当AI大模型越来越“吃”硬件,把内存、算力、带宽逼到极限,追赶者们,或者说整个行业,除了干等硬件升级,还能怎么办?
ChatGPT横空出世,大模型竞赛白热化。英伟达的GPU成了硬通货,算力就是一切。各大公司和研究机构疯狂堆砌资源,试图追赶甚至超越。
但到了2024、2025年,大家发现,硬件的升级速度,似乎有点跟不上模型的膨胀速度了。内存墙、功耗墙、带宽墙,每一堵都让人头疼。
Deepseek,一家围绕“现有硬件的极限优化”和“软硬件协同设计”,对抗“暴力堆料”的领先者,最近发布了一篇关于DeepSeek-V3的论文。
 论文由梁文锋署名
论文由梁文锋署名
论文标题翻译成中文是《洞察DeepSeek-V3:规模化挑战与AI架构硬件的思考》,主要展示了如何在内存、计算和互联带宽都受限的情况下,通过硬件感知的模型协同设计,实现高性价比的大规模训练和推理。
那些信奉“完美硬件”或者试图用“无限金钱”抹平一切技术挑战的思路,可能在DeepSeek-V3这样的实践面前,显得不那么“经济适用”了。
DeepSeek-V3的“武功秘籍”主要有这么几招:
多头隐注意力 (MLA)——提升内存效率
大幅压缩KV缓存,解决内存瓶颈。别人还在愁显存不够用的时候,DeepSeek-V3通过MLA技术,让每个token的KV缓存低至70KB,比LLaMA-3.1 405B(516KB)和Qwen-2.5 72B(327KB)少得多。这相当于,在有限的“土地”上种出了更多的“粮食”。
专家混合 (MoE) 架构优化——优化计算与通信平衡
在扩大模型总参数量的同时,只激活一小部分专家参数进行计算。DeepSeek-V3有6710亿参数,但每个token只激活370亿。这既保证了模型的“大块头”,又控制了实际运算的“饭量”,实现了计算和通信的更优平衡。
FP8混合精度训练——充分释放硬件潜能
大胆采用更低精度的FP8进行训练,进一步降低了计算和内存开销。同时,通过细粒度的量化和高精度累加等技术,把精度损失控制在极小范围。这要求硬件对低精度计算有更好的支持,论文也对此提出了明确的建议。
多平面网络拓扑——最小化集群网络开销
针对大规模集群的网络开销问题,设计了多平面胖树网络,用两层胖树实现了传统三层胖树的扩展能力,同时降低了成本和延迟。
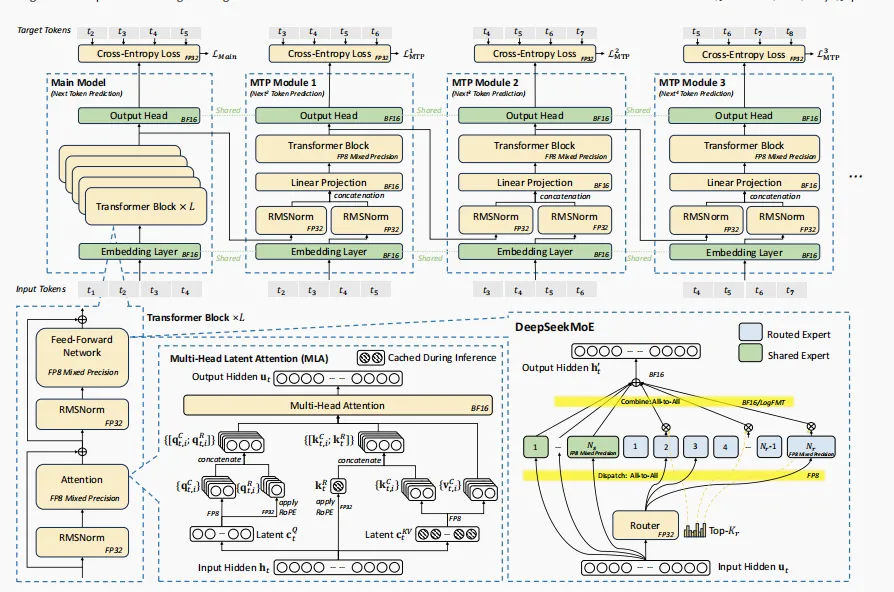 图片
图片
图注:DeepSeek-V3 的基础架构。在 DeepSeek-V2 的 MLA 和 DeepSeekMoE 基础上,DeepSeek-V3 引入了多Token预测模块(Multi-Token Prediction Module)以及 FP8 混合精度训练
DeepSeek-V3的这些创新,很多都是在现有硬件的“条条框框”里“憋”出来的。比如,H800的NVLink带宽相较H100有所缩减,他们就强化了Pipeline并行和Expert并行,并针对性地设计了“节点限制路由”策略,优先利用节点内的高带宽。 这就像一位经验丰富的大厨,手头只有普通的食材,却能烹饪出令人惊艳的菜肴。
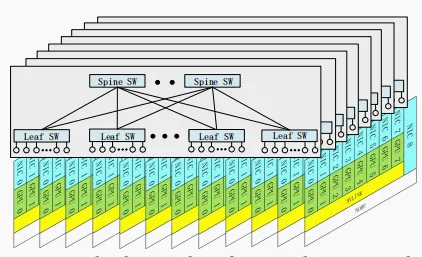 图片
图片
图注:八平面两层胖树扩展网络结构。每个 GPU 与 IB 网卡(NIC)配对后,归属于一个网络平面。跨平面流量必须通过另一张网卡,并借助 PCIe 或 NVLink 在节点内部进行转发。
训练DeepSeek-V3的成本虽然没有具体公布,但其明确强调了“高性价比”。 论文中提到,MoE模型的计算成本远低于同等激活参数量的密集模型,DeepSeek-V3每token的训练计算成本约为250 GFLOPS,而参数量小得多的Qwen-72B(密集模型)则需要394 GFLOPS。
“改变AI硬件的设计思路”
作为基础设施,大模型的底层硬件架构很大程度上决定了其效率和成本。DeepSeek-V3的实践,不仅是模型设计的胜利,更是对未来AI硬件设计方向的深刻反思和具体建议。
论文花了大量篇幅,从DeepSeek-V3开发中遇到的硬件瓶颈出发,向硬件厂商提出了改进建议:
- 低精度计算单元要更“精准”:比如FP8累加精度要够,要原生支持细粒度量化。
- 内外互联要“融合”:别让CPU和GPU之间、节点内外之间的数据搬运那么费劲,要统一管理,减少软件复杂度和资源浪费。
- 网络要“智能”且“低延迟”:无论是IB还是RoCE,都要优化路由、拥塞控制,并且最好能原生支持一些通信压缩和网络内计算。
- 系统鲁棒性要加强:别动不动就因为硬件小毛病导致训练中断。
这几乎是在说:“硬件大佬们,请看看我们应用端的需求吧!我们需要的是能更好配合我们的硬件,而不仅仅是更高频率、更大显存的‘傻大个’。”
就像当年Android通过开源团结了众多手机厂商对抗iOS的封闭生态一样,DeepSeek-V3所代表的这种通过极致的软硬件协同设计来对抗单纯的硬件军备竞赛的思路,也可能为AI领域带来新的竞争格局。 它不是直接提供一个“开源平替”,而是提供了一种“更聪明的追赶方式”。
在这种新的竞争态势下,即使是硬件领先者,也需要思考如何让自己的产品更好地被“用尽潜能”。 论文中对未来硬件的展望,如内存语义通信、网络内计算、DRAM堆叠加速器等,都指向了一个趋势:未来的AI系统,一定是软硬件高度协同、深度优化的产物。
论文地址:https://arxiv.org/pdf/2505.09343


