在提供一张出问题的机器的图片的同时询问“这里出了什么问题?”,纯文本的RAG只能处理文字,而无法处理视觉信息。
- 文本之外还存在大量有价值的信息(例如,医学扫描数据、工程图、监控录像、动物声音)。纯文本的RAG无法直接访问、理解或检索这些丰富的非文本数据源。
- 要将非文本数据与纯文本RAG结合使用,你必须先将其转换为文本(例如,描述图像、转录音频)。这个过程通常会丢失原始模态中固有的关键细微差别和细节。
多模态大型语言模型通过赋予人工智能“感官”解决了这些问题。
- 它们集成了专门的编码器(用于图像、音频、视频等),将非文本数据转换为LLM可以理解和处理的数字表示(嵌入)。
- 然后,融合层将这些多模态嵌入与文本嵌入对齐并组合,从而创建对整个上下文的统一理解。
什么是多模态大型语言模型?
多模态大型语言模型(MLLM)是一种先进的AI模型,能够处理和生成跨多种数据模态的信息。与主要处理文本的传统LLM不同,MLLM可以理解和推理各种类型的数据,例如:
- 文字:书面语言。
- 图像:视觉数据。
- 音频:声音和语音。
- 视频:图像和音频序列。
- 以及可能的其他模式,如传感器数据、热图像等。
与单模态LLM的关键区别在于,它能够跨不同形式的输入进行联合理解和推理,有时还能生成多模态输出。
例如,MLLM可以将图像和文本问题作为输入,并给出关于图像的文本答案。一些高级MLLM甚至可以从文本生成图像,或提供视频的文本描述。
使用多模态大型语言模型(LLM),用户的效率将显著提高,因为他们可以自然地进行交流,就像与拥有多种感官的人类专家交流一样。不同信息类型之间的障碍被消除了。
例如,昨天发生了这样的事:我孩子的自行车链条老是掉,而我又不是自行车修理工。
场景1:使用传统的纯文本大型语言模型(LLM)
你的提问:“我家孩子的自行车链条老是掉。我该怎么修?”
LLM的回答:针对各种可能导致链条脱落的原因(例如,变速器调整、链轮弯曲、链条磨损)提供通用的文字说明。它可能会问一些澄清性的问题,例如“这是单速自行车还是变速自行车?链条松了吗?”,这些问题你可能很难用文字准确回答。
你费力地将自己看到的内容转化为大型语言模型(LLM)能够理解的语言,而大型语言模型却无法理解你看到的内容。你可能会遵循错误的指示,或者陷入困境。
场景2:使用多模态大型语言模型(MLLM)
你的提问:(拍了一张自行车后拨链器和链条的照片,并标出了链条脱落的地方)“我孩子的自行车链条总是掉。通常是在他们换挡的时候。”
多模态大型语言模型的回答:
图像理解:处理图像,将自行车识别为齿轮自行车,注意变速器的类型(例如Shimano Tourney),并目视检查链条张力和对准情况。
文本理解:处理你的文本查询,理解“链条不断脱落”和“当它们换档时”。
融合与推理:结合视觉和文本信息来了解具体问题:换档问题可能与变速器调整或电缆张力有关。
回复:“根据你孩子自行车的图片,它配备了Shimano Tourney后拨,并且在变速过程中链条脱落,最常见的原因是后拨调节不当。你可能需要调整H(高)和L(低)限位螺钉,并可能需要调整线管张力调节器。”
找到变速器背面标有“H”和“L”的两个小螺丝。
对于从外面掉下来的链条(最大的齿轮),你可能需要稍微松开“H”螺丝。
对于朝辐条(最小齿轮)脱落的链条,你可能需要稍微松开“L”形螺丝。
还要使用线管调节器检查线管与变速器连接处的张力。如果你需要更多直观的指导,我还可以为你提供一个简短的视频来演示这项具体的调整。
你可以自然地进行交流(展示和讲述)。MLLM课程能够立即理解具体组件类型,并根据你的具体情况提供精准、可操作的步骤,甚至预测后续需求(视频)。这远胜于通用的指导。
多模态大型语言模型(MLLM)的基础模型
基础模型是大规模通用神经网络,基于海量多样化数据集进行训练,旨在为各种下游应用奠定基础。在机器学习学习模型(MLLM)的背景下,这些模型专门用于处理和生成跨多种数据模态(例如文本、图像、音频,有时还有视频)的内容,从而实现更自然、更多样化的AI交互。
以下给出的是有关几个非常知名的多模态大型语言模型模型的简要总结:

来源:代表性MLLM的时间表
- OpenAI(例如GPT-4o、GPT-4V):实时、语音原生、闪电般快速;擅长对话和交互式应用;被广泛认为是多模态任务中最快、最先进的。
a.GPT-4o(“omni”):OpenAI的最新旗舰产品,专为跨文本、音频和视觉的原生多模态设计,具有令人印象深刻的实时性能。它可以无缝地理解和生成文本、图像和音频。
b.GPT-4V(视觉):GPT-4o视觉功能的前身,允许GPT-4解释和推理作为输入的图像。
- Google DeepMind(例如Gemini):专为多模态设计。Gemini Pro拥有庞大的上下文窗口和强大的跨模态推理能力。支持视频和音频的“长上下文理解”。
a.Gemini:Google功能最强大、原生的多模态模型,全新设计,可理解并操作文本、代码、音频、图片和视频。它提供多种尺寸(Ultra、Pro、Nano)。
- Meta(例如Llama家族-Llama 3、Llama 2):多语言、开源,针对多种语言任务和推理进行了优化;非常适合定制和研究。
a.Llama 3.2的多模态模型(11B和90B)可以处理文本和图像。这些模型可以执行图像字幕、视觉推理以及回答有关图像的问题等任务。它还包含适用于边缘设备的轻量级纯文本模型。
b.Llama 3-V是一个独立的开源多模态模型,其性能可与更大的模型相媲美。
- 阿里云(例如Qwen系列):阿里巴巴推出的一系列强大的开源和专有模型。低延迟、高性能,在代码生成和实时任务方面表现出色;开源灵活性。
a.Qwen-VL:基础视觉语言模型。
b.Qwen-VL-Chat:针对对话功能进行微调的版本,使其更适合交互式多模态应用程序。
- xAI(Grok):与X(Twitter)集成,实时信息处理,独特的“思考”和“深度搜索”模式;擅长掌握最新的世界知识。
a.Grok-1.5V是我们的第一代多模态模型。除了强大的文本处理能力外,Grok现在还可以处理各种视觉信息,包括文档、图表、截图和照片。
- Deepseek(例如Deepseek-V2、Deepseek-Coder):开源,擅长推理和长篇内容,效率高,性价比高;在基准测试和RAG任务中表现强劲。
- Deepseek-VLM将强大的视觉编码器与大型语言模型主干相结合。
多模态大型语言模型(MLLM)架构基础
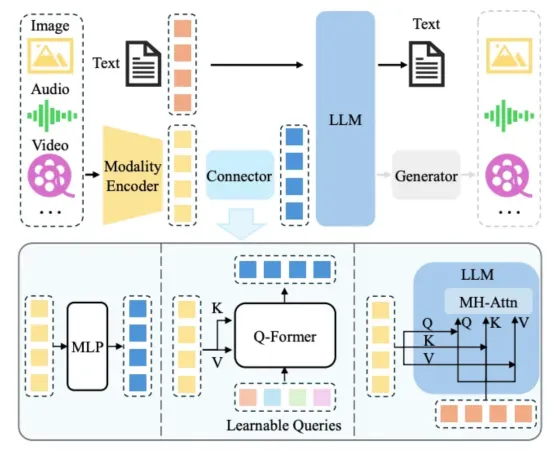
资料来源:多模态大型语言模型
你可以将多模态大型语言模型想象为针对每种来源数据配备专门的“翻译器”,所有信息都输入到中央“大脑”(大型语言模型的核心架构)。
- 当你向它展示图像时,视觉编码器(如视觉转换器)会将像素“翻译”成LLM可以理解的语言——丰富的数字表示(嵌入)。
- 当你播放音频时,音频编码器(如Wav2Vec 2.0或Whisper)会将声波“转换”为数字表示或直接文本。
- 所有这些翻译后的“感官输入”随后被整合到一个融合层(Fusion Layer)中并进行对齐(例如,使用交叉注意力机制,就像C-Former所实现的那样)。这一层帮助大型语言模型(LLM)理解不同信息之间的相互关联(例如,“这只狗叫的声音与这张狗的图像相关”)。
- 最后,LLM强大的生成核心处理这种统一的多模态理解,使其能够根据组合输入生成文本、图像甚至新的音频。
典型的多模态大型语言模型(MLLM)架构可以抽象为以下关键组件:
- 模态编码器:这些是专门的神经网络,负责处理来自不同模态(例如图像、音频、视频)的原始数据,并将其转换为嵌入。其目标是提取与每种模态内容相关的特征。例如:
a.视觉编码器:对于图像输入,通常使用CLIP的Vision、Transformer、ViT或OpenCLIP等模型。这些模型经过预训练,可以将视觉特征与文本描述进行匹配。它们以图像作为输入,并输出一个表示图像内容的固定大小的向量嵌入。
b.音频编码器:对于音频输入,可以使用HuBERT或Whisper等模型。这些模型处理原始音频波形并提取与声音相关的特征,包括语音内容、说话人身份和声学特性。
c.视频编码器:视频编码器通常涉及视觉处理和时间处理的组合。模型可能使用3D、CNN或跨视频帧加入注意力机制,以捕捉空间和时间信息。例如,视频视觉转换器的扩展。
- 预训练大型语言模型LLM:这是大型语言模型MLLM的核心,它是一个基于Transformer的强大语言模型,已在海量文本数据上进行预训练。它在理解和生成自然语言、推理和语境学习方面拥有强大的能力。例如:
a.Llama 3、GPT-3/4、Mistral、Gemini或Claude 3等模型作为LLM的主干,这些模型在预训练阶段学习了复杂的语言模式和世界知识。通过将来自模态编码器的表征输入到这个预训练的LLM中,可以整合多模态特征。
- 模态接口(连接器):这是一个关键组件,它连接了模态编码器(模态特定)的表征与预训练的LLM所需的输入格式(通常是token嵌入)。该接口将不同的模态对齐为一个LLM能够理解和推理的共享表征。例如:
a.投影层:一个简单而有效的接口可以是一个或多个线性层(多层感知器:MLP),它们将视觉、音频或视频编码器的输出嵌入投影到与LLM的词嵌入相同的维度空间中。例如,LLaVA使用线性投影将视觉特征映射到LLM的嵌入空间。
b.Q-Former(查询转换器):与BLIP-2中的用法类似,它包含一组可学习的查询标记,这些标记通过交叉注意力机制与视觉特征进行交互。Q-Former的输出是一个固定长度的嵌入序列,可以输入到LLM中。
- 生成器:一些MLLM被设计用于生成文本以外的模态输出(例如,从文本生成图像)。在这种情况下,一个可选的模态特定生成器会附加到LLM主干上。
例如:
- 图像生成器:像稳定扩散(Stable Diffusion)或DALL-E的解码器部分这样的模型可以用作图像生成器。LLM的输出(以潜在向量或图像标记的形式)可以输入到该生成器中生成图像。
- 音频生成器:类似地,可以使用VALL-E或其他文本转语音模型等模型基于LLM的文本生成来生成音频输出。
三种类型的连接器
模态接口(或称“连接器”)在不同模态信息与大型语言模型(LLM)的整合过程中起着至关重要的作用。一般来说,连接器主要有三种类型:
基于投影的连接器(词元级融合)
这些连接器使用相对简单的变换,通常是线性层(多层感知器:MLP),将来自非文本模态(例如图像嵌入)的特征嵌入投影到与LLM的文本词元相同的嵌入空间中。然后,投影的特征被视为伪词元,并与实际的文本词元连接起来,再输入到LLM中。这实现了词元级的融合,因为LLM的Transformer层像处理常规词元嵌入一样处理这些投影的特征。
- 模态编码器产生特征向量。
- 该向量通过一个或多个投影层(MLP)。
- 投影的输出被视为一系列“视觉标记”(或“音频标记”等)。
- 这些伪标记与嵌入的文本标记连接在一起。
- 标记的组合序列被输入到LLM中。
举例:
LLaVA利用一到两个线性层来投射来自预训练视觉编码器(CLIP的ViT)的视觉特征,使其维度与Vicuna或Llama LLM的词向量对齐。然后,这些投射的视觉特征会被添加到文本输入的前面。
基于查询的连接器(标记级融合)
这些连接器使用一组可学习的查询向量(通常称为Q-Former),与非文本模态编码器使用交叉注意机制提取的特征进行交互。查询向量“查询”视觉、音频或视频特征以提取相关信息。此交互的输出是一个固定长度的嵌入向量序列,然后将其视为伪标记,并与文本标记一起输入到LLM中。这也是一种标记级融合的形式,因为LLM将这些生成的嵌入向量作为其输入序列的一部分进行处理。
- 模态编码器产生一组特征向量。
- 初始化一小组可学习的查询向量。
- 这些查询向量使用交叉注意层来关注模态特征。
- 交叉注意层的输出(更新的查询向量)表示非文本模态的压缩和信息表示。
- 这些查询输出向量被视为“模态标记”序列。
- 这些伪标记与嵌入的文本标记连接并输入到LLM中。
举例:
BLIP-2使用Q-Former,它将冻结图像编码器的输出和一组可学习的查询嵌入作为输入。通过多个Transformer模块(这些模块对查询具有自注意力机制,并在查询和图像特征之间具有交叉注意力机制),Q-Former提取出图像的固定长度表示。然后,这些嵌入被输入到冻结的LLM中。
基于融合的连接器(特征级融合)
与前两种将非文本模态特征转换为标记以便与文本顺序处理的类型不同,基于融合的连接器能够在LLM自身层内实现更深层次的特征交互和融合。这通常是通过在LLM的Transformer架构中插入新层或修改现有的注意力机制来实现的,以允许文本特征与其他模态特征之间的直接交互。
- 模态编码器产生特征向量。
- 文本输入通过LLM的初始层进行处理以获得文本特征嵌入。
- LLM的Transformer模块中引入了专门的融合层(例如交叉注意力层或改进的自注意力层)。这些层允许文本特征在不同的处理阶段关注非文本模态特征(反之亦然)。
- 然后,融合的特征由LLM的后续层进行处理,以进行推理和生成。
视觉转换器
视觉转换器(ViT)是一种神经网络架构,它将Transformer模型的自注意力机制直接应用于图像。与使用卷积层处理图像局部区域的传统卷积神经网络(CNN)不同,ViT将图像视为一系列图像块。
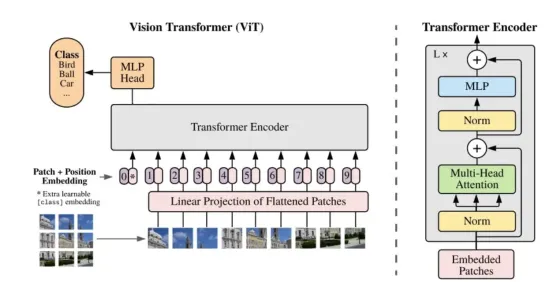
资料来源:用于图像分类的视觉转换器
以下是其工作原理的详细说明:
- 输入图像被分成固定大小、不重叠的方形块网格。
- 每个二维图像块被展平为一维向量。然后,这些展平的块通过线性变换投影到低维空间,从而创建块嵌入。此步骤类似于在自然语言处理(NLP)中将单词转换为标记嵌入。
- 为了保留因展平图像块并将其视为序列而丢失的空间信息,我们在图像块嵌入中添加了可学习的位置嵌入。这些编码为模型提供了图像中每个图像块的原始位置信息。
- 现在,包含位置信息的块嵌入序列将通过标准Transformer编码器进行传输。
该编码器由多层结构组成,每层包含多头自注意力(MSA)和前馈网络(FFN)。MSA机制允许模型关注不同的块,并捕捉它们在整个图像中的关系。FFN则进一步处理这些已关注的特征。
对于图像分类等任务,通常会在序列前面添加一个特殊的可学习分类标记。然后,Transformer编码器与该标记对应的输出会被输入到分类头(通常是一个简单的多层感知器(MLP)中,以预测输出。对于物体检测或分割等其他任务,则使用不同的分类头来处理编码器的输出。
例如:假设你想对一张猫的图像进行分类。ViT会将图像分成多个块(例如,16x16像素)。每个块会被展平并嵌入。位置信息会被添加到这些嵌入中。嵌入的块序列随后会经过Transformer编码器,其中自注意力机制会让模型学习猫的不同部位(例如,耳朵、胡须、尾巴)彼此之间以及与整体图像之间的关系。最后,分类头会使用学习到的表征来确定图像中包含一只猫。
ViT可应用于各种计算机视觉任务,包括:
- 图像分类:将图像分类为预定义的类别(例如,狗、猫、汽车)。
- 物体检测:识别和定位图像中的多个物体。
- 图像分割:根据图像所代表的对象或区域将图像划分为多个片段。
- 动作识别:识别视频中的人类动作。
- 图像字幕:为图像生成文本描述。视觉转换器与卷积神经网络之间的根本区别在于它们捕获空间信息和依赖关系的方法:
- 使用在图像上滑动的卷积滤波器来捕捉局部特征。它们通过逐步将局部特征组合成更深层中更复杂的特征,构建出层次化的表征。CNN对局部性和平移等变性具有归纳性偏好。
- ViT(视觉转换器):将图像视为一系列图像块,并使用自注意力机制捕捉任意一对图像块之间的全局依赖关系,无论它们之间的距离如何。这类模型的归纳偏差较弱,更依赖于大型数据集来学习空间层次和关系。视觉转换器与多模态基础LLM的集成具有以下几个关键优势:
- Transformer提供了一个通用的架构主干,可以处理顺序数据,无论是文本标记还是图像块嵌入。
- ViTs中的自注意力机制使模型能够捕捉图像中的长距离依赖关系和全局上下文。这对于多模态任务至关重要,因为理解整体场景和对象之间的关系对于生成相关文本或回答问题至关重要。
- 与自然语言处理(NLP)类似,视觉训练(ViT)也受益于海量图像数据集的预训练。学习到的视觉表征可以迁移并微调,用于各种下游多模态任务,从而提升性能并减少对特定任务训练数据的需求。
- Transformer以其随着数据和模型大小增加而具有的可扩展性而闻名,这对于构建能够处理现实世界多模态数据复杂性的大型基础多模态模型至关重要。
- 通过将图像和文本嵌入到公共表示空间(通常由Transformer架构实现),多模态模型可以更有效地学习视觉和文本信息之间的关系和对齐方式,从而实现图像字幕等任务,
- 视觉问答和文本到图像生成。
编码器
对于多模态大型语言模型(LLM),使用不同的专用编码器来处理各种数据类型(模态),例如图像、音频、视频和代码。
接下来将给出每种模态的常用模型和技术的详细介绍。
对比语言-图像预训练(CLIP)
CLIP是由OpenAI开发的多模态模型,它通过将视觉概念与自然语言联系起来进行学习。
与传统的图像分类模型(这些模型训练用于预测一组固定的标签)不同,CLIP学习的是图像和文本共享的嵌入空间。这使得它能够理解视觉内容和文本描述之间的语义关系。
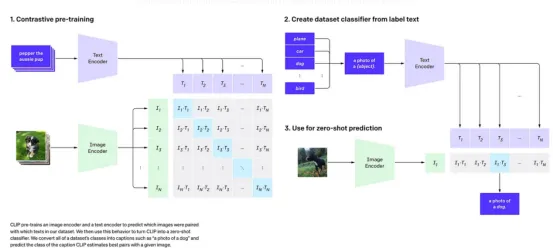
来源:OpenAI博客CLIP
让我们探索一下CLIP的工作原理:
- 双编码器架构:CLIP采用两个独立的编码器网络。
a.图像编码器:该网络将图像作为输入,并将其转换为表示其视觉特征的高维向量。CLIP尝试使用ResNet和VisionT ransformer(ViT)架构作为图像编码器。
b.文本编码器:该网络以文本描述(标题或标签)作为输入,并将其编码为表示其语义的高维向量。CLIP中的文本编码器是一个Transformer模型,类似于GPT等语言模型中使用的模型。
- 共享嵌入空间:CLIP的核心思想是将图像和文本嵌入投影到同一个多维向量空间中。这个共享空间允许模型直接比较图像的表示及其对应的文本。
- 对比学习:CLIP使用对比学习目标,在从互联网收集的4亿对(图像、文本)海量数据集上进行训练。训练流程如下:
a.正样本对:对于批次中的每幅图像,至少有一个正确的文本描述与其关联。该模型旨在最大化图像嵌入与其正确文本描述嵌入之间的余弦相似度。
b.负样本对:对于每幅图像,批次中的所有其他文本描述均被视为不正确。该模型旨在最小化图像嵌入与这些不正确文本描述的嵌入之间的余弦相似度。
同样,这个过程也从文本编码器的角度应用。模型尝试将每个文本描述与其对应的图像进行匹配,并将其与批次中的其他图像区分开来。
- 零样本迁移:基于海量多样化数据集的对比学习方法,使CLIP能够学习到对视觉概念及其与语言关系的丰富理解,从而实现卓越的零样本迁移能力。
- 图像分类:要对具有预定义类别的新数据集执行零样本图像分类,你可以为每个类别创建文本提示(例如,“猫的照片”、“狗的照片”)。然后,对输入图像和所有文本提示进行编码。CLIP会将图像的类别预测为嵌入与图像嵌入具有最高余弦相似度的文本提示。此操作无需对新数据集进行任何微调即可完成。
本质上,CLIP通过理解哪些描述可能属于哪些图像来学习关联图像和文本。这是通过在共享嵌入空间中拉近匹配的(图像,文本)对的嵌入,并拉远不匹配对的嵌入来实现的。
Flamingo
Flamingo由DeepMind开发,是一款基础的机器学习模型(MLLM),因其在广泛的视觉和语言任务中实现的少样本学习(少样本学习)能力而备受关注。与需要针对每个特定任务进行大量微调的模型不同,Flamingo旨在通过利用上下文学习来快速适应新任务,类似于GPT-3等大型语言模型。
让我们来探索Flamingo MLLM的关键方面及其工作原理:
- 视觉编码器:Flamingo使用预训练的视觉编码器,通常是一个使用类似CLIP的对比文本图像方法训练的模型(尽管他们在早期工作中使用了NFNet模型)。视觉编码器的作用是从输入图像或视频帧中提取丰富的语义和空间特征。它获取原始视觉数据并输出一组特征图。
- 感知器重采样器:视觉编码器的输出可以具有可变数量的特征向量,具体取决于输入分辨率和架构。然而,语言模型通常倾向于固定大小的输入。感知器重采样器充当桥梁。它从视觉编码器中获取可变数量的视觉特征,并使用一组可学习的查询向量和交叉注意力机制来输出固定数量的视觉标记。这降低了维度,并为语言模型提供了一致的输入大小。对于视频,感知器重采样器处理来自多个帧的特征,可能结合时间信息。
- 语言模型:Flamingo采用功能强大、经过预训练且已冻结的LLM作为其骨干模型。其初期工作使用了DeepMind开发的Chinchilla系列LLM。这款已冻结的LLM提供了强大的生成语言能力,并能够利用其在文本预训练过程中学到的大量知识。
- 门控交叉注意力密集层(GATE DXATTN-DENSE Layers):将视觉标记与冻结的LLM连接起来的关键创新是引入了新颖的GATED XATTN-DENSE层。这些层交错(插入)在预训练LLM的各层之间。
- 交叉注意力机制:这些层允许语言嵌入关注感知器重采样器生成的视觉标记。这使得LLM能够在预测下一个文本标记时融入视觉信息。
- 门控机制:“门控”方面涉及一个可学习的门,它控制视觉信息对语言处理的影响程度。这有助于模型选择性地整合视觉线索。
- 交错:通过在整个LLM中插入这些交叉注意层,视觉信息可以影响多个阶段的语言生成。
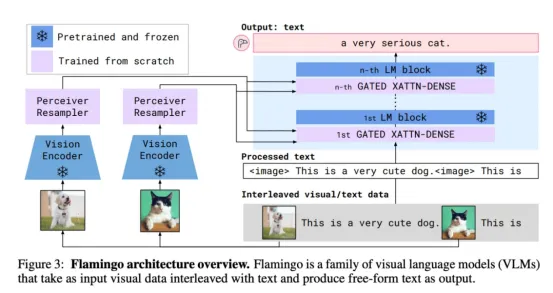
来源:Flamingo
处理流程:
- 输入:Flamingo接收一系列与图像或视频交织在一起的文本标记。文本中可能会添加特殊标签,以指示存在视觉输入。
- 视觉编码:图像/视频由冻结视觉编码器处理以提取特征图。
- 感知器重采样:感知器重采样器将可变的视觉特征转换为固定数量的视觉标记。
- 语言编码:使用冻结的LLM的嵌入层嵌入文本标记。
- 交错处理:文本嵌入和视觉标记的序列被输入到修改后的LLM中。在每个GATEDXATTN-DENSE层:
a.语言嵌入关注视觉标记。
b.所关注的视觉信息用于影响LLM的下一个标记预测。
- 文本生成:该模型根据文本和视觉环境自回归生成文本。
大型语言和视觉助手(LLaVA)
LLaVA(大型语言和视觉助手)是一款端到端训练的大型语言学习器(MLLM),它将预训练的视觉编码器与LLM相结合,以实现通用的视觉和语言理解,以及强大的聊天功能。它的架构相对简单,但功能强大且数据效率极高。
让我们探讨一下LLaVA MLLM的关键方面:
- 视觉编码器:LLaVA采用预训练的CLIP(对比语言-图像预训练)视觉编码器,通常是ViT-L/14模型。CLIP视觉编码器负责处理输入图像并提取高级视觉特征,这些特征已通过CLIP训练与文本概念对齐。它输出图像的固定大小矢量表示。
- 投影矩阵(模态连接器):LLaVA连接视觉和语言的架构核心是一个简单、可训练的投影矩阵(一个全连接层或一个小型多层感知器-MLP)。该投影矩阵从CLIP编码器获取视觉特征向量,并将其映射到预训练LLM的嵌入空间中。目标是将视觉特征转换为语言模型能够理解并与文本输入集成的格式。
- 大型语言模型(LLM)主干:LLaVA使用预先训练的大型语言模型作为其文本处理和生成引擎。LLaVA的原始工作主要使用了Vicuna,这是一个基于LLaMA进行微调的开源聊天机器人。
LLM处理嵌入的文本指令和投射的视觉特征,以生成与文本和图像相关的文本响应。
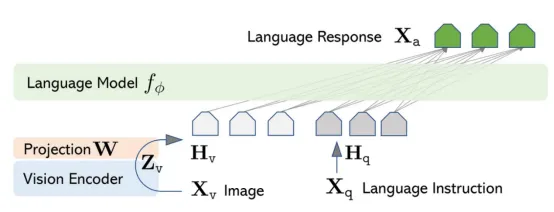
资料来源:LLaVa
处理流程:
- 输入:LLaVA接收由图像和文本指令或问题组成的多模态输入。
- 视觉编码:输入图像经过预先训练的CLIP视觉编码器处理,提取视觉特征向量。
- 投影:将视觉特征向量传入可训练的投影矩阵,使其维度和语义空间与LLM的词向量对齐。这些投影后的视觉特征被LLM有效地处理为“视觉标记”。
- 语言编码:使用LLM的嵌入层对文本指令进行标记和嵌入。
- LLM的多模态输入:嵌入的文本标记和投影的视觉特征被连接(或以其他方式组合)并输入到LLM中。
- 文本生成:LLM处理此组合输入并根据视觉和文本上下文自回归地生成回答问题或遵循指令的文本响应。
训练过程:
LLaVA的训练主要包括两个阶段:
- 特征对齐预训练:在此初始阶段,预训练的CLIP视觉编码器和LLM的权重被冻结。仅训练投影矩阵。该模型在图像-文本对数据集(通常是CC3M的子集)上进行训练,以将视觉特征与语言嵌入对齐。目标是根据投影的视觉特征预测与图像相关的文本。
- 视觉指令调优:在第二阶段,也是至关重要的阶段,整个模型(包括投影矩阵,通常还有LLM)在大规模视觉指令调优数据集上进行微调。
该数据集通常使用GPT-4生成,包含与图像配对的指令以及相应的响应。这些指令涵盖了广泛的任务,包括:
- 对话:关于图像的自然对话。
- 详细描述:生成视觉内容的全面描述。
- 复杂推理:回答需要理解关系并根据图像进行推理的问题。
在此阶段,模型学习遵循涉及理解和推理视觉信息的指令。
C-Former
C-Former是一种专用的模型架构,用于多模态大型语言模型(MLLM),用于处理和编码音频数据,从而实现与文本和图像等其他模态的集成。其设计利用基于Transformer的技术,专门用于捕捉音频信号的独特属性,从而促进与语言模型的有效融合,以用于转录、音频理解或多模态推理等下游任务。
让我们来探索一下C-Former的工作原理:
C-Former通常采用基于Transformer的架构,利用自注意力机制捕捉音频序列内以及跨不同模态的长程依赖关系的能力。以下是其关键方面和处理流程的细分:
音频特征提取
- 原始音频信号首先由专用音频编码器(例如,VGGish、Wav2Vec 2.0、Whisper的音频编码器)处理。
- 该编码器提取一系列低维、语义更丰富的音频特征。这些特征可以是帧级嵌入,用于表示短时间窗口内的声学特性。
音频特征嵌入
- 音频特征序列会经过一个嵌入层。这会将每个音频特征向量投影到与LLM嵌入空间兼容的高维嵌入空间中。
- 位置嵌入通常被添加到音频特征嵌入中,以对音频帧的时间顺序进行编码,类似于它们在Transformers中用于文本的方式。
跨模态注意力(关键组成部分)
- 这就是C-Former真正闪耀的地方。它利用交叉注意力机制,实现音频嵌入与其他模态(例如视觉特征、文本标记)嵌入之间的交互。
- Query、Key、Value:在典型的交叉注意力层中:A.查询可能来自LLM的文本或视觉嵌入。B.键和值来自音频嵌入(或反之亦然,取决于具体的架构)。
- 注意力权重:注意力机制根据查询和键之间的相似度计算权重。这些权重决定了每个音频特征对其他模态表征的影响程度(反之亦然)。
- 语境化的音频表征:通过交叉注意力机制,音频嵌入能够被其他模态的信息进行语境化。例如,如果文本中提到“狗叫”,那么在处理文本时,与狗叫声对应的音频嵌入可能会获得更高的注意力权重。同样,文本表征也可能通过关注相关的音频线索而得到丰富。
融合与整合
- 交叉注意力层的输出(语境化的音频表征)随后会与其他模态的嵌入进行融合。这种融合可以通过连接、元素级运算(加法、乘法)或进一步的Transformer层来实现。
- 目标是创建一个统一的多模态表示,然后LLM可以将其用于多模态理解、生成和推理等下游任务。
音频中的交互(自注意力机制)
- C-Former通常还包含自注意力层,这些自注意力层在交叉注意力之前或同时作用于音频嵌入。这使得模型能够捕捉音频流本身的时间依赖关系和关系,而不受其他模态的影响。
举例
假设向MLLM展示一张狗叫的图像,并听到狗叫声。用户问:“图像中的动物在做什么?”
- 音频处理:吠叫声经过音频编码器,产生一系列音频特征。C-Former嵌入这些特征,并运用自注意力机制来理解吠叫声的时间结构。
- 视觉处理:狗的图像经过视觉编码器,产生视觉特征。
- 跨模态注意力(C-Former):A.视觉特征(作为查询)关注音频嵌入(作为键和值)。这有助于模型理解声音可能与视觉内容相关。B.同时(或在不同的层中),问题的文本标记(“这是什么动物……”)会同时关注视觉和音频嵌入,从而使模型能够将问题置于多模态输入中。当模型关注动作时,与吠叫声对应的音频嵌入可能会获得高度关注。
- 融合:将情境化的音频和视觉表示与问题的文本嵌入融合。
- LLM推理:LLM处理这种统一的多模态表征,并对场景进行推理。它理解图像中包含一只动物(狗),音频表示的是吠叫的动作。
- 答案生成:LLM生成答案:“图像中的狗正在吠叫。”
Wav2Vec 2.0
Wav2Vec 2.0是一个自监督模型,旨在从原始音频波形中学习强大的语音表示。它对语音识别尤其有效,但也可以用作多模态大型语言模型(LLM)中的音频编码器,以提供与文本或其他模态集成的丰富音频嵌入。
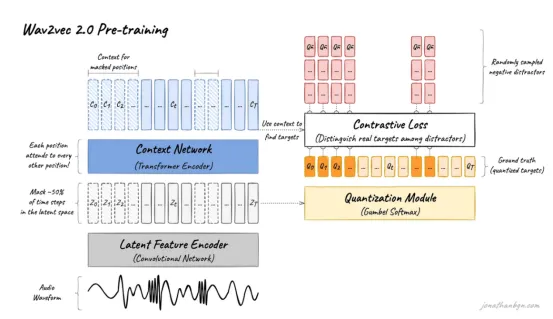
来源:Wav2Vec 2.0
让我们探索一下Wav2Vec 2.0的工作原理:
原始音频输入
- 该模型通常以16 kHz采样的原始音频波形作为输入,而无需傅里叶变换或手工制作的特征等传统预处理。
特征编码器(卷积神经网络)
- 原始波形通过7层1D卷积神经网络(CNN)。
- 该CNN以每个向量约20毫秒的帧速率提取潜在语音特征,将原始音频简化为一系列低维潜在表示Z=(z0,z1,…,zT) Z=(z0,z1,…,zT)。
- CNN每层有512个通道,感受野约为25毫秒的音频,可捕捉局部声学模式。
量化模块(预训练期间)
- 潜在特征被离散化为一组有限的量化语音单元。
- 这种量化作为模型在自监督对比学习期间预测的目标,帮助模型学习没有标签的有意义的语音表示。
上下文网络(Transformer编码器)
- 潜在特征ZZ被输入到Transformer编码器(基础模型为12层,大型模型为24层)。Transformer生成语境化表示C=(c0,c1,…,cT) C =( c0, c1,…, cT ),捕捉超越局部声学特征的长距离依赖关系和语音上下文。
- 特征投影层调整CNN输出维度(512)以匹配Transformer输入维度(768或1024)。
自监督预训练
- 该模型通过掩盖部分潜在音频特征并学习使用对比损失来预测这些掩盖部分的正确量化表示来进行训练。
- 对比学习迫使模型区分真正的量化特征和干扰因素,从而提高表示质量。
下游任务的微调
- 经过预训练后,该模型会根据标记数据(例如,转录)进行微调,以完成自动语音识别(ASR)等任务。
- Transformer的输出CC经过线性投影来预测音素、单词或其他目标。
处理流程:
- 音频输入:以16kHz采样的原始波形。
- 特征提取:CNN特征编码器将波形转换为潜在特征ZZ。
- 上下文编码:Transformer编码器产生上下文化的嵌入CC。
- 投影:上下文嵌入被投影到与LLM兼容的共享嵌入空间中。
- 多模态融合:音频嵌入与其他模态(例如文本嵌入)连接或集成。
- LLM处理:多模态输入由LLM的转换层处理,以执行语音到文本、音频字幕或多模态理解等任务。
- 输出生成:LLM生成最终输出,例如转录、答案或描述。
举例:
输入:包含口语的原始WAV音频文件。
步骤1:加载音频波形并将其重新采样为16kHz。
第2步:波形通过Wav2Vec2.0CNN编码器以获取潜在特征。
步骤3:将潜在特征输入到Transformer中以获得上下文嵌入。
步骤4:嵌入被投影并与任何文本或其他模态输入一起输入到多模态LLM中。
步骤5:LLM处理组合输入并生成转录文本输出,例如“你好,今天我能为你做些什么?”。
为多模态大型语言模型(LLM)提供音频的Whisper
Whisper是由OpenAI开发的开源语音转文本(STT)模型。与主要专注于学习通用音频表示的Wav2Vec2.0不同,Whisper专门针对语音转录和翻译进行了训练。这使得它成为一个强大的工具,可以直接将音频转换为文本,多模态LLM可以轻松理解并处理其他模态的音频。
Whisper的主要特点:
- 多语言和多任务:Whisper在海量多语言语音和配对文本数据集上进行训练,使其能够转录多种语言的音频并将语音从一种语言翻译成另一种语言。
- 对噪音和口音的鲁棒性:大量且多样化的训练数据使得Whisper对各种口音、背景噪音和不同的音频质量具有相对的鲁棒性。
- 直接文本输出:Whisper的主要输出是文本,这与LLM的基于文本的处理自然一致。
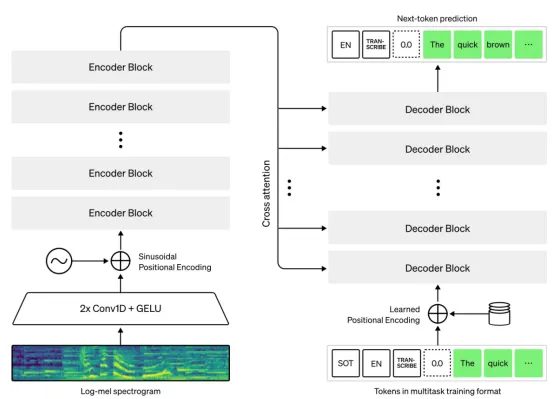
来源:Whisper
让我们来探索一下Whisper的工作原理:
Whisper采用基于Transformer的编解码器架构。其处理流程细分如下:
音频输入
原始音频波形被输入到Whisper模型。
音频编码器(Transformer)
音频首先被处理成一系列对数梅尔频谱图特征。这是音频频率内容随时间变化的标准表示。
这些声谱图特征随后被输入到Transformer编码器中。该编码器利用自注意力机制,学习音频随时间推移的语境化表征。它能够捕捉语音中的长程依赖关系和声学模式。
解码器(Transformer)
- Transformer解码器将编码的音频表示作为输入并生成相应的文本。
- 在解码过程中,该模型根据编码的音频和先前生成的标记,自回归地预测文本序列中的下一个标记。
- 解码器经过训练,可以执行转录(预测与音频相同语言的文本)和翻译(预测不同目标语言的文本)。具体任务通常在解码过程开始时用特殊标记指示。
处理流程:
- 原始音频输入:与多模态输入相关的音频被输入到Whisper模型中。
- Whisper处理:Whisper的编码器将音频处理成声谱图特征,然后再转换成编码表示。解码器随后生成相应的文本转录(或翻译,如果指定)。
- 文本嵌入:Whisper输出的转录文本随后会经过多模态LLM的文本嵌入层。这会将音频的文本表示转换为LLM语义空间中的向量嵌入。
- 跨模态融合:然后,使用交叉注意力等机制将音频的文本嵌入与其他模态(例如视觉特征和其他可能的文本输入)的嵌入融合。这使得LLM能够将语音内容与视觉信息以及其他相关文本关联起来。
- 统一的多模态表示:融合过程创建一个统一的表示,整合来自所有处理模态的信息,包括音频的文本表示。
- LLM处理:LLM处理这种统一的表示来执行诸如理解视频内容(音频和视觉效果)、用口头描述回答有关场景的问题或生成包含视觉和听觉元素的描述等任务。
举例:
假设一个MLLM用户看到一段视频,视频中一个人说“猫在垫子上”,同时还提供了他说话的音频。用户问:“这个人说的垫子上是什么?”
- 音频处理:说话人的音频被输入到Whisper。Whisper将音频转录成文本:“猫在垫子上。”
- 视觉处理:视频帧由视觉编码器处理,提取猫和垫子的特征(如果存在)。
- 文本嵌入:转录的文本“猫在垫子上”通过MLLM的文本嵌入层嵌入到矢量表示中。
- 跨模态融合:音频的文本嵌入与猫和垫子的视觉特征以及问题的文本嵌入(“这个人说了什么在垫子上?”)融合。注意力机制学习将口语与视觉对象关联起来。
- LLM推理:LLM处理统一的表示并理解口语和视觉元素之间的关系。
- 答案生成:LLM生成答案:“这个人说猫在垫子上。”
多模态LLM RAG
多模态LLM RAG是一种先进的方法,它扩展了传统的RAG框架,使LLM能够利用文本以外的多种数据模态来理解、检索和生成信息。这包括图像、音频、视频以及潜在的结构化数据等数据类型。
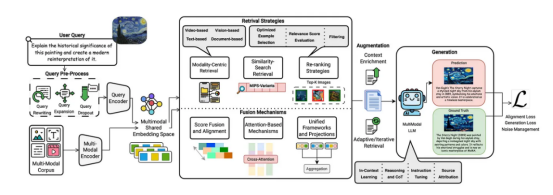
来源:多模态检索增强生成(RAG)流程
多模态LLM RAG所需的组件:
- 多模态数据源:知识库需要存储和索引各种格式的数据(文本文档、图像、音频文件、视频剪辑等)。
- 多模态数据加载器和预处理器:这些组件负责提取和准备用于索引的多模态数据。这可能涉及:
a.从文档中提取文本(包括使用OCR提取图像中的文本)。
b.从图像和视频中提取关键帧或特征。
c.从音频中提取文字记录或特征。
- 多模态嵌入模型:为了跨不同模态进行有效检索,查询和知识库中的数据需要在共享的嵌入空间中表示。这可以通过以下方式实现:
a.联合嵌入模型(例如,CLIP、ImageBind):这些模型可以将文本和图像(有时还有其他模态)嵌入到一个公共向量空间中,在这个空间中,语义相似的项目彼此靠近,而不管它们的原始模态如何。
b.具有对齐的独立编码器:使用特定于模态的编码器(例如,文本编码器和图像编码器),然后学习映射或投影以对齐它们的嵌入。
c.文本描述:为非文本数据(例如图像字幕)生成文本描述,然后使用标准文本嵌入进行检索。
- 多模态向量数据库:向量数据库用于存储和高效搜索多模态数据的向量。它应该支持索引和查询不同模态的向量,最好在同一空间内进行统一检索。
- 检索机制:该组件接收用户查询(也可以是多模态的,例如文本和图像),并根据嵌入空间的相似性,从多模态向量数据库中检索最相关的信息。检索策略可能涉及:a.统一的多模态检索:如果所有模态都嵌入在同一空间中,则单个向量搜索可以检索所有类型的相关内容。b.单独检索和融合:独立检索每种模态的相关内容,然后融合结果。
- 多模态大型语言模型(MLLM):生成过程的核心是一个能够处理来自多种模态信息的MLLM。该模型将用户查询和检索到的多模态上下文作为输入,并生成连贯且相关的响应,该响应也可以采用多种模态(例如文本,有时也包含图像)。MLLM的示例包括GPT-4o、Gemini、LLaVA等。
- 多模态提示设计:在多模态RAG设置中,为MLLM设计有效的提示至关重要。提示需要清晰地指导模型如何使用检索到的多模态上下文来回答用户的查询。
- 多模态RAG的评估指标:评估多模态RAG系统的性能需要合适的指标,这些指标能够评估检索到的上下文以及跨不同模态生成的响应的相关性和准确性。这些指标仍然是一个活跃的研究领域,但可以包括适用于多模态输出的传统RAG指标(例如相关性、忠实度和答案质量)的扩展。
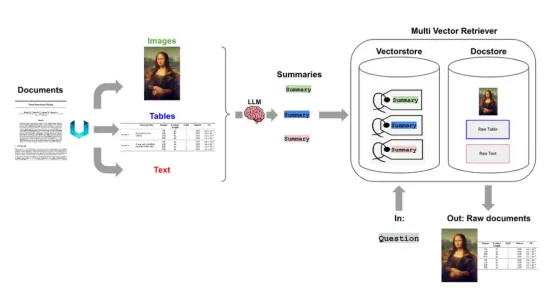
让我们逐步探索多模态RAG系统每个部分的流程。
步骤1:文档加载
这里的目标是从复杂的文档中获取所有原始内容(文本、图像路径、音频路径、表格数据)。
对于混合格式的文档(包含文本、图像、表格、嵌入音频/视频的PDF),你通常需要自定义解析方法,或利用专门的库。
库:
- PyMuPDF(Fitz)用于PDF(提取文本、图像和检测表格)。
- python-docx用于Word文档。
- openpyxl用于Excel。
- BeautifulSoup用于HTML。
- 如果嵌入或引用音频/视频路径,则提取它们的自定义逻辑。
import fitz # PyMuPDF
import re
import os
import camelot
from PIL import Image
def extract_pdf_multimodal_content(pdf_path, output_dir="extracted_content"):
doc = fitz.open(pdf_path)
all_content = []
os.makedirs(output_dir, exist_ok=True)
for page_num in range(doc.page_count):
page = doc[page_num]
page_text = page.get_text()
# 1. 提取文本
all_content.append({"type": "text", "content": page_text, "page": page_num + 1})
# 2. 提取图像
images = page.get_images(full=True)
for img_index, img_info in enumerate(images):
xref = img_info[0]
base_image = doc.extract_image(xref)
image_bytes = base_image["image"]
image_ext = base_image["ext"]
image_filename = os.path.join(output_dir, f"page{page_num+1}_img{img_index}.{image_ext}")
with open(image_filename, "wb") as img_file:
img_file.write(image_bytes)
all_content.append({"type": "image", "path": image_filename, "page": page_num + 1})
# 3. 提取表格
tables = camelot.read_pdf(pdf_path, pages=str(page_num + 1))
for table in tables:
all_content.append({"type": "table", "content": table.df.to_csv(), "page": page_num + 1})
# 4. 提取音频片段
# 这取决于PDF中音频剪辑的引用方式。
audio_links = re.findall(r'https?://\S+\.(mp3|wav|ogg|flac)', page_text)
for link in audio_links:
all_content.append({"type": "audio_link", "url": link, "page": page_num + 1})
doc.close()
return all_content
document_content = extract_pdf_multimodal_content("your_multimodal_document.pdf")
print(f"Extracted {len(document_content)} multimodal chunks.")
print(document_content[:5])
步骤2:多模态分块和预处理
这一点至关重要。你需要将提取的内容分解成适合嵌入和检索的有意义的单元。“有意义”取决于你的具体的使用场景。
- 将每个不同的内容(一个段落、一张图片、一个音频剪辑的转录)保存为一个原子块。
- 至关重要的是,为每个块附加丰富的元数据:原始页码、与其他模态的接近度、原始文件名、类型(文本、图像、音频、表格)。
- 使用基于LLM的分块来确保文本块代表完整的语义思想,而不是任意的标记计数。
- 对于表格,将其转换为LLM可以理解的描述性文本格式(例如,CSV、Markdown或自然语言摘要)。
- 对于音频片段,可以使用STT模型(例如Whisper)将其转录为文本。转录后的文本将被嵌入到搜索中。你还可以存储原始音频路径以供播放。
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_google_genai import ChatGoogleGenerativeAI
from pydub import AudioSegment
from pydub.playback import play # 用于本地音频测试
import io
import base64
import whisper
import google.generativeai as genai
from google.cloud import speech_v1p1beta1 as speech # 用于GCP Speech-to-Text
# 配置 Gemini 进行文本摘要(针对表格)
genai.configure(api_key="YOUR_GEMINI_API_KEY") #确保你的API密钥已设置
llm_for_summarization = ChatGoogleGenerativeAI(model="gemini-pro")
# 配置 GCP 语音转文本客户端
# 你需要进行GCP认证(例如,GOOGLE_APPLICATION_CREDENTIALS)
speech_client = speech.SpeechClient()
def process_multimodal_chunks(raw_content_list):
processed_chunks = []
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_functinotallow=len,
add_start_index=True,
)
for item in raw_content_list:
if item["type"] == "text":
# 文本语义分块
chunks = text_splitter.create_documents([item["content"]])
for i, chunk in enumerate(chunks):
processed_chunks.append({
"type": "text",
"content": chunk.page_content,
"metadata": {
"page": item["page"],
"original_source": "document_text",
"chunk_index": i
}
})
elif item["type"] == "image":
# 对于图像,我们直接传递图像路径或 base64 表示
processed_chunks.append({
"type": "image",
"path": item["path"],
"content_description": f"Image from page {item['page']}: {item['path']}", # 占位符描述
"metadata": {
"page": item["page"],
"original_source": "document_image",
}
})
elif item["type"] == "table":
# 将表格转换为文本。
table_text = f"Table from page {item['page']}:\n{item['content']}"
table_summary = llm_for_summarization.invoke(f"Summarize this table content:\n{item['content']}")
processed_chunks.append({"type": "table_text", "content": table_summary, ...})
processed_chunks.append({
"type": "table_text",
"content": table_text,
"metadata": {
"page": item["page"],
"original_source": "document_table",
}
})
elif item["type"] == "audio_link":
#使用 Google Cloud Speech-to-Text(推荐用于生产环境)
audio_file_path = download_audio_from_url(item["url"])
with io.open(audio_file_path, "rb") as audio_file:
content = audio_file.read()
audio = speech.RecognitionAudio(cnotallow=content)
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
language_code="en-US",
)
response = speech_client.recognize(cnotallow=config, audio=audio)
transcribed_text = " ".join([result.alternatives[0].transcript for result in response.results])
transcribed_text = f"Transcription of audio clip from {item['url']}: [Actual transcription content would go here]"
model = whisper.load_model("base")
result = model.transcribe(audio_file_path)
transcribed_text = result["text"]
processed_chunks.append({
"type": "audio_text",
"content": transcribed_text,
"audio_url": item["url"],
"metadata": {
"page": item["page"],
"original_source": "document_audio",
}
})
return processed_chunks
processed_multimodal_chunks = process_multimodal_chunks(document_content)
print(f"Processed {len(processed_multimodal_chunks)} chunks.")
print(processed_multimodal_chunks[0])
print(processed_multimodal_chunks[1])步骤3:多模态嵌入
这就是多模态检索的神奇之处。你需要一个能够将文本(最好是图像和音频)嵌入到共享向量空间的模型。Gemini在这方面表现出色。
- Gemini的GenerativeModel可以接受混合输入(文本和图像),并生成单个嵌入。对于音频,通常需要嵌入转录后的文本。
- 使用文本嵌入模型(例如text-embedding-004)处理文本/表格/音频转录,并使用视觉编码器(例如CLIP或自定义编码器)处理图像,确保它们的嵌入空间兼容或对齐。准确对齐会更加复杂。
import google.generativeai as genai
from PIL import Image
#配置Gemini
genai.configure(api_key="YOUR_GEMINI_API_KEY")
async def get_gemini_multimodal_embedding(content_type, content, model_name="models/embedding-001"):
"""
使用Gemini生成多模态嵌入。
对于图像来说,“content”应为PIL图像对象。
对于文本来说,“content”应为字符串。
"""
model = genai.GenerativeModel(model_name)
if content_type == "text":
embedding = await model.embed_content(cnotallow=content)
elif content_type == "image":
# 确保“content”是PIL图像对象
embedding = await model.embed_content(cnotallow=content, task_type="RETRIEVAL_DOCUMENT")
else:
raise ValueError(f"Unsupported content type for embedding: {content_type}")
return embedding['embedding']
# 加载嵌入图像的函数
def load_image_for_embedding(image_path):
try:
return Image.open(image_path)
except Exception as e:
print(f"Error loading image {image_path}: {e}")
return None
async def embed_multimodal_chunks(processed_chunks):
embedded_chunks = []
for i, chunk in enumerate(processed_chunks):
embedding_vector = None
if chunk["type"] in ["text", "table_text", "audio_text"]:
embedding_vector = await get_gemini_multimodal_embedding("text", chunk["content"])
elif chunk["type"] == "image":
image_pil = load_image_for_embedding(chunk["path"])
if image_pil:
embedding_vector = await get_gemini_multimodal_embedding("image", image_pil)
else:
print(f"Skipping embedding for corrupted image: {chunk['path']}")
continue # Skip if image couldn't be loaded
if embedding_vector:
embedded_chunks.append({
"chunk_id": f"chunk_{i}", # Unique ID for retrieval
"embedding": embedding_vector,
"original_content": chunk["content"], # Store original text/description
"path": chunk.get("path"), # Store image path
"audio_url": chunk.get("audio_url"), # Store audio URL
"type": chunk["type"],
"metadata": chunk["metadata"]
})
return embedded_chunks
import asyncio
async def main_embedding():
embedded_data = await embed_multimodal_chunks(processed_multimodal_chunks)
print(f"Embedded {len(embedded_data)} chunks.")
print(embedded_data[0])
asyncio.run(main_embedding())步骤4:矢量数据库存储
将你的chunk_id、embedding和metadata字段(包括原始内容、路径、URL)存储在矢量数据库中。
- 专用于生产级的矢量数据库选择方案:Pinecone、Weaviate、Chroma、Qdrant、Milvus。这些数据库都针对大规模矢量搜索进行了优化。
- 它们允许你存储向量以及相关元数据。这些信息对于RAG来说,都是至关重要的。
- 用于开发/测试的本地向量存储。其中,Langchain的FAISS或Chroma(内存/本地持久)都非常适用于快速原型开发。
from langchain_community.vectorstores import Chroma
from langchain_google_genai import GoogleGenerativeAIEmbeddings
import numpy as np
#配置 Gemini 进行嵌入
genai.configure(api_key="YOUR_GEMINI_API_KEY") #确保设置了API密钥
embeddings_model = GoogleGenerativeAIEmbeddings(model="models/embedding-001")
def store_in_vector_db(embedded_chunks, db_path="./multimodal_chroma_db"):
documents_for_chroma = []
metadatas_for_chroma = []
ids_for_chroma = []
embeddings_for_chroma = []
for chunk in embedded_chunks:
text_content = ""
if chunk["type"] in ["text", "table_text", "audio_text"]:
text_content = chunk["original_content"]
elif chunk["type"] == "image":
text_content = chunk["content_description"]
documents_for_chroma.append(text_content)
ids_for_chroma.append(chunk["chunk_id"])
embeddings_for_chroma.append(chunk["embedding"])
metadata = {
"type": chunk["type"],
"page": chunk["metadata"].get("page"),
"original_source": chunk["metadata"].get("original_source"),
}
if chunk.get("path"): # For images
metadata["image_path"] = chunk["path"]
if chunk.get("audio_url"): # For audio
metadata["audio_url"] = chunk["audio_url"]
metadatas_for_chroma.append(metadata)
#首先,初始化一个空的Chroma集合
db = Chroma(
embedding_functinotallow=GoogleGenerativeAIEmbeddings(model="models/embedding-001"),
persist_directory=db_path
)
#添加文档、嵌入和元数据
# 确保所有列表的长度相同
db.add_texts(
texts=documents_for_chroma,
metadatas=metadatas_for_chroma,
ids=ids_for_chroma,
embeddings=embeddings_for_chroma
)
db.persist()
print(f"Stored {len(embedded_chunks)} chunks in Chroma DB at {db_path}")
return db
db = store_in_vector_db(embedded_data)步骤5:多模态检索
当用户提出问题时,你将嵌入他们的查询并使用它来搜索你的矢量数据库。
- 使用相同的Gemini文本嵌入模型嵌入用户的自然语言查询。
- 在矢量数据库中执行相似性搜索以检索最相关的块(可以是文本、图像描述或音频转录)。
- 如果用户的查询本身包含图像或音频,你可以使用Gemini的多模态嵌入功能嵌入整个查询(文本+图像/音频)。这可以实现真正的多模态搜索。
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_community.vectorstores import Chroma
# 确保已经配置好Gemini
genai.configure(api_key="YOUR_GEMINI_API_KEY")
#加载嵌入模型以进行查询
query_embeddings_model = GoogleGenerativeAIEmbeddings(model="models/embedding-001")
def retrieve_multimodal_chunks(user_query, db, top_k=5):
retrieved_docs = db.similarity_search(user_query, k=top_k)
retrieved_multimodal_content = []
for doc in retrieved_docs:
content_item = {
"type": doc.metadata.get("type"),
"content": doc.page_content,
"metadata": doc.metadata
}
if doc.metadata.get("image_path"):
content_item["path"] = doc.metadata["image_path"]
if doc.metadata.get("audio_url"):
content_item["audio_url"] = doc.metadata["audio_url"]
retrieved_multimodal_content.append(content_item)
return retrieved_multimodal_content
db = Chroma(embedding_functinotallow=query_embeddings_model, persist_directory="./multimodal_chroma_db")
user_query = "Explain the neural network architecture shown in the diagram and its audio properties."
retrieved_info = retrieve_multimodal_chunks(user_query, db)
print(f"Retrieved {len(retrieved_info)} relevant chunks.")
for item in retrieved_info:
print(f"Type: {item['type']}, Content (excerpt): {item['content'][:100]}..., Path/URL: {item.get('path') or item.get('audio_url')}")步骤6:多模态LLM整合(使用Gemini)
最后,将检索到的多模态块传递给Gemini进行推理和生成。
- Gemini可以直接接受文本字符串列表和PIL图像对象。对于音频,你需要提供从相关音频片段转录的文本。
- 构建一个包含用户查询和检索到的内容的提示。
- 如果LLM不直接支持多模态输入,你需要将所有检索到的模态转换为文本(例如,图像字幕、音频转录、表格摘要),然后仅将文本传递给LLM。之后,你需要明确指示LLM在其响应中引用原始资源(通过路径/URL)。Gemini支持直接多模态输入,因此无需进行此操作。
import google.generativeai as genai
from PIL import Image
# 配置Gemini
genai.configure(api_key="YOUR_GEMINI_API_KEY")
async def generate_response_with_gemini_multimodal(user_query, retrieved_multimodal_content):
model = genai.GenerativeModel('gemini-pro-vision')
prompt_parts = [
f"User's question: {user_query}\n\n",
"Here is some relevant information from my knowledge base:\n\n"
]
for item in retrieved_multimodal_content:
if item["type"] in ["text", "table_text", "audio_text"]:
prompt_parts.append(f"<{item['type']}_chunk>\n{item['content']}\n</{item['type']}_chunk>\n\n")
elif item["type"] == "image" and item.get("path"):
try:
image_pil = Image.open(item["path"])
prompt_parts.append(image_pil)
prompt_parts.append(f"\nDescription of image from knowledge base: {item['content']}\n\n")
except Exception as e:
print(f"Warning: Could not load image {item['path']} for prompt: {e}")
prompt_parts.append(f"[Image content at {item['path']} could not be loaded. Description: {item['content']}]\n\n")
if item.get("audio_url"):
prompt_parts.append(f"(Associated audio clip: {item['audio_url']})\n\n")
prompt_parts.append("Please provide a comprehensive answer to the user's question based on the provided information, referencing details from the text, images, and audio if relevant.")
try:
response = await model.generate_content(prompt_parts)
return response.text
except Exception as e:
print(f"Error generating content with Gemini: {e}")
return "Sorry, I could not generate a response at this time."
import asyncio
async def main_generation():
final_answer = await generate_response_with_gemini_multimodal(user_query, retrieved_info)
print("\n--- Final Answer from LLM ---")
print(final_answer)
asyncio.run(main_generation())评估指标
评估多模态LLM RAG应用程序是一项复杂的任务,因为你需要评估多个维度的性能:检索质量、生成质量;其中至关重要的是,系统集成和利用所有模态的程度。
以下是评估指标的详细介绍,为了清晰起见进行了分类:
Ⅰ、检索指标
这些指标评估你的系统根据查询检索相关多模态文档或块的效果。这里的挑战在于,当查询可能是多模态的,并且检索到的项目也是多模态时,如何定义“相关性”。
A.核心检索指标:
这些是标准的IR指标,但经过调整以考虑检索到的多模态块的类型和相关性。
- Precision@k:在检索到的排名靠前的词块中k,有多少真正与查询相关?如果检索到的词块的文本、图像或音频内容有助于回答查询,那么该词块就可能是相关的。你需要人工标注人员来标记不同模态下的相关性。例如:对于“展示狗狗在水中玩耍”的题目,如果检索到的前三个词块分别是一张狗狗游泳的图片、一段关于宠物水上安全的文字以及一段泼水的音频片段,你需要评估每个词块的相关性。
- Recall@k:在知识库中所有真正相关的词块中,有多少个词块被检索到排名靠前k?需要对给定查询的所有相关多模态词块进行全面的基本事实评估。创建起来颇具挑战性。
- F1-Score:准确率和召回率的调和平均值。
- 平均准确率(MAP):这是一种流行的指标,它考虑了相关文档的顺序。如果一个高度相关的文档被较早地检索到,那么它的得分就会更高。
- 归一化折扣累积增益(NDCG@k):比MAP更复杂。它会根据相关性分配不同的分数(例如,0=不相关,1=比较相关,2=高度相关),并根据位置降低相关性。例如,如果一张图片比较相关,但其附带的文本描述高度相关,则可以给予部分评分。
B.特定模态检索相关性:
文本生成评估
这些指标评估LLM生成的自然语言响应的质量,通常通过将其与参考(基本事实)答案进行比较来评估。
- 精确匹配(EM):二进制指标,指示生成的答案是否与参考答案完全匹配。简单但严格。适用于答案非常精确的事实类问题。在RAG中,它指示LLM是否正确提取并格式化了精确信息。局限性:如果措辞不同但含义相同,则无法捕捉语义相似性。
- BLEU(双语评估测试):比较生成文本和参考文本的n-gram(词序列)。分数越高,重叠度和相似度越高。适合评估流畅度以及生成的答案如何从相关检索内容中捕捉关键短语。局限性:主要关注词汇重叠,语义意义关注较少。
- ROUGE(面向召回率的摘要评估):一组指标(ROUGE-N、ROUGE-L、ROUGE-S),用于衡量n-gram、最长公共子序列或跳跃二元模型的重叠度,通常侧重于召回率(生成的文本覆盖了多少参考内容)。这对于摘要任务或预期生成的答案涵盖检索到的文档中的广泛事实时特别有用。MultiRAGen使用多语言ROUGE:这对于多语言RAG系统至关重要。它扩展了ROUGE,使其能够比较不同语言的文本或评估跨语言摘要,确保无论生成语言如何,语义内容都能得到保留。
- METEOR(具有明确排序的翻译评估指标):除了n-gram重叠度之外,METEOR还融合了同义词、词干提取和释义,并考虑了词序。与BLEU或ROUGE相比,它能够提供更稳健的语义相似度和流畅度评估。
多模态输出评估(针对特定模态的输出)
虽然你的主要LLM输出可能是文本,但如果多模态LLM生成图像或音频(例如,图像字幕、从文本生成声音),这些指标就会变得相关。
对于图像字幕(例如,当大型语言模型从图像生成字幕时):
- CIDEr(基于共识的图像描述评估):衡量生成的标题与一组人工参考标题之间的相似度。它使用TF-IDF(词频-逆文档频率)对n-gram进行加权,赋予稀有但重要的词汇更高的权重。如果你的MLLM是生成检索到的图像描述的系统的一部分,CIDEr可以帮助评估这些描述的质量。
- SPICE(语义命题图像标题评估):专注于标题的语义内容。它将标题解析为语义“场景图”(对象、属性、关系),并对这些图进行比较。这对于确保LLM的标题能够正确识别和关联视觉元素至关重要,这对于实现准确的多模态理解至关重要。
- SPIDEr(结合两种指标):通常是图像字幕任务的首选指标,因为它平衡了词汇重叠(CIDEr)和语义准确性(SPICE)。
语义对齐/跨模态一致性
这些指标评估在检索和推理过程中不同模态(例如文本和图像、文本和音频)之间的相互理解程度。
- BERTScore:比较生成文本与参考文本/检索内容的语境化嵌入(来自BERT或类似模型)。它本质上衡量语义相似度。非常适合评估生成响应的流畅性和语义质量。此外,它还可用于评估文本查询与检索到的多模态块的文本成分(转录、描述)之间的语义重叠度。它会匹配候选句子和参考句子中的单词,计算它们在BERT嵌入之间的余弦相似度,然后根据这些相似度计算准确率、召回率和F1。
- CLIP评分:使用CLIP(对比语言-图像预训练)模型的嵌入来测量图像与文本描述之间的语义相似度。
a.检索:评估检索到的图像在语义上与文本查询的匹配程度,反之亦然。
b.生成:如果你的MLLM生成图像描述,CLIP评分会评估这些描述与图像本身在语义上的对齐程度。它是图文对应关系的有力指标。
图像质量(如果LLM直接生成或处理图像)
这些指标关注生成或处理的图像的感知质量和多样性。
- FID(Fréchet Inception Distance):使用从预训练的Inception-v3网络中提取的特征,量化生成图像与真实图像的特征分布之间的相似性。FID分数越低,表示质量越高,与真实图像的相似度也越高。如果你的MLLM具有生成图像的能力(例如,根据检索到的文本描述生成图像),FID会评估这些生成图像的真实度。
- KID(Kernel Inception Distance:核初始距离):提供一种比FID更无偏且更鲁棒的替代方案,在Inception特征上使用多项式核。不易出现模式崩溃问题。与FID类似,用于评估生成图像的感知质量。
- 初始分数(IS):通过测量生成图像的条件类别分布与边缘类别分布之间的KL散度来评估图像的多样性和质量。它使用预先训练的初始模型对图像进行分类。IS值越高,质量越高(图像可分类)和多样性越高(图像属于不同的类别)。
这是为了确保生成的图像既逼真又多样化。
音频评估(如果LLM直接处理或生成音频)
这些指标评估音频的质量和相关性。
- 人工标注的声音质量(OVL-整体质量水平)和文本相关性(REL-与文本的相关性):人工主观评估。OVL评估声音的感知质量(清晰度、无噪点、自然度)。REL评估音频内容与给定文本(例如,查询或生成的转录)的对应程度。这对于真正理解音频的用户体验至关重要,因为自动化指标可能会忽略细微差别。在RAG中,你可以使用OVL来确保检索到的音频足够清晰,以便LLM进行处理,并使用REL来确保音频内容在语义上与文本上下文一致。
- Fréchet音频距离(FAD):FID的一种音频专用变体。它使用从预训练音频分类模型(例如VGGish)中提取的特征,量化生成的音频样本与真实音频样本的特征分布之间的相似性。FAD值越低,表示质量越高,与真实音频的相似度也越高。如果你的MLLM生成音频,FAD会评估生成音频的真实度和质量。
Ⅱ、生成指标
这些指标重点关注生成的答案的质量及其与检索到的上下文的关系,特别考虑到信息的多模态性质。
- 正确性:这是最直接也是最关键的指标。它评估LLM生成的答案是否在事实上准确,并针对用户的查询提供了正确的信息。在多模态RAG设置中,“正确性”意味着答案能够准确反映检索到的块(文本、图像、音频转录)的任何模态中的信息。例如,如果用户问“汽车是什么颜色的?”,而检索到的图像清晰地显示了一辆红色汽车,则正确答案是“红色”。如果音频片段确认了日期,则答案应该反映该日期。
- 相关性:这评估生成的答案是否直接解答了用户的问题,并提供了实用且相关的信息,同时不包含多余或偏离主题的细节。答案的相关性是根据用户的多模态意图来判断的。如果用户提供了一张图片并询问其中的特定对象,则答案必须与该对象相关,并充分利用视觉信息和文本查询。
- 文本忠实度:这评估生成的答案是否完全基于检索到的语块文本部分中的信息并与其保持一致。它旨在防止出现“幻觉”或编造文本来源中不存在的信息。在多模态RAG系统中,此指标专门用于区分文本的忠实度。它有助于确定LLM是否正确地从文本段落(例如,从转录的音频、文档文本、表格摘要)中提取和总结信息。如果文本内容为“猫坐在垫子上”,而LLM内容为“猫坐在床上”,则不符合文本忠实度。
- 图像忠实度:评估生成的答案是否与检索到的图像中呈现的信息有事实依据且一致。它确保LLM不会误解或对视觉内容的细节产生幻觉。这对于多模态RAG至关重要。如果检索到的图像显示“一只蓝色的鸟”,但LLM却显示“一只绿色的鸟”,则图像忠实度不合格。它直接考验LLM准确感知和使用视觉信息的能力。
- 文本上下文相关性:这评估检索到的文本块(包括转录的音频和表格摘要)与用户查询的相关程度。它是衡量检索组件对文本源的准确性的指标。虽然用户的查询可能是多模态的(例如,文本+图像),但此指标专门检查系统是否提取了对答案有用的正确文本文档或块。如果文本块描述的是“水泵”,而查询是关于“水龙头”的,则相关性较低。
- 图像上下文相关性:这评估检索到的图像块与用户查询的相关程度。
如果用户查询“自行车齿轮”,系统检索到一张自行车轮胎的图像,则图像上下文相关性较低。如果检索到一张变速器的详细图表,则相关性较高。这时,图像的多模态嵌入(例如,通过Gemini或CLIP)就至关重要。
Ⅲ、系统级/端到端指标
这一部分指标评估了整个RAG系统的整体用户体验和性能。
- 响应时间(延迟):系统多快提供答案?(多模态处理可能更加密集)。
- 鲁棒性:系统如何处理嘈杂的输入(模糊的图像、低沉的音频)、模糊的查询或缺失的模态?
- 用户满意度:最终指标,通常通过调查或隐性反馈(例如,重新查询率)收集。
- 成本效益:运行多模态编码器、嵌入和LLM推理的计算成本。
Ⅳ、评估方法
- 人工评估(黄金标准):对于多模态连贯性、忠实度和整合质量等细微方面,人工注释者通常不可或缺。他们可以评估相关性、正确性和整体答案质量。
- LLM-as-a-Judge:使用强大的LLM,根据预定义标准和检索到的上下文来评估RAG系统的响应。这可以自动化某些人工评估环节,但需要谨慎、及时的工程设计。
- 定量基准:对于检索而言,创建包含多模态查询和严格标注的相关多模态文档的数据集至关重要。对于生成而言,创建用于比较的黄金标准答案至关重要。
- A/B测试:对于实际应用,通过将不同的RAG策略或模型部署到不同的用户组并测量参与度、任务完成率或用户满意度来比较它们。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。原文标题:Enhancing LLM Capabilities: The Power of Multimodal LLMs and RAG,作者:Sunil Rao


